How Big Tech Companies Validate Usernames in Milliseconds: Advanced System Design Revealed
Marcus Chen
Performance Engineer
When signing up for a new app and receiving the message "This username is already taken," you're experiencing a deceptively complex system at work. Behind this seemingly simple check lies an intricate architecture designed to handle billions of usernames with lightning-fast response times. This article explores the advanced techniques and data structures that companies like Google, Amazon, and Meta use to validate usernames in milliseconds.
The Challenge of Username Validation at Scale
At scale, checking if a username exists can't rely on basic database queries. With billions of users, such an approach would create serious performance issues, high latency, bottlenecks, and unnecessary system load. Tech giants have developed sophisticated solutions that combine various data structures, caching mechanisms, and distributed systems to make these checks incredibly fast and efficient.
Redis Hashmaps: The First Line of Defense
Redis hashmaps are powerful, efficient data structures often used in caching layers. For username lookups, each field in a hashmap can represent a username with its value being something lightweight like a user ID or a placeholder flag.
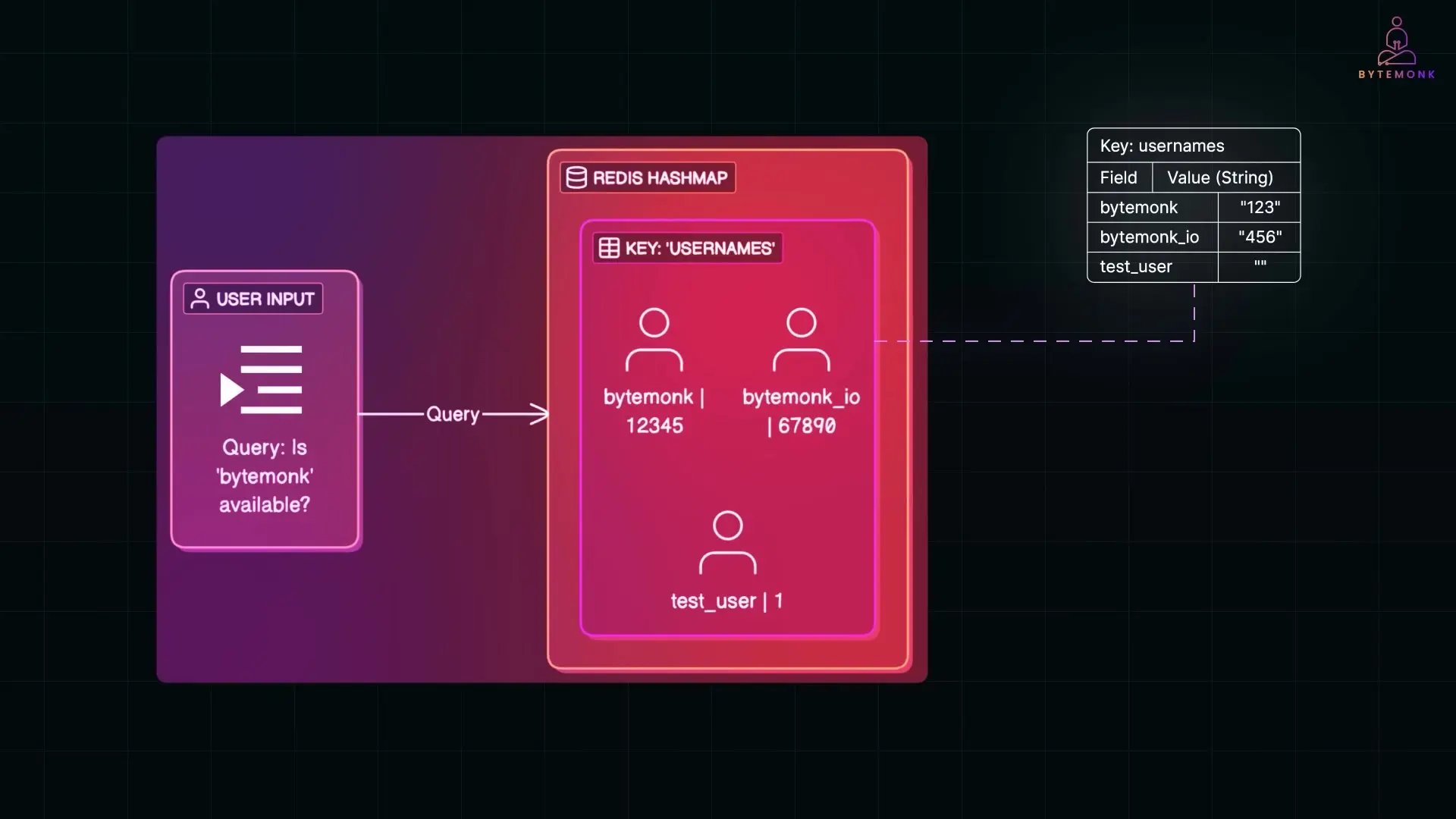
When a user checks if a username is available, the system queries this hashmap. If the username exists in the map, that's a cache hit, and Redis returns a result instantly. This fast in-memory check avoids touching the database for most lookups, dramatically improving response times.
Tries (Prefix Trees): Beyond Simple Lookups
While Redis hashmaps excel at exact match lookups, tries (or prefix trees) offer additional capabilities. A trie is a tree-like structure that organizes strings by their shared prefixes, breaking down usernames character by character to build paths through the tree.
This structure allows for lookups in O(M) time, where M is the length of the string—regardless of how many total usernames exist in the system. Even with billions of entries, checking a single username takes time proportional only to its length, not the size of the entire dataset.
Tries also naturally support prefix-based queries and autocomplete functionality, making them ideal for suggesting alternative usernames when a user's first choice is already taken. Usernames with shared prefixes reuse the same path in the tree, reducing redundancy and saving memory.
B+ Trees: The Database Workhorses
B+ trees and their close cousins B-trees are widely used in relational databases to index fields like usernames. These structures keep keys sorted and allow efficient lookups in O(log n) time. Even with billions of usernames, finding one might take only around 30 steps.
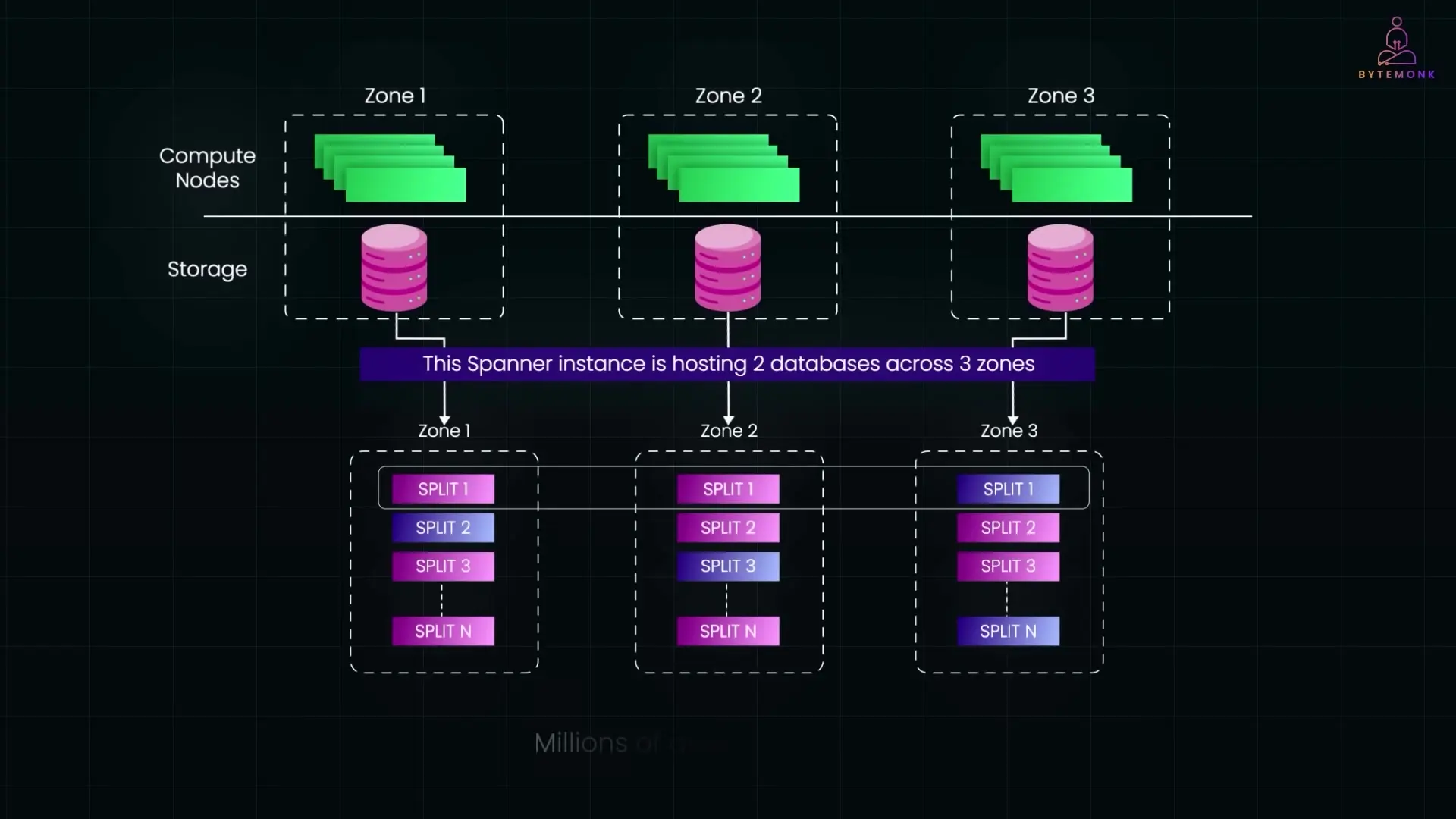
Thanks to their high fan-out (each node can store hundreds of keys), B+ trees stay shallow. In real-world scenarios, you can often search millions of entries with just 3-4 disk or memory reads. They also support range queries, like finding the next available username alphabetically.
B+ trees form the backbone of many databases, from traditional SQL systems to modern NoSQL ones like MongoDB and FoundationDB. For truly massive scale, systems like Google Cloud Spanner distribute a sorted key space backed by B-tree-like structures across multiple machines and replicas, allowing horizontal scaling while maintaining performance.
Bloom Filters: Probabilistic Efficiency
Bloom filters are probabilistic data structures designed to check if an item might be in a set using minimal memory. They consist of a bit array combined with several hash functions. When adding a username, it's hashed multiple times, and each hash sets a corresponding bit in the array.
To check a username, the system hashes it the same way. If any of those bits is zero, the username is definitely not in the set. If all bits are one, then it's probably present, and the system falls back to a more expensive check like a database query.
The power of Bloom filters is that they never give false negatives. If they say a username isn't present, you can trust that result. The only trade-off is the possibility of false positives, which is acceptable when the alternative is querying a massive database.
The space savings are significant—to store 1 billion usernames with a 1% false positive rate requires only about 1.2 GB of memory, a fraction of what storing full keys in a cache would require. This makes Bloom filters an excellent first-pass filter that can dramatically reduce load on downstream systems.
Putting It All Together: The Username Validation Architecture
In real-world large-scale systems, companies rarely rely on just one data structure. Instead, they combine these techniques strategically, layering them to maximize speed, reduce memory usage, and minimize database load.
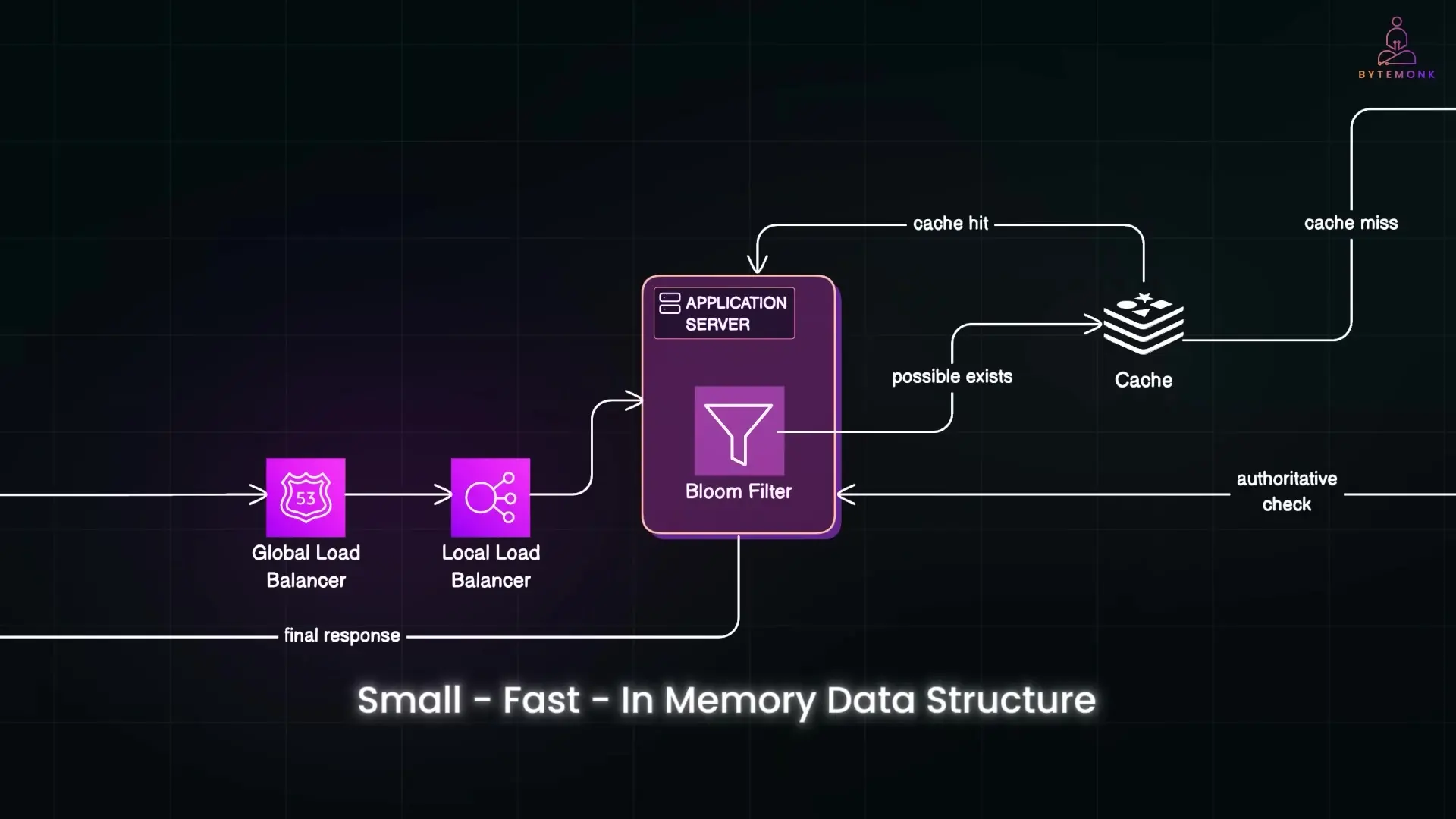
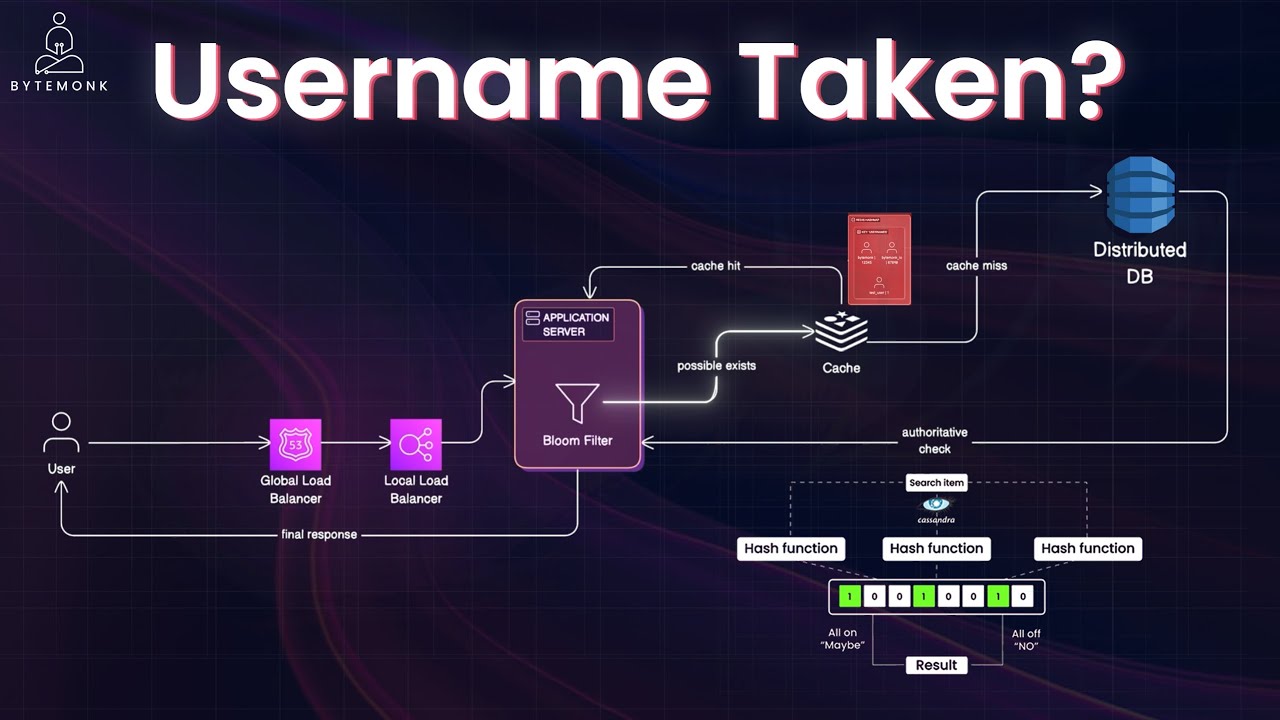
The Username Validation Flow
- A load balancer routes the request to the appropriate regional data center and then to a specific application server
- The request first hits a Bloom filter, which quickly determines if the username definitely doesn't exist
- If the Bloom filter can't rule out the username, the request checks an in-memory cache (Redis or Memcached)
- Only on a cache miss does the system query the distributed database (like Cassandra or DynamoDB)
- The result is returned to the user and often cached for future queries
Load Balancing: Global and Local
Load balancing typically happens at two levels in large distributed systems:
- Global load balancing (edge-level) uses DNS-based or anycast routing to direct user requests to the closest regional data center
- Local load balancing distributes traffic among several backend servers or service instances within a data center
For example, AWS uses Amazon Route 53 for global load balancing, while local load balancing might be handled by NGINX or AWS Elastic Load Balancer (ELB).
Distributed Databases for Ultimate Scale
For the authoritative source of truth, tech giants choose databases designed specifically for scale, such as Apache Cassandra (used by Instagram) or Amazon DynamoDB. These databases distribute data across hundreds or thousands of machines using strategies like consistent hashing, ensuring even load distribution and fast lookups.
Username Validation Best Practices
Based on how big tech companies handle username validation, here are some best practices for implementing efficient username validation in your own systems:
- Use multi-layered validation approaches that combine fast in-memory checks with authoritative database lookups
- Implement caching strategies to minimize database queries for frequently checked usernames
- Consider probabilistic data structures like Bloom filters for initial screening when dealing with large datasets
- Design your database schema and indexes specifically to optimize username lookups
- Implement distributed systems that can scale horizontally as your user base grows
- Use load balancing to distribute validation requests evenly across your infrastructure
Comparison of Data Structures for Username Validation
Here's a comparison of the key data structures used in username validation systems:
- Redis Hashmaps: Excellent for exact lookups, very fast, moderate memory usage, no support for partial matches
- Tries (Prefix Trees): Good for prefix matching and suggestions, moderate speed, can be memory-intensive without compression
- B+ Trees: Ideal for sorted lookups and range queries, good performance for database indexes, moderate memory usage
- Bloom Filters: Extremely memory-efficient, very fast, probabilistic (no false negatives but possible false positives), best as a first-pass filter
Conclusion
The seemingly simple task of checking whether a username is available involves a sophisticated combination of data structures, caching mechanisms, and distributed systems working in concert. By leveraging Bloom filters, in-memory caches, distributed databases, and smart load balancing, companies like Google, Facebook, and Amazon ensure that username validation happens in milliseconds, even with billions of users worldwide.
Understanding these techniques not only provides insight into how large-scale systems operate but also offers valuable lessons for designing efficient validation mechanisms in your own applications. Whether you're building the next social media platform or a modest web application, these principles can help you create faster, more scalable username validation systems.
Let's Watch!
How Big Tech Validates Usernames in Milliseconds: System Design Revealed
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence