How Amazon S3 Achieves 99.999999999% Durability: The Engineering Behind 11 9s
Jamal Washington
Infrastructure Lead
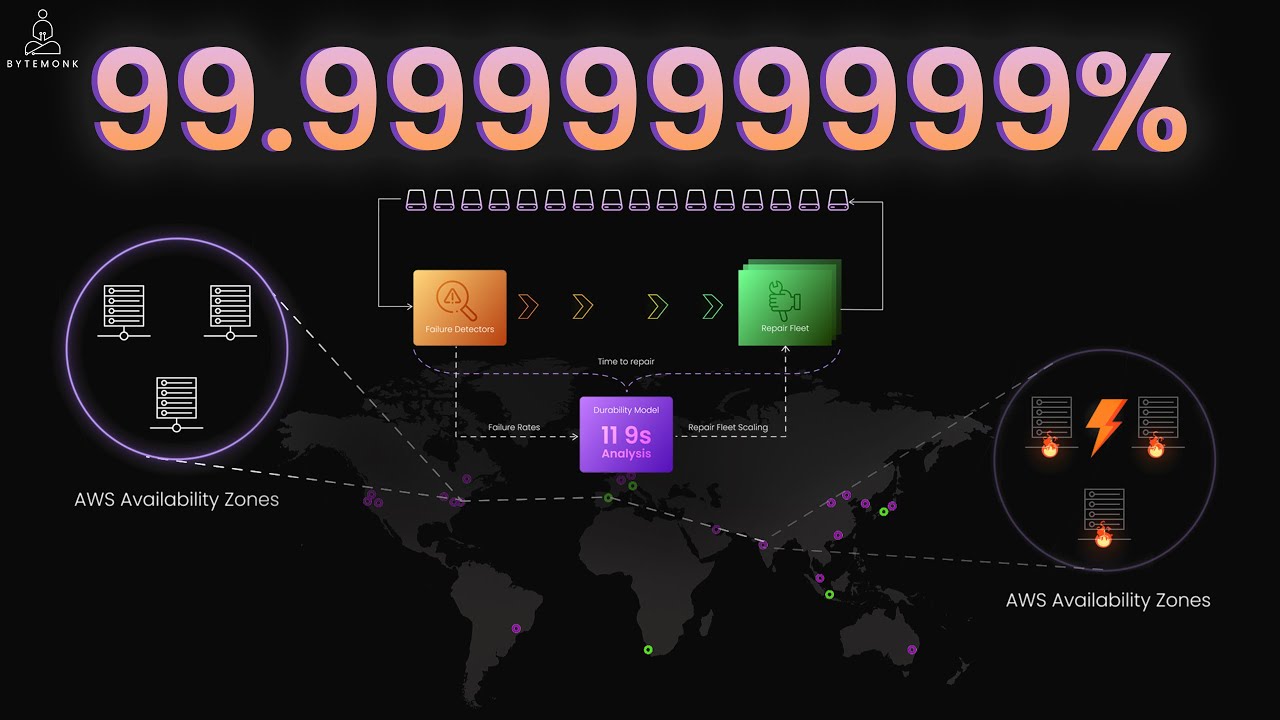
Imagine waking up to find your company's storage server crashed, with years of critical data suddenly gone. This nightmare scenario is exactly what Amazon S3 (Simple Storage Service) is engineered to prevent. With an almost unbelievable 99.999999999% durability guarantee—that's 11 nines—S3 has become the gold standard for reliable cloud storage. But what does this level of durability actually mean, and how does Amazon achieve it?
To put this in perspective: if you stored 10,000 files in S3, you might expect to lose just one file every 10 million years. Before we dive into the engineering behind this remarkable achievement, let's clarify what durability actually means in the context of cloud storage.
Understanding Durability vs. Availability
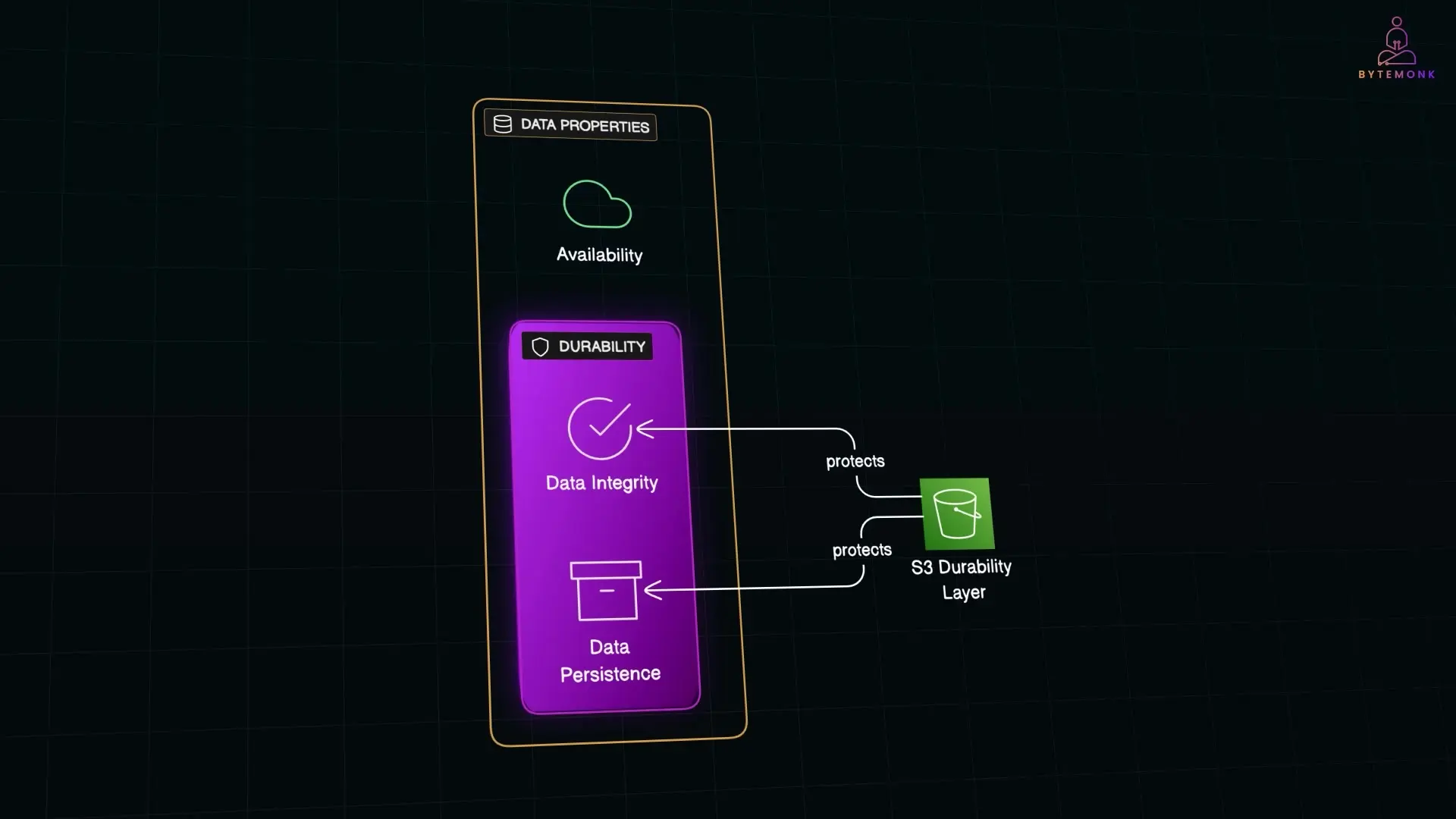
Durability and availability are often confused but represent fundamentally different aspects of a storage system:
- Availability refers to how reliably you can access your data when needed—essentially, whether the service is up and running
- Durability refers to the probability that your data will be preserved without corruption or loss over time—even if hardware fails or disasters occur
While S3 offers impressive availability (99.99% for standard storage), its durability guarantee is what truly sets it apart. Now, let's explore the sophisticated engineering strategies that make this possible.
Core Engineering Principle: Don't Put All Your Eggs in One Basket

At the foundation of S3's durability strategy is a simple principle: distribute data widely to minimize risk. When you upload a file to S3, it's instantly replicated across multiple physical devices. This isn't just basic backup—it's a sophisticated distribution system that spans multiple servers across different Availability Zones (AZs).
These Availability Zones are separate data centers, each with independent power, networking, and cooling systems, often located miles apart. This means that even if an entire data center experiences a catastrophic failure—whether from power outage, networking issues, or natural disaster—your data remains safe and accessible from other locations.
Erasure Coding: Beyond Simple Replication
S3 goes beyond simple replication with a sophisticated technique called erasure coding. This method provides superior data protection while being more storage-efficient than creating multiple complete copies.
Here's how erasure coding works in S3:
- Your data is broken down into multiple pieces called "data shards"
- Additional "parity shards" are created using mathematical algorithms
- These shards are distributed across different storage devices, racks, and data centers
- Even if several shards become corrupted or unavailable, the original data can be reconstructed from the remaining pieces
This approach is similar to RAID technology but implemented at cloud scale—spanning not just multiple disks but entire buildings. The mathematical properties of erasure coding ensure that even if multiple components fail simultaneously, data integrity remains intact.
Proactive Monitoring and Rapid Recovery
At Amazon's scale, hardware failures are not just possible—they're inevitable. Hard drives fail daily, which is why S3's durability strategy includes sophisticated monitoring and rapid recovery systems.
S3 constantly monitors the health of every storage device, tracking metrics like read/write errors, temperature, and disk wear levels. When anomalies are detected, automated systems immediately:
- Mark problematic disks for maintenance
- Pull data from healthy replicas
- Begin reconstructing data onto new devices
- Distribute recovery workloads across multiple systems to minimize impact
What makes this process particularly effective is that S3 deliberately maintains spare capacity across its infrastructure. When failures occur, recovery processes can leverage this distributed spare capacity, with many disks each handling a small portion of the recovery workload. This approach ensures that recovery speed stays ahead of failure rates—a critical factor in maintaining 11 nines of durability.
Data Integrity Verification Through Checksums
To protect against silent data corruption—where bits might flip or data might become corrupted without obvious errors—S3 implements rigorous checksum verification throughout the data lifecycle.
When you upload a file to S3, the system generates a unique checksum—essentially a digital fingerprint of your data. This checksum is stored alongside the data and used to verify integrity at multiple points:
- During initial storage to confirm successful write operations
- During routine background scans that continuously audit stored data
- When data is accessed or retrieved
- During data migration or recovery operations
If a checksum verification fails—indicating that data has changed unexpectedly—S3 automatically repairs the affected data by retrieving a healthy copy from another location. This constant verification and repair process happens silently in the background, ensuring data integrity without requiring any user intervention.
Architecture: Separation of Metadata and Data
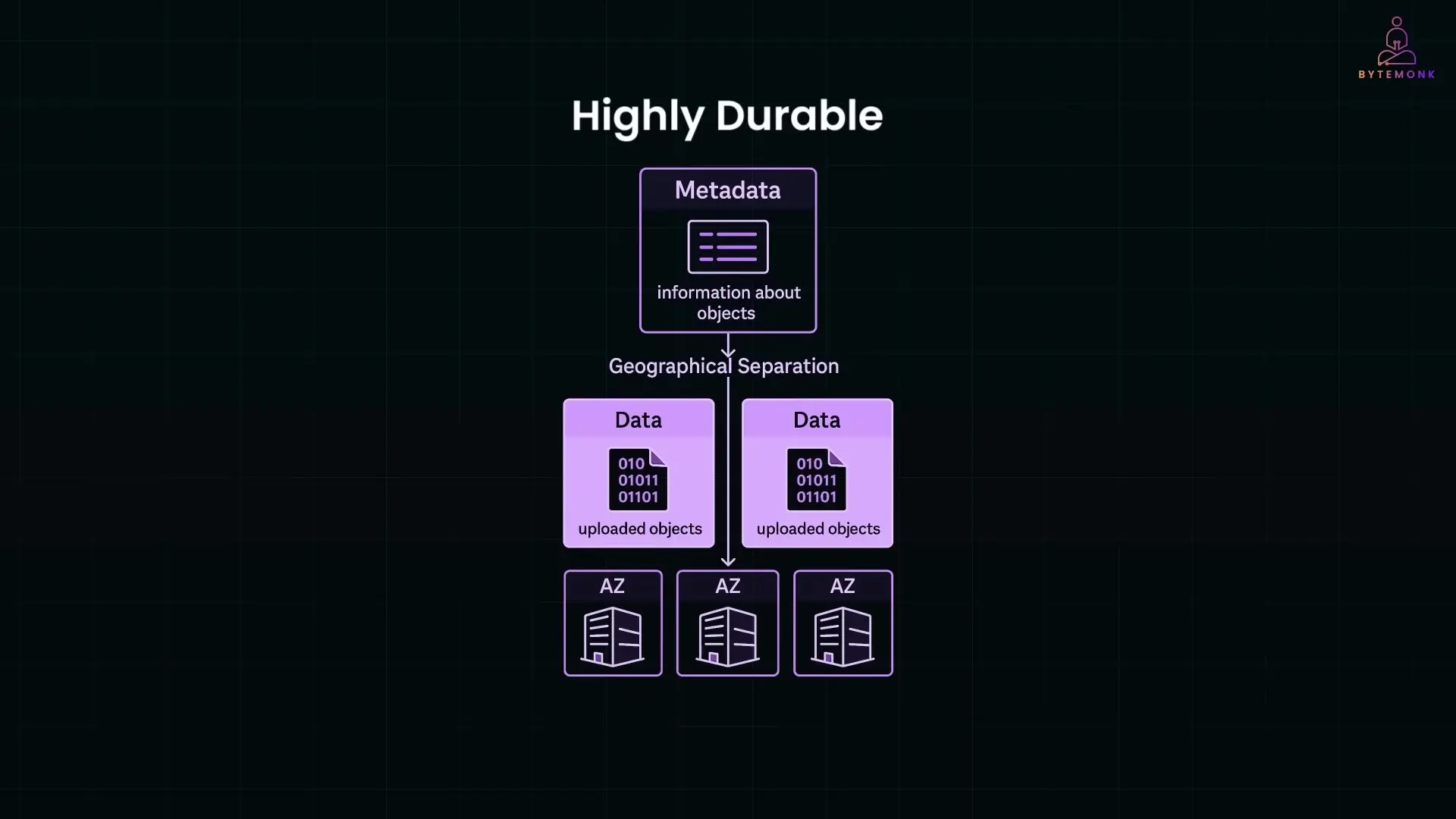
A key architectural decision in S3's design is the separation of metadata (information about your files) from the actual data itself. This separation provides both performance and durability benefits:
- Metadata (file names, sizes, timestamps, permissions) is stored in a highly durable distributed system optimized for fast lookups
- Actual object data is stored in massive storage clusters optimized for throughput and durability
- Each system can be scaled and optimized independently
- Issues in one system don't necessarily affect the other
This architecture enables S3 to provide both rapid metadata operations (like listing files) while maintaining extreme durability for the actual data content. It's another example of how specialized engineering decisions contribute to the overall durability guarantee.
Protection Against Human Error
Not all data loss comes from hardware failures or natural disasters—human error is often the culprit. S3 includes several features specifically designed to protect against accidental deletion or modification:
- Versioning: When enabled, S3 preserves previous versions of objects when they're updated or deleted, allowing you to recover from accidental changes
- Object Lock: Allows you to make objects completely undeletable for a set period, even by administrators
- Cross-Region Replication: Automatically copies data to a completely different geographic region for additional protection
- MFA Delete: Requires multi-factor authentication for certain deletion operations
These features recognize that durability isn't just about hardware resilience—it's about protecting data from all threats, including ourselves.
The Bracketing Process: Verify Before Confirming
One of S3's more subtle but powerful durability mechanisms is a process called "bracketing." When you upload a file to S3, the system doesn't immediately report success. Instead, it performs an additional verification step:
- Data is written to storage and distributed across systems
- S3 attempts to read back and reconstruct the original data from the stored shards
- Only if this reconstruction succeeds does S3 confirm the upload as successful
This extra verification step ensures that data isn't just stored but is actually recoverable from the distributed storage system. It's an additional safeguard that catches potential issues at the earliest possible moment, rather than discovering problems later when data is needed.
Engineering Culture: Durability as a Core Value
Perhaps the most fundamental aspect of S3's durability isn't found in any technical specification but in Amazon's engineering culture. Durability isn't treated as just another feature—it's a core value that influences every decision:
- Every change to S3 undergoes rigorous durability reviews
- Engineers must think through failure scenarios and prove data safety
- Amazon runs constant simulations and pressure tests
- Any potential threat to the 11 nines durability target triggers architectural improvements
This culture resembles the aerospace industry's approach to safety—where failure isn't just inconvenient but potentially catastrophic. By embedding durability into the engineering DNA of S3, Amazon has created a system where data protection is the default, not an afterthought.
Conclusion: Why 11 9s of Durability Matters
Amazon S3's 99.999999999% durability guarantee isn't just a marketing number—it represents layers of sophisticated engineering, redundant systems, and a relentless focus on data protection. For businesses that rely on their data (which is virtually every modern organization), this level of durability provides both practical protection and peace of mind.
The next time you upload something to S3 and take for granted that it will be there tomorrow, remember the complex systems working behind the scenes: the distributed storage, erasure coding, integrity checks, and automated recovery processes all ensuring that your data remains safe for the long haul.
In a world where data is increasingly the lifeblood of organizations, S3's approach to durability sets a standard for what's possible when engineering teams make data protection their highest priority.
Let's Watch!
How Amazon S3 Achieves 11 9s of Durability: Engineering Explained
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence