Clean Code Principles
Guidelines and techniques for writing maintainable, readable, and efficient code following established clean code principles serve as foundational knowledge for software professionals seeking to create high-quality applications that can evolve over time. Clean code practices emphasize self-documenting code through meaningful variable and function names, allowing developers to understand the purpose and behavior of code without extensive comments or documentation. Effective code organization follows the single responsibility principle, ensuring that functions and classes have one clearly defined purpose, which leads to more modular, testable, and reusable components that can be maintained independently. Professional developers recognize that code is read far more often than it is written, making readability a critical factor that impacts long-term maintenance costs and team productivity more than clever optimizations or brevity. Consistent formatting and adherence to language-specific style guides eliminate cognitive overhead when switching between different parts of a codebase, with automated tools like linters and formatters enforcing these standards to prevent stylistic debates and maintain quality across teams of varying experience levels. The DRY (Don't Repeat Yourself) principle guides developers to abstract common functionality instead of duplicating code, reducing the risk of inconsistent behavior when requirements change and minimizing the surface area for potential bugs. Comprehensive test coverage, including unit, integration, and end-to-end tests, not only verifies correctness but serves as living documentation that demonstrates how code is intended to be used and provides confidence when refactoring or extending functionality.
7 Common Software Development Mistakes Revealed by AI-Generated Bug Reports

In the evolving landscape of software development, one of the most significant challenges developers face is dealing with misleading bug reports. This...
GitHub SpecKit: The Revolutionary Tool That Fixes AI Coding Problems

Think about the last time you asked an AI tool to write code. It probably gave you something that looked correct but didn't quite work. This common fr...
How GPT-5 Codex Is Revolutionizing AI-Powered Coding Automation

The landscape of software development is undergoing a profound transformation with the emergence of sophisticated AI coding assistants. OpenAI's lates...
How Codex Framework Transforms Developer Workflows: A Comprehensive Guide

The software development landscape is constantly evolving, with new tools and frameworks emerging to streamline workflows and boost productivity. Amon...
RubyMine Now Free for Non-Commercial Use: Boost Your Ruby Development

Ruby has long been celebrated for its developer-friendly approach, with a syntax and philosophy designed to make programming enjoyable. However, as an...
GPT-5 Model: How This AI Revolution is Transforming Business Workflows

The emergence of the GPT-5 model represents what many experts are calling the beginning of a second computing revolution. This next-generation AI syst...
How AI and RubyMine Transform Ruby Coding: Free for Non-Commercial Use

The world of Ruby development is experiencing a revolutionary transformation thanks to the integration of artificial intelligence. Developers are disc...
Sonic AI Model Review: Is This Coding Assistant Better Than Claude Sonnet 4?

A new AI model called Sonic has been stealth-released and is making waves in the developer community. This model, available for a limited time on plat...
7 Essential Claude Code Features Every Developer Should Know
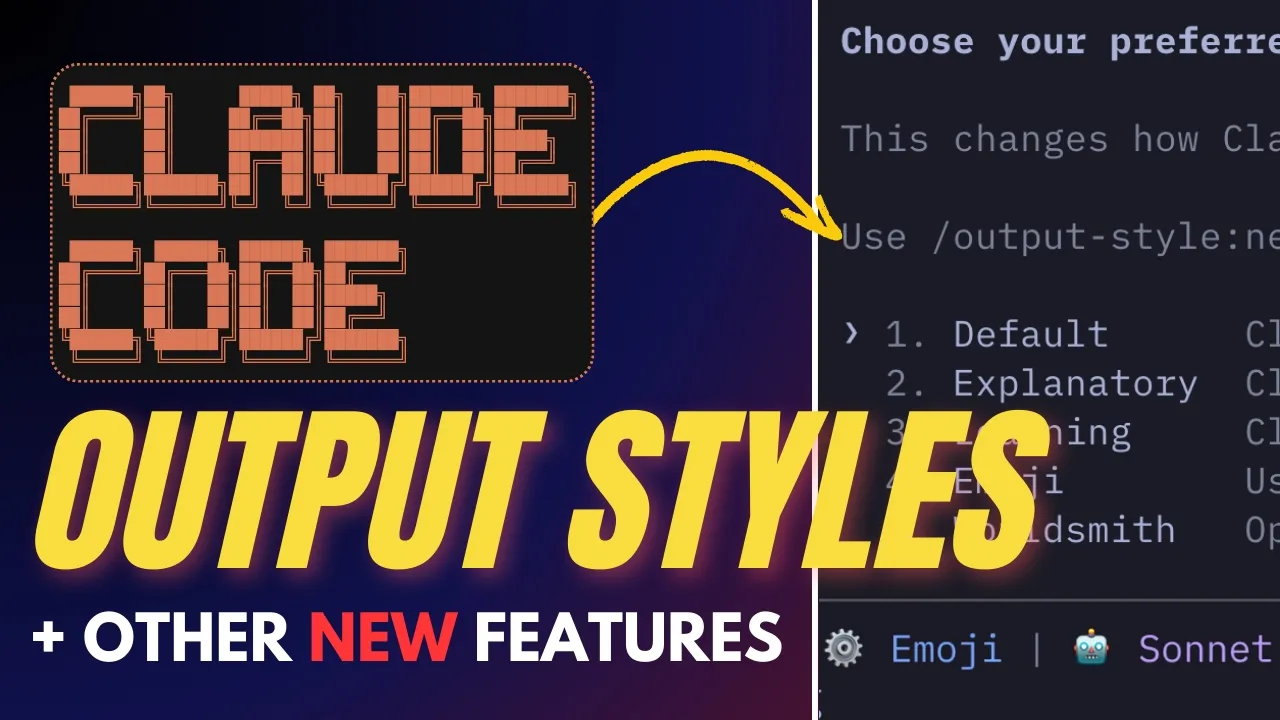
Claude Code AI is rapidly becoming the preferred coding assistant for both developers and non-developers alike. With its powerful AI capabilities, Cla...