1-Bit LLMs: How Quantization Makes AI Models Run on Less Hardware and Save Energy
Priya Narayan
Systems Architect

State-of-the-art open-source AI models are impressive but often inaccessible to most developers due to their enormous hardware requirements. Running a copy of models like Deep Seek V3 requires hardware costing upwards of $400,000 - putting them well beyond the reach of individual developers and small teams. This hardware barrier has led researchers to explore innovative ways to make these powerful models more accessible through techniques like quantization.
The Hardware Challenge of Modern LLMs
Even when researchers create smaller models or distill larger ones into more compact versions, the hardware requirements often remain substantial. A model that's 10 times smaller might still need a GPU worth $20,000 to run effectively. This leaves developers with limited options: either use significantly smaller models with fewer parameters (7B or even 1.5B parameter models) or find ways to run larger models more efficiently.
The problem with using very small models is that they can feel frustratingly limited in their capabilities - like talking to an AI with a tiny brain. This is where quantization techniques become crucial for balancing capability with hardware requirements.
Understanding Model Quantization
At its core, an AI model functions like a mathematical function f that maps an input X to an output Y. Within this function are weights that determine how inputs are transformed into outputs. These weights are established during training and collectively form what we call the model's parameters.
In standard models, weights are typically stored using FP16 (16-bit floating point numbers), which provides high precision but requires substantial memory. A 7 billion parameter model represented in FP16 requires approximately 14GB of memory - which needs to be loaded into GPU VRAM for efficient processing.
The challenge arises when your hardware has limited VRAM. For instance, if you only have 8GB of VRAM, you can't fit the entire model at once. While techniques like weight offloading exist (rotating weights in and out of memory), they significantly slow down processing.
How Quantization Reduces Memory Requirements
Quantization addresses this challenge by reducing the precision of the weights. Instead of using 16 bits per weight, quantized models might use 8 bits (FP8) or even 4 bits (INT4). This dramatically reduces memory requirements but comes with a tradeoff in numerical precision.
- FP16: Smallest increment between numbers is ~0.001
- FP8: Smallest increment between numbers is ~0.125
- INT4: Limited to integer values
This reduction in precision means weights must be rounded up or down, which can impact the model's prediction accuracy. However, research has consistently shown that with proper calibration using fine-tuning datasets, quantized models can maintain surprisingly good performance while using significantly less memory.
The Emergence of BitNet: 1-Bit Transformers
In October 2023, researchers pushed the boundaries of quantization with a paper titled "BitNet: Scaling 1-bit Transformers for Large Language Models." This groundbreaking research explored the possibility of creating LLMs where weights are represented using just a single bit - meaning each weight could only be 1 or -1.

The theoretical benefits of such an approach are enormous: 16 times less storage than standard models and the elimination of matrix multiplications (since operations with just two possible values can be handled with simple addition and subtraction). However, this extreme quantization introduced significant mathematical challenges, as representing complex patterns with just two possible weight values is inherently limiting.
Moreover, the researchers found it impossible to convert all weights to 1-bit representations, particularly those in attention mechanisms and layer-to-layer activations, which proved too important for model functionality.
BitNet B1.58: Adding Zero to the Equation
Four months after the initial BitNet paper, the same researchers introduced BitNet B1.58, which addressed a fundamental limitation of the original approach. Instead of just using 1 and -1 as possible weight values, they introduced a third state: zero.
This addition was crucial as it introduced sparsity, allowing the model to effectively turn off connections between neurons when appropriate. While this technically increased the information content per weight to 1.58 bits (hence the name), it maintained most of the computational benefits while significantly improving model performance.
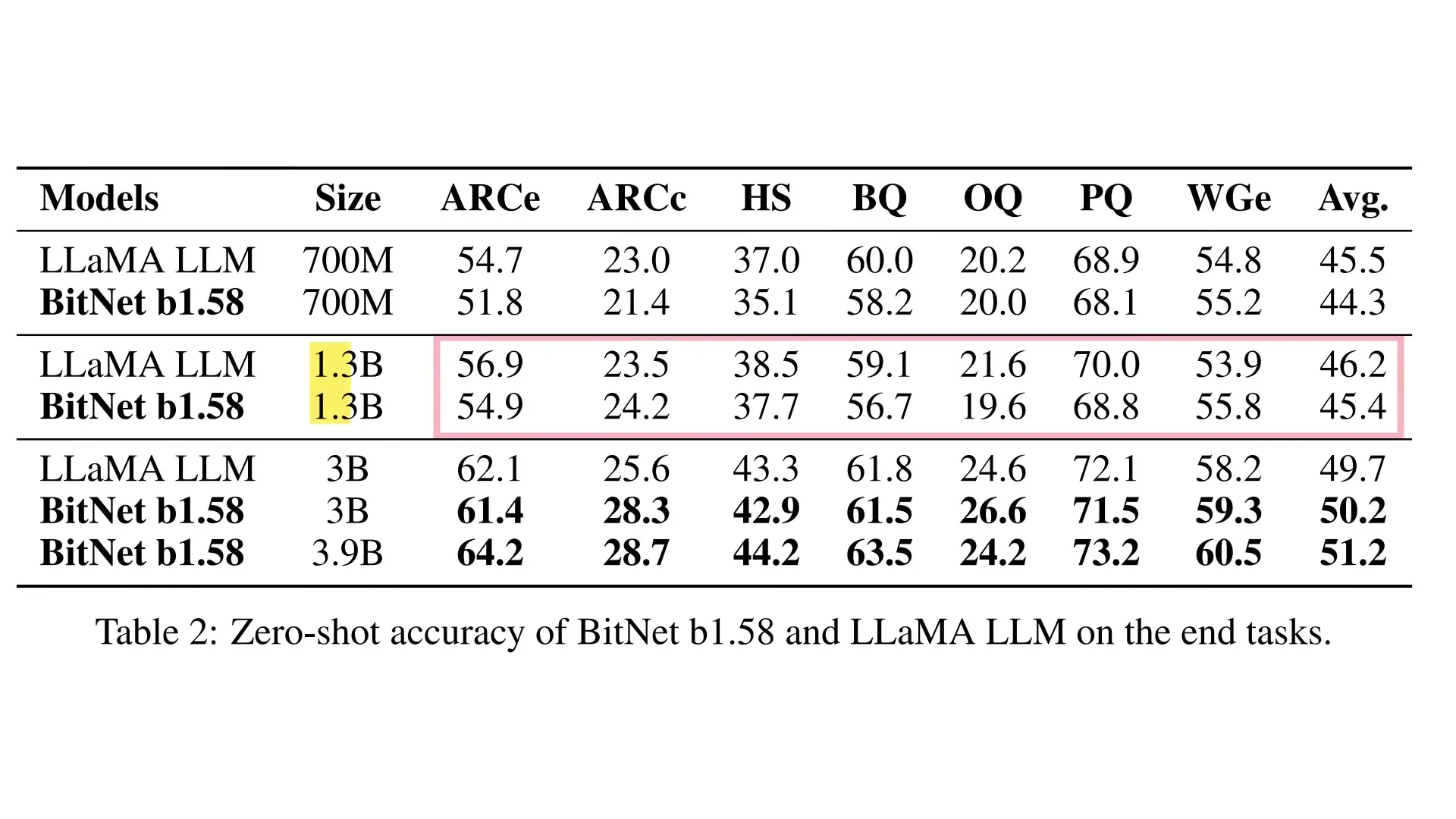
Scaling Benefits of BitNet
The researchers conducted extensive experiments comparing BitNet B1.58 to full-precision Llama models at various parameter counts. The results revealed fascinating scaling properties:
- At 1.3B parameters: BitNet uses 3x less memory but performs worse than full-precision Llama
- At 3B parameters: BitNet uses 3.5x less memory, is 2.7x faster, and matches or exceeds Llama's performance
- At 70B parameters: BitNet requires 7.16x less memory than Llama 70B
This demonstrates a promising scaling law: as parameter counts increase, the memory efficiency advantage of BitNet grows, while performance remains competitive with full-precision models. Most impressively, a 70B parameter BitNet B1.58 is more efficient in generation speed, memory usage, and energy consumption than a 13B parameter full-precision LLM - using up to 30 times less energy.
Further Optimizations: BNET A4.8.8
While BitNet B1.58 addressed weight size, the researchers recognized that activations (the signals passed between layers) and the KV cache (which grows with context length) remained bottlenecks. Eight months after BitNet B1.58, they introduced BNET A4.8.8, which uses 4-bit activations for attention and feedforward network inputs while utilizing 8-bit precision for intermediate states.
This hybrid approach was necessary because certain intermediate values, particularly in attention mechanisms, contain critical outlier values that would be lost with more aggressive quantization. Their experiments showed that while full 4-bit activation models failed to converge during training, the A4.8.8 approach maintained performance while further reducing memory and computation requirements.
Practical Implications for Developers
These advancements in model quantization have profound implications for AI deployment. Developers with limited hardware can now potentially run larger, more capable models by leveraging quantization techniques. Some practical takeaways include:
- When choosing between a smaller full-precision model or a larger quantized model, research suggests the larger quantized model will typically deliver better performance
- For deployment on consumer hardware, 8-bit quantization offers an excellent balance between performance and resource requirements
- More extreme quantization (4-bit or even 1-bit approaches like BitNet) may enable running surprisingly large models on modest hardware
- The memory and energy savings from quantization become more pronounced as model size increases
The Future of Efficient LLMs
The rapid progress in model quantization techniques demonstrates that efficiency optimization is a vibrant area of AI research. As these methods mature, we can expect to see increasingly powerful models running on more modest hardware, democratizing access to state-of-the-art AI capabilities.
For developers and organizations looking to deploy LLMs, understanding quantization options provides a pathway to balancing model capability with hardware constraints. Whether using llm 8 bit quantization for a balanced approach or exploring more aggressive techniques like BitNet for maximum efficiency, these methods are making advanced AI more accessible than ever before.
As research continues to advance, we may soon see 1-bit and other highly optimized models becoming standard options for efficient AI deployment across a wide range of applications and hardware configurations.
Let's Watch!
1-Bit LLMs: How Quantization Makes AI Models Run on Less Hardware
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence