How to Build Powerful Self-Hosted AI Agents Using CrewAI with Ollama Integration
Sophia Okonkwo
Technical Writer

Creating AI agents often leads developers to default to OpenAI's services due to their simplicity - just generate an API key, add it as an environment variable, and you're ready to go. While GPT models offer excellent performance, this approach comes with drawbacks: ongoing API costs and limited model selection. What if you could build powerful autonomous AI agents that run entirely on your local machine without any usage fees? This tutorial will show you exactly how to implement local AI agents using CrewAI framework and Ollama.
Why Use Local AI Models for Your Agents?
Before diving into implementation, let's understand the advantages of local AI deployment. Using Ollama with CrewAI provides several benefits for your AI agent development workflow:
- Zero API costs - run models as much as you want without usage fees
- Complete privacy - your data never leaves your machine
- Access to diverse open-source models beyond GPT
- No internet dependency after initial model download
- Full control over model selection and configuration
- Ability to experiment with different model sizes based on your hardware
The tradeoff is computational requirements - larger models demand more powerful hardware. For development and testing, smaller models like Llama-3 8B or Phi-3 Mini provide a good balance between performance and resource usage.
Setting Up Ollama for Local AI Model Hosting
Ollama is an open-source tool that simplifies running large language models locally. It handles downloading, setup, and serves models through a consistent API interface. Here's how to get started:
- Visit ollama.com and download the application for your operating system
- Install and launch Ollama - you'll see a small llama icon in your system tray/menu bar indicating the server is running
- Browse available models on the Ollama website or through the application
- Choose a model that matches your hardware capabilities (smaller models for average machines, larger ones for powerful systems)
For this tutorial, we'll use the Phi-3 (53) model with 3.8 billion parameters, which offers a good balance between performance and resource requirements. More powerful computers can experiment with the 14 billion parameter version for potentially better results.
Downloading Your Model with Ollama CLI
Once Ollama is running, you'll need to download your chosen model. Open your terminal and use the Ollama CLI command:
ollama pull phi3:latestOr for a specific model version:
ollama pull phi3:3.8bThe download may take several minutes depending on your internet connection and the model size. Once completed, the model will be available locally for use with your AI agents.
Integrating Ollama with CrewAI Framework
Now let's integrate our local Ollama model with the CrewAI framework. We'll need to create a connection between CrewAI and our local Ollama server using LangChain's OpenAI compatibility layer.
from langchain.chat_models.openai import ChatOpenAI
import os
# Set a dummy OpenAI API key (required but not actually used)
os.environ["OPENAI_API_KEY"] = "sk-dummy-key-111"
# Configure the LLM to use our local Ollama model
llm = ChatOpenAI(
model="phi3:3.8b", # The model we downloaded with Ollama
base_url="http://localhost:11434/v1", # Ollama's local API endpoint
)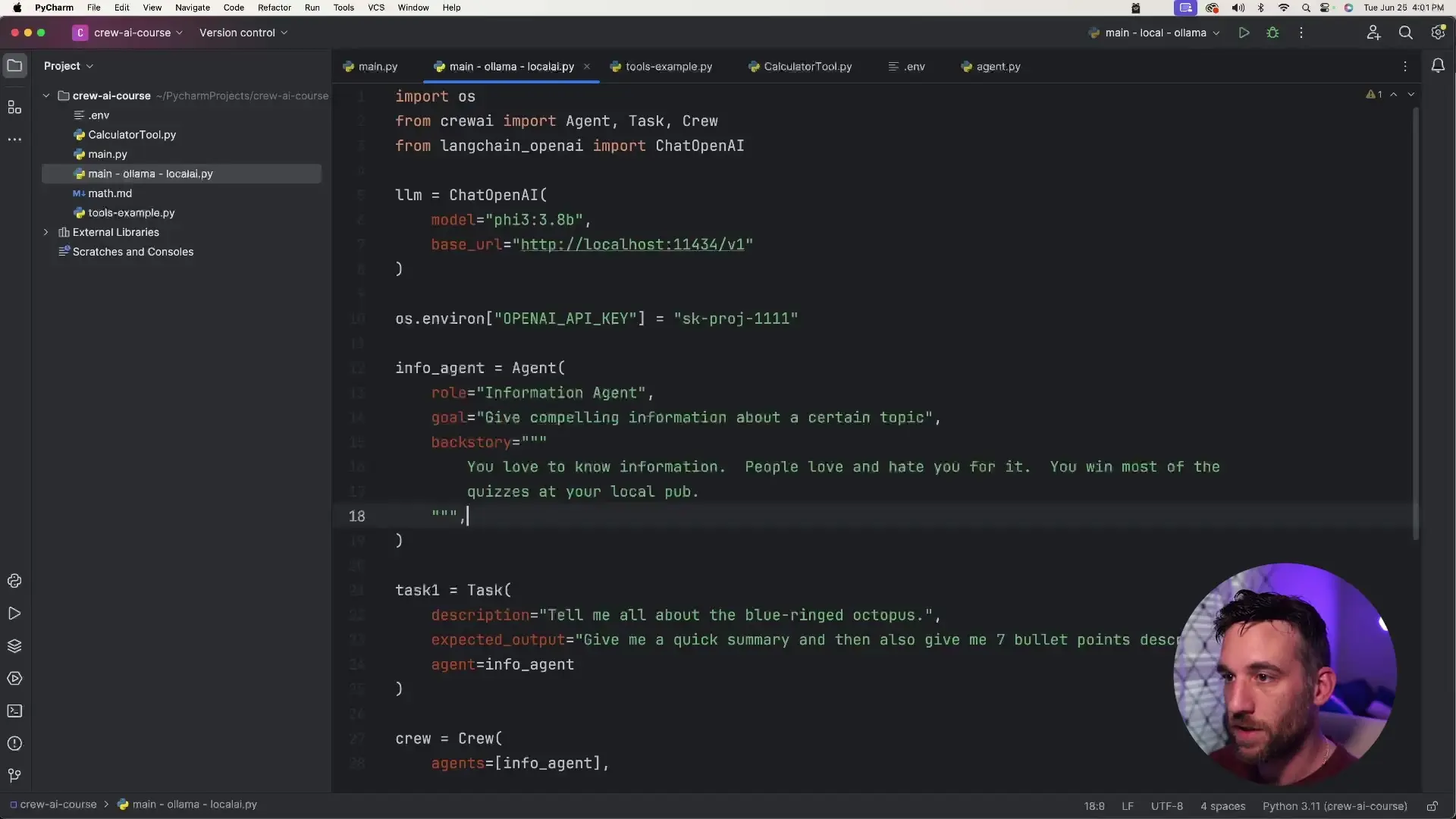
The key aspects of this configuration are:
- Using LangChain's ChatOpenAI class for compatibility
- Setting the model parameter to match your downloaded Ollama model
- Configuring the base_url to point to your local Ollama server
- Including a dummy OpenAI API key (required by the library but not actually used)
Creating a CrewAI Agent with Local LLM
Now we can create our CrewAI agent that uses the local Ollama model instead of OpenAI's APIs. Here's a complete example of setting up an information agent:
from crewai import Agent, Crew, Task
from langchain.chat_models.openai import ChatOpenAI
import os
# Set dummy OpenAI API key
os.environ["OPENAI_API_KEY"] = "sk-dummy-key-111"
# Configure local LLM
llm = ChatOpenAI(
model="phi3:3.8b",
base_url="http://localhost:11434/v1",
)
# Create an information agent
information_agent = Agent(
role="Marine Biology Expert",
goal="Provide detailed information about marine creatures",
backstory="You are a renowned marine biologist with extensive knowledge of all sea creatures. You've spent decades studying marine life and can provide comprehensive information about any aquatic species.",
llm=llm # Inject our local LLM
)
# Create a task for the agent
research_task = Task(
description="Research and provide detailed information about the box jellyfish, including its habitat, characteristics, and dangers.",
agent=information_agent
)
# Create a crew with our agent
crew = Crew(
agents=[information_agent],
tasks=[research_task],
verbose=True
)
# Execute the crew
result = crew.kickoff()
print(result)The critical difference from a standard OpenAI implementation is the llm=llm parameter passed to the Agent constructor. This tells CrewAI to use our local Ollama model instead of making API calls to OpenAI.
Testing Your Local AI Agent
When you run the code, your agent will process the task using the local Ollama model. Depending on your hardware, this may take longer than cloud-based APIs, but you'll get results without any usage costs.
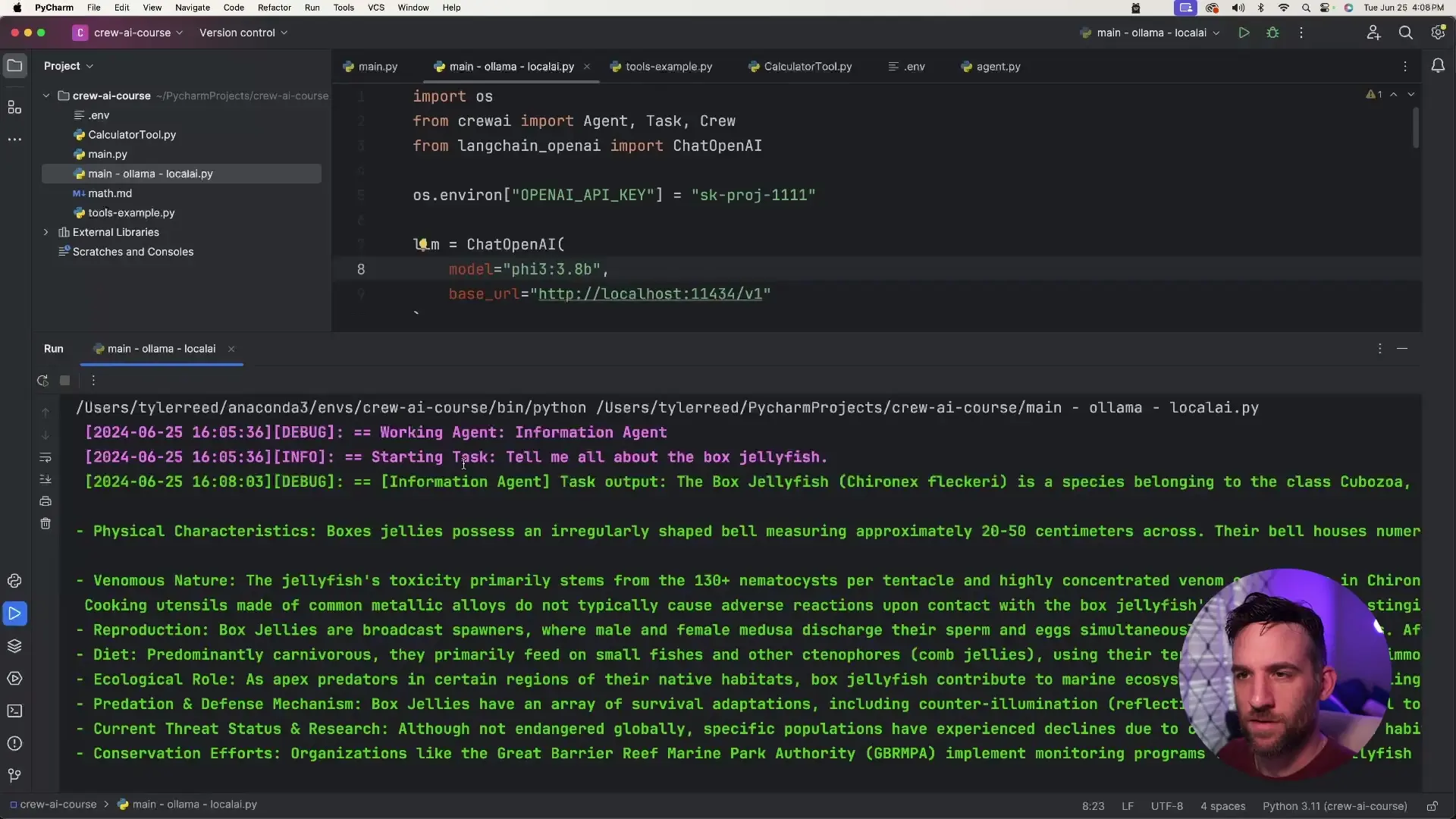
In our example, the agent successfully provided detailed information about box jellyfish, including a summary and bullet points about its characteristics, habitat, and dangers - all processed locally without any API calls or costs.
Performance Considerations for Local AI Agents
When working with local AI models, performance is an important consideration. Here are some tips to optimize your experience:
- Match model size to your hardware - smaller models (3-7B parameters) for average machines, larger models (13B+) for high-end systems
- Expect longer processing times compared to cloud APIs - our test took about 2.5 minutes on a mid-range machine
- For development and testing, consider using smaller models or OpenAI's APIs, then switch to local models for production
- Close resource-intensive applications while running local models
- Consider quantized versions of models (like 4-bit or 8-bit) which use less memory at the cost of slight quality reduction
Expanding Your Local AI Agent Capabilities
Once you've mastered the basics of local AI agents with CrewAI and Ollama, you can expand your implementation in several ways:
- Create multiple agents using different models - use smaller models for simpler tasks and larger models for complex reasoning
- Implement agent orchestration where multiple specialized agents collaborate on complex tasks
- Explore other local AI frameworks like LM Studio or Text Generation WebUI for different model options
- Add tools and APIs to your agents for real-world capabilities like web searching, data analysis, or system automation
- Containerize your solution with Docker for easier deployment across different environments
Conclusion
By combining CrewAI with Ollama, you can create powerful, autonomous AI agents that run entirely on your local machine. This approach eliminates API costs, enhances privacy, and gives you complete control over your AI models. While local deployment comes with hardware requirements and potential performance tradeoffs, the benefits of self-hosted AI solutions make it an attractive option for many applications.
Whether you're building AI agents for personal projects, business automation, content creation, or local SEO optimization, this local deployment approach provides flexibility and cost-effectiveness that cloud-based solutions can't match. As open-source AI models continue to improve, the gap between proprietary and self-hosted solutions will only narrow, making local AI agent orchestration an increasingly viable option for developers and businesses alike.
Let's Watch!
Build Self-Hosted AI Agents: CrewAI with Ollama Tutorial
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence