Build a Python Amazon Scraper That Bypasses Blocks Using Proxies and Best Practices
Jamal Washington
Infrastructure Lead
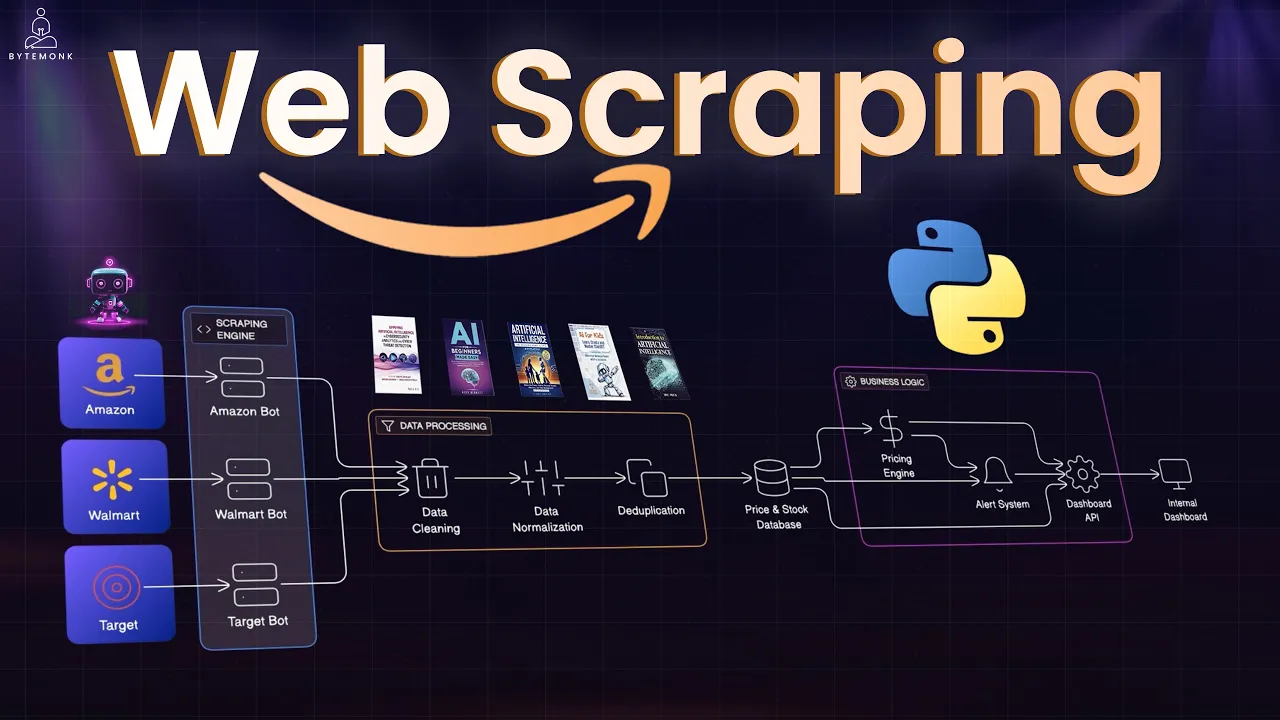
Web scraping is the art of automating a browser—essentially teaching a robot to browse the web like a human, find specific information, and extract it for analysis. While scraping simple websites is relatively straightforward, extracting data from complex e-commerce sites like Amazon presents significant challenges due to their sophisticated bot detection systems.
Understanding Web Scraping Fundamentals
Before diving into complex scraping techniques, it's important to understand the basics. Web scraping involves sending HTTP requests to a website, downloading the HTML content, and parsing it to extract the desired information. For beginners, simple sites like books.toscrape.com provide an excellent starting point to practice these fundamentals.
However, when scraping at scale—particularly from major e-commerce platforms—you'll quickly encounter obstacles designed to prevent automated data collection:
- Rate limiting (429 errors)
- IP bans and blocks
- CAPTCHA challenges
- JavaScript-rendered content
- Dynamic page layouts
These protection mechanisms make simple request-based scraping ineffective for sites like Amazon, requiring more sophisticated approaches.
Basic Python Scraping: A Starting Point
Let's start with a basic Python scraper that extracts book information from a simple website. This approach uses the Requests library for HTTP requests and Beautiful Soup for HTML parsing.
import requests
from bs4 import BeautifulSoup
# Target URL
url = 'https://books.toscrape.com/'
# Set a user agent to mimic a browser
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# Send GET request
response = requests.get(url, headers=headers)
# Check if request was successful
if response.status_code == 200:
# Parse HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Find all book containers
books = soup.select('article.product_pod')
# Extract and print book titles
for book in books[:5]: # First 5 books
title = book.h3.a['title']
price = book.select_one('p.price_color').text
print(f'Title: {title}\nPrice: {price}\n')
else:
print(f'Failed to retrieve the webpage: {response.status_code}')This simple script works well for basic websites that don't implement anti-scraping measures. However, for more complex sites like Amazon, we need to enhance our approach.
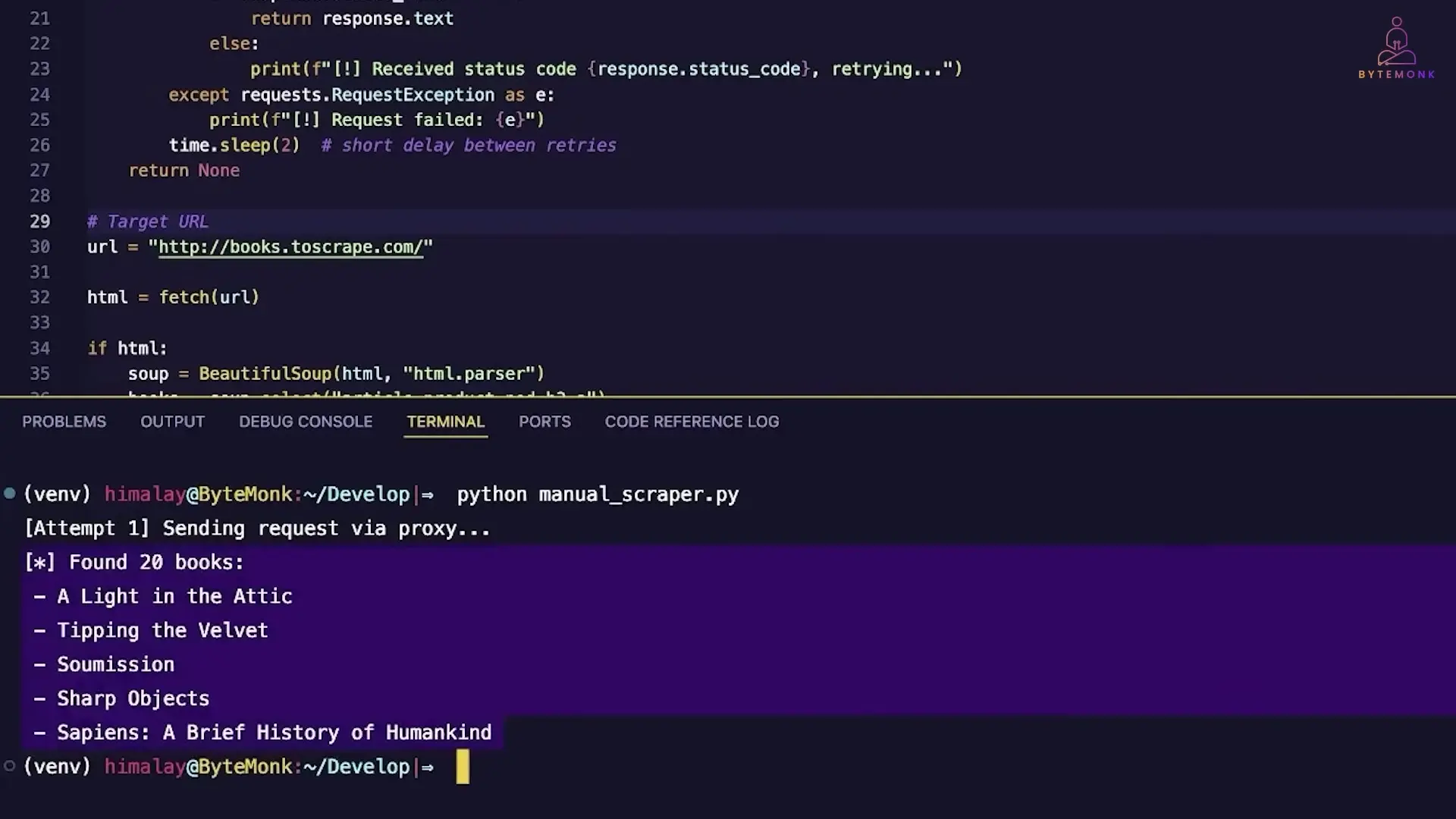
The Power of Proxy Rotation for Python Amazon Scraping
One of the most effective techniques for avoiding detection when scraping Amazon is proxy rotation. A proxy acts as a middleman between your scraper and the target website, hiding your real IP address.
What is a Proxy and Why Use It?
A proxy server forwards your requests to the destination website. Instead of seeing your real IP address, the site sees the proxy's IP. By rotating through different proxies, each request appears to come from a different user in a different location, helping avoid detection and blocking.
For web scraping, we specifically use forward proxies, which route outbound requests from the client side. This differs from reverse proxies that protect backend servers and handle incoming traffic.
Implementing Basic Proxy Rotation
Here's how to implement a basic proxy rotation system for your Python Amazon scraper:
import requests
from bs4 import BeautifulSoup
import time
def fetch(url, proxy=None, max_retries=3):
"""Fetch URL with retry logic and proxy support"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
proxies = None
if proxy:
proxies = {
'http': f'http://{proxy}',
'https': f'http://{proxy}'
}
for attempt in range(max_retries):
try:
response = requests.get(
url,
headers=headers,
proxies=proxies,
timeout=10
)
if response.status_code == 200:
return response.text
else:
print(f"Attempt {attempt+1} failed with status code: {response.status_code}")
except Exception as e:
print(f"Attempt {attempt+1} failed with error: {str(e)}")
# Wait before retrying
if attempt < max_retries - 1:
time.sleep(2 * (attempt + 1)) # Exponential backoff
return None
# Example usage
proxy = "123.45.67.89:8080" # Replace with your proxy
html = fetch("https://books.toscrape.com/", proxy)
if html:
soup = BeautifulSoup(html, 'html.parser')
books = soup.select('article.product_pod')
for book in books[:5]:
title = book.h3.a['title']
print(f"Title: {title}")
else:
print("Failed to fetch content after multiple retries")While free proxies exist, they're often unreliable with high failure rates. For serious scraping projects, especially when targeting Amazon, professional proxy services provide much better reliability and performance.
Advanced Python Amazon Scraping with Residential Proxies
For scraping Amazon effectively, residential proxies are far superior to free or datacenter proxies. Residential proxies use IPs from real devices and internet service providers, making them much harder for websites to detect and block.
Here's how to implement a more robust Amazon scraper using residential proxies:
import requests
from bs4 import BeautifulSoup
import json
import csv
import time
import random
from urllib3.exceptions import InsecureRequestWarning
# Disable SSL warnings
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)
class AmazonScraper:
def __init__(self, proxy_username, proxy_password, proxy_endpoint):
self.session = requests.Session()
# Configure proxy
self.proxy = f"http://{proxy_username}:{proxy_password}@{proxy_endpoint}"
self.proxies = {
"http": self.proxy,
"https": self.proxy
}
# Set headers to mimic a real browser
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
def scrape_amazon_books(self, search_term, num_pages=1):
books = []
base_url = "https://www.amazon.com/s?k="
for page in range(1, num_pages + 1):
url = f"{base_url}{search_term.replace(' ', '+')}&page={page}"
print(f"Scraping page {page}: {url}")
html = self.fetch_page(url)
if not html:
print(f"Failed to fetch page {page}")
continue
# Check if we hit a CAPTCHA
if "Enter the characters you see below" in html or "To discuss automated access to Amazon data" in html:
print("CAPTCHA detected! Proxy might be blocked.")
continue
page_books = self.parse_books(html)
books.extend(page_books)
# Be polite, don't hammer the server
time.sleep(random.uniform(2, 5))
return books
def fetch_page(self, url, max_retries=3):
for attempt in range(max_retries):
try:
response = self.session.get(
url,
headers=self.headers,
proxies=self.proxies,
timeout=20,
verify=False
)
if response.status_code == 200:
return response.text
else:
print(f"Attempt {attempt+1} failed with status code: {response.status_code}")
except Exception as e:
print(f"Attempt {attempt+1} failed with error: {str(e)}")
# Wait before retrying
if attempt < max_retries - 1:
time.sleep(2 * (attempt + 1))
return None
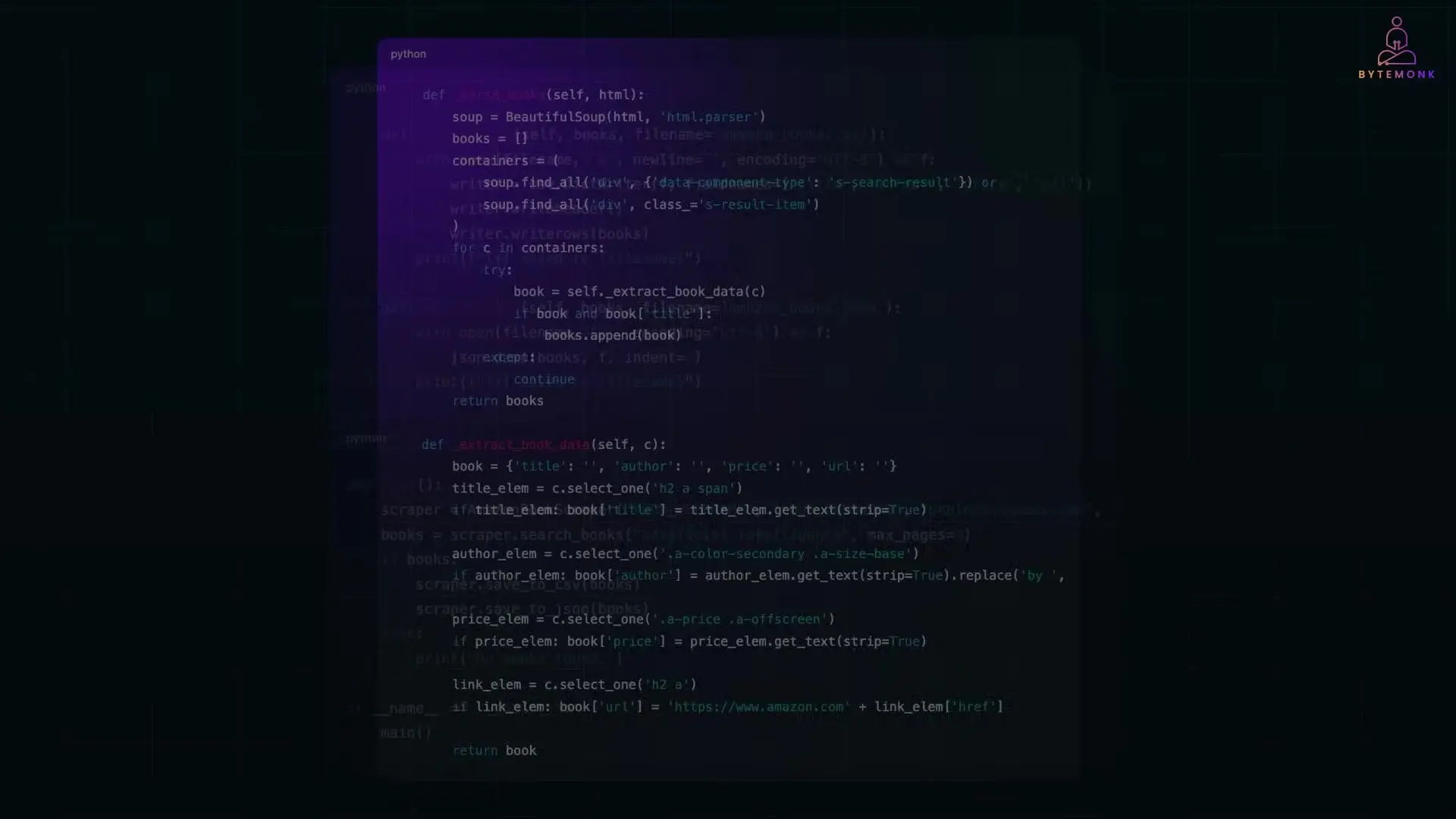
def parse_books(self, html):
soup = BeautifulSoup(html, 'html.parser')
books = []
# Find all book containers
results = soup.select('div[data-component-type="s-search-result"]')
for result in results:
try:
# Extract book title
title_element = result.select_one('h2 a span')
title = title_element.text.strip() if title_element else "Unknown Title"
# Extract author
author_element = result.select_one('a.a-size-base.a-link-normal.s-underline-text')
author = author_element.text.strip() if author_element else "Unknown Author"
# Extract price
price_element = result.select_one('span.a-price > span.a-offscreen')
price = price_element.text.strip() if price_element else "N/A"
# Extract product URL
url_element = result.select_one('h2 a')
product_url = "https://www.amazon.com" + url_element['href'] if url_element and 'href' in url_element.attrs else ""
books.append({
'title': title,
'author': author,
'price': price,
'url': product_url,
'timestamp': time.strftime("%Y-%m-%d %H:%M:%S")
})
except Exception as e:
print(f"Error parsing book: {str(e)}")
return books
def save_to_csv(self, books, filename="amazon_books.csv"):
if not books:
print("No books to save")
return
with open(filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=books[0].keys())
writer.writeheader()
writer.writerows(books)
print(f"Saved {len(books)} books to {filename}")
def save_to_json(self, books, filename="amazon_books.json"):
if not books:
print("No books to save")
return
with open(filename, 'w', encoding='utf-8') as f:
json.dump(books, f, ensure_ascii=False, indent=4)
print(f"Saved {len(books)} books to {filename}")
def main():
# Your proxy service credentials
proxy_username = "your_username"
proxy_password = "your_password"
proxy_endpoint = "proxy.provider.com:12345"
scraper = AmazonScraper(proxy_username, proxy_password, proxy_endpoint)
books = scraper.scrape_amazon_books("python programming", num_pages=2)
# Save the results
scraper.save_to_csv(books)
scraper.save_to_json(books)
# Print sample results
for book in books[:3]:
print(f"Title: {book['title']}")
print(f"Author: {book['author']}")
print(f"Price: {book['price']}")
print("---")
if __name__ == "__main__":
main()This more advanced scraper includes several important features for successful Amazon scraping:
- Proxy integration with authentication
- Realistic browser headers
- CAPTCHA detection
- Retry logic with exponential backoff
- Random delays between requests
- Robust error handling
- Data extraction for multiple fields
- Multiple export formats (CSV and JSON)
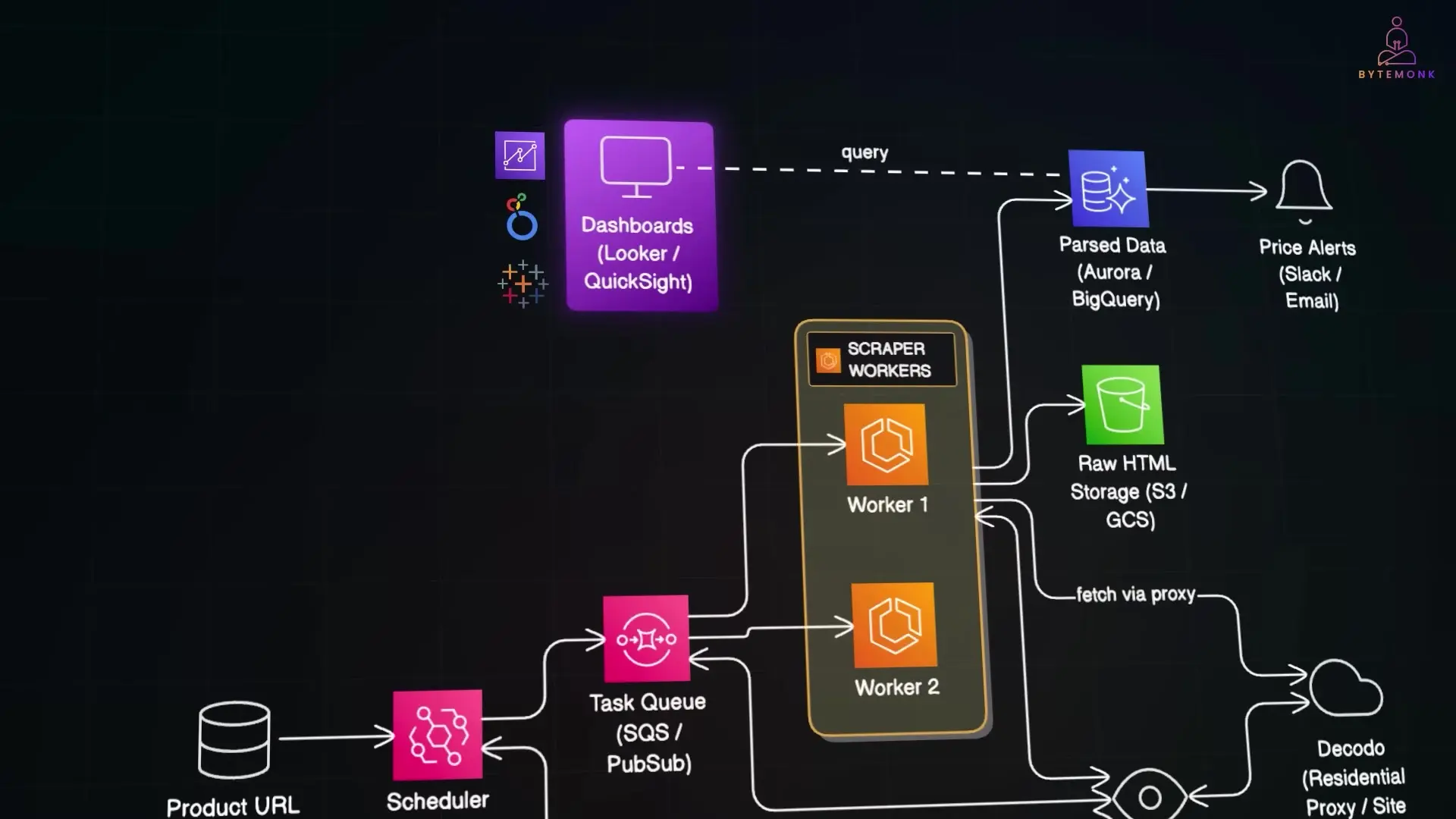
Designing a Production-Grade Python Amazon Scraping System
For enterprise-level applications, such as competitive price monitoring across e-commerce platforms, you'll need a more sophisticated architecture. Here's what a production-grade scraping system might look like in the cloud:
Key Components of a Scalable Scraping Architecture
- Data Source Management: Store your target URLs in a database like DynamoDB, PostgreSQL on RDS, or even a shared Google Sheet for business users to update.
- Scheduler: Use AWS Lambda functions triggered by EventBridge to run scraping jobs at specific intervals (e.g., daily at 3 AM or multiple times per day).
- Task Queue: Implement Amazon SQS or Google Cloud Pub/Sub to manage scraping tasks, providing control over concurrency and enabling safe scaling.
- Scraper Workers: Deploy containerized scrapers on AWS Fargate, Google Cloud Run, or Kubernetes for flexible scaling based on workload.
- Proxy Management: Integrate with a residential proxy service to route requests through different IPs, avoiding detection and blocks.
- Data Storage: Store raw HTML in S3 or Google Cloud Storage for auditing, and structured data in a database like Amazon Aurora or BigQuery for analytics.
- Analysis Layer: Build dashboards in Amazon QuickSight, Looker Studio, or Tableau to visualize trends and competitor pricing strategies.
- Alert System: Set up notifications via SNS, email, or Slack when significant price changes are detected.
- Monitoring & Observability: Implement CloudWatch or Stack Driver to track scraping failures, proxy usage, and system health.
Best Practices for Ethical Python Web Scraping
While web scraping is a powerful technique, it's important to use it responsibly and ethically:
- Always check the website's robots.txt file and terms of service before scraping
- Implement rate limiting to avoid overwhelming the target server
- Use proper identification in your user agent string
- Cache results when possible to reduce unnecessary requests
- Only extract the data you need, avoiding excessive bandwidth usage
- Consider using the site's official API if one is available
Conclusion: Building Effective Python Amazon Scrapers
Web scraping Amazon and other e-commerce sites requires a sophisticated approach that goes beyond basic HTTP requests. By implementing proxy rotation, handling JavaScript-rendered content, and designing a scalable architecture, you can build reliable scrapers that avoid blocks and deliver consistent results.
Whether you're building a competitive price monitoring tool, conducting market research, or gathering data for analysis, the techniques outlined in this article provide a solid foundation for your Python Amazon scraping projects. Remember to scrape responsibly, respect website terms of service, and consider the ethical implications of your data collection activities.
Let's Watch!
How to Build a Python Amazon Scraper Without Getting Blocked
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence