Ultimate Vector Database Benchmark: Performance Analysis of 5 Leading Platforms
Sophia Okonkwo
Technical Writer
Vector databases have become a crucial component in modern AI systems, powering everything from semantic search to recommendation engines. But with so many options available, how do you choose the right one for your project? In this comprehensive benchmark, we'll test five leading vector databases head-to-head to determine which one truly delivers the best performance.
Understanding Vector Databases
At their core, vector databases are specialized systems designed to store and search through high-dimensional vectors. Unlike traditional databases that rely on exact matching, vector databases find the nearest neighbors in a multi-dimensional space, making them ideal for semantic search applications.
These databases store numerical representations (embeddings) of data like text, images, or audio. When you search for something, the database doesn't look for exact keyword matches but instead finds items with similar meaning or context.

Meet the Contestants
- Quadrant: Built in Rust for speed and reliability, focused on efficient vector search at scale
- Milvus: One of the earliest open-source vector databases, backed by Zilliz and considered an industry standard
- Weaviate: An open-source database written in Go with a strong focus on knowledge graphs and semantic enrichment
- Pinecone: Built specifically for production-grade vector search with emphasis on consistency and reliability
- TopK: A newer player emphasizing simplicity and fast approximate nearest neighbor search with a developer-friendly approach
Building a Semantic Music Search Engine
For our benchmark, we're building a semantic music search engine that allows users to search for songs using natural language queries. Rather than relying on exact keyword matching, this engine understands the meaning behind queries like "songs about heartbreak" or "I'm feeling sad today" to find contextually relevant results.
We'll use the Musical Sentiment dataset from Hugging Face, which contains tens of thousands of tracks annotated with moods and emotions—perfect for testing semantic search capabilities.

Benchmark Setup and Methodology
Our benchmark methodology involves several key steps:
- Preparing the dataset and generating embeddings using a Hugging Face model
- Ingesting the data into each of the five vector databases
- Measuring ingestion time for each database
- Running queries with different "top K" values (5, 10, 50) to retrieve nearest neighbors
- Measuring queries per second (QPS), latency, and recall accuracy
- Repeating each test five times to smooth out randomness
For four of the databases (Quadrant, Milvus, Weaviate, and Pinecone), we used local Docker containers. TopK was tested through their cloud service since they don't offer a Docker container.
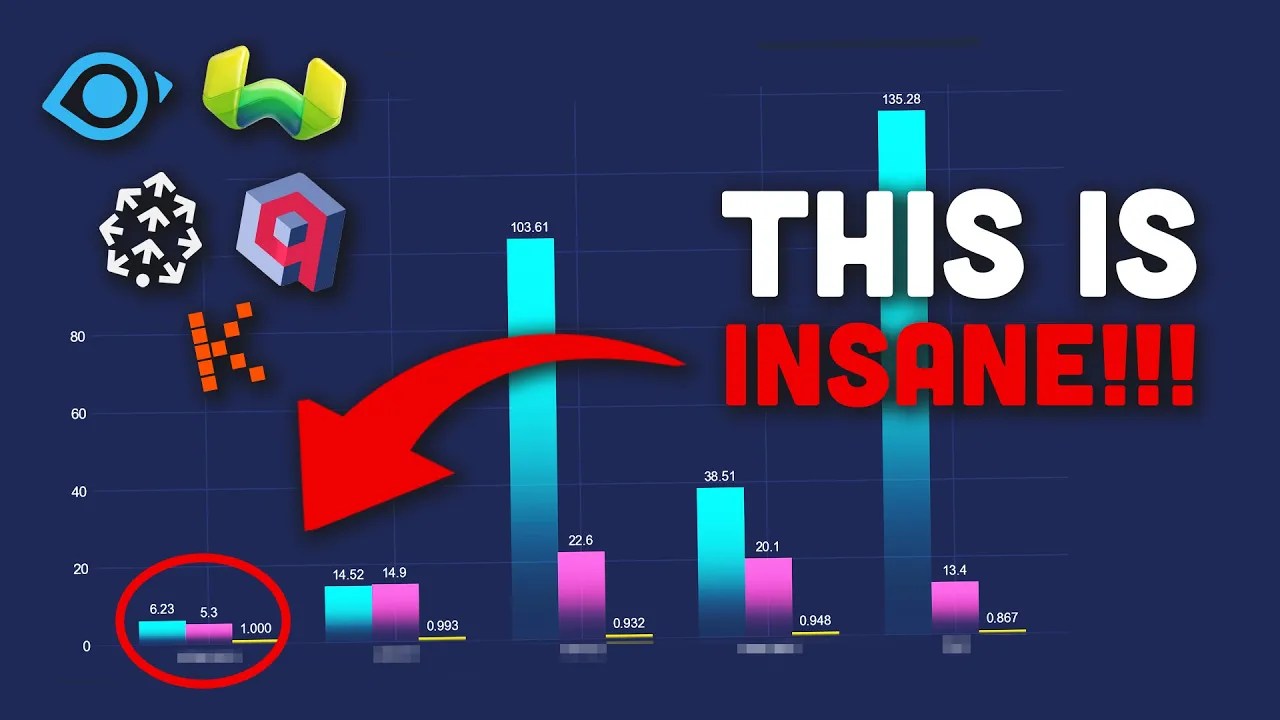
Benchmark Results: Ingestion Time
Ingestion time measures how quickly each database can load and index our dataset. This is particularly important for applications that frequently update their vector indexes.
- Pinecone: 6 seconds (fastest)
- Quadrant: 14 seconds
- Weaviate: 54 seconds
- TopK: 67 seconds (cloud service, network latency factor)
- Milvus: 103 seconds (slowest)
Pinecone absolutely dominated this category, taking just 6 seconds to ingest all the data—more than twice as fast as the runner-up, Quadrant. Milvus, despite its popularity, performed poorly in this test, taking over 100 seconds to complete ingestion.
Benchmark Results: Query Performance (QPS)
Queries per second (QPS) measures how many search operations each database can handle in a given timeframe—a critical metric for high-traffic applications.
In this category, Milvus and Weaviate led the pack with the highest QPS scores. Quadrant and TopK also performed admirably, while Pinecone had the lowest throughput despite its impressive ingestion speed.
Benchmark Results: Recall Accuracy
Recall measures how many correct results the database actually finds—arguably the most important metric for semantic search applications. A perfect score of 1.0 (100%) means the database found all relevant results.
When retrieving the top 50 results, the databases performed as follows:
- Pinecone: 100% recall (perfect score)
- Quadrant: 99% recall
- Weaviate: 97% recall
- Milvus: 96% recall
- TopK: 94% recall
Pinecone achieved a perfect 100% recall score—an impressive feat that demonstrates its focus on result quality over raw speed. Quadrant came in a close second at 99%, while all databases maintained respectable scores above 94%.

Benchmark Results: Latency
Latency measures how quickly each database responds to queries—a critical factor for user-facing applications where response time directly impacts user experience.
Milvus and TopK consistently delivered the lowest latency across all K values (5, 10, 50). TopK deserves special recognition here, as it maintained competitive latency despite being tested through a cloud service rather than locally.
Interestingly, Quadrant showed an unusual pattern where its latency actually decreased as the number of requested results increased—likely due to its internal batching optimization for distance calculations.
Pinecone, while delivering perfect recall, had the highest latency of all databases tested, confirming its focus on accuracy over speed.
The Verdict: Which Vector Database Reigns Supreme?
Based on our comprehensive vector database benchmark, here's how each platform performed:
- Milvus: Best for raw speed with lowest latency and high throughput, but slower ingestion
- Weaviate: Offers balanced performance with strong QPS and good recall, though with occasional latency spikes
- Pinecone: Delivers perfect accuracy (100% recall) but at the cost of higher latency and lower QPS
- TopK: Shows promise for serverless/cloud-native applications with low latency and simple setup, though recall lags slightly
- Quadrant: Provides the best overall balance with fast ingestion, strong QPS at higher K values, and near-perfect recall
While each database has its strengths, Quadrant emerges as the overall winner in our vector database benchmark. It delivers a compelling combination of fast ingestion, strong query performance at scale, and near-perfect recall accuracy, making it suitable for a wide range of vector search applications.
Building Your Own Semantic Search Engine
With the benchmarks complete, you can use any of these vector databases to build your own semantic search engine. Our test implementation includes a UI interface where you can query all five databases simultaneously and compare their results side-by-side.
The power of semantic search becomes evident when you try queries like "I'm feeling sad today" and see how the system returns contextually relevant songs with sad themes—not just songs with the word "sad" in the title.
Conclusion
Vector databases are a critical component of modern AI infrastructure, enabling semantic search and retrieval-augmented generation (RAG) applications. Our benchmark reveals that while Pinecone offers unmatched accuracy and Milvus delivers blazing speed, Quadrant provides the best overall balance of performance metrics for most applications.
When choosing a vector database for your project, consider your specific requirements: Do you need lightning-fast queries? Perfect recall? Easy cloud deployment? Or a balanced approach? This benchmark should help you make an informed decision based on what matters most for your use case.
Let's Watch!
Ultimate Vector Database Benchmark: 5 Top Platforms Head-to-Head
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence