Beyond Tokens: How Byte Latent Transformer Architecture Is Revolutionizing LLM Tokenization
Sophia Okonkwo
Technical Writer

AI chatbots built from large language models don't perceive text the same way humans do. Instead, they process information as sequences of tokens—discrete units from a predefined vocabulary. While this approach has powered the current generation of LLMs, it comes with significant limitations that affect performance, efficiency, and multilingual capabilities. Enter the Byte Latent Transformer (BLT), a revolutionary architecture that aims to address these limitations by working directly with raw byte data instead of tokens.
The Problem with Traditional Tokenization
Tokenization serves as a middle ground between character-level and word-level processing. Individual characters make it difficult to capture semantic meaning, while whole words create challenges with long terms, new vocabulary, rare words, and typos. However, this compromise introduces several problems:
- Inefficient compute allocation: The same computational effort is used for every token, whether it's a simple punctuation mark or a complex technical term
- Language bias: Tokenizers trained primarily on English perform poorly on other languages and specialized text like code
- Oversegmentation: Languages underrepresented in training data get broken into longer, less meaningful sequences
- Vulnerability to typos: Minor variations can result in completely different tokenization patterns, confusing the model and making jailbreaks easier
- Limited character-level understanding: Models struggle with tasks requiring character counting or basic mathematical operations
Tokenization also requires a separate pre-processing step with its own training process, adding complexity to the model pipeline. These limitations have prompted researchers to explore alternatives that can provide a more flexible, efficient approach to language modeling.

How the Byte Latent Transformer Works
The Byte Latent Transformer (BLT) proposes a tokenizer-free architecture designed to learn directly from raw byte data. Unlike traditional tokenizers that use a fixed vocabulary, BLT uses dynamic "patches" that group bytes based on their predictive complexity.
The core idea behind BLT is to allocate computational resources where they're most needed. For example, predicting the next character in a common phrase might be relatively easy, while predicting the first character of a new word presents many possible options and requires more computational attention.
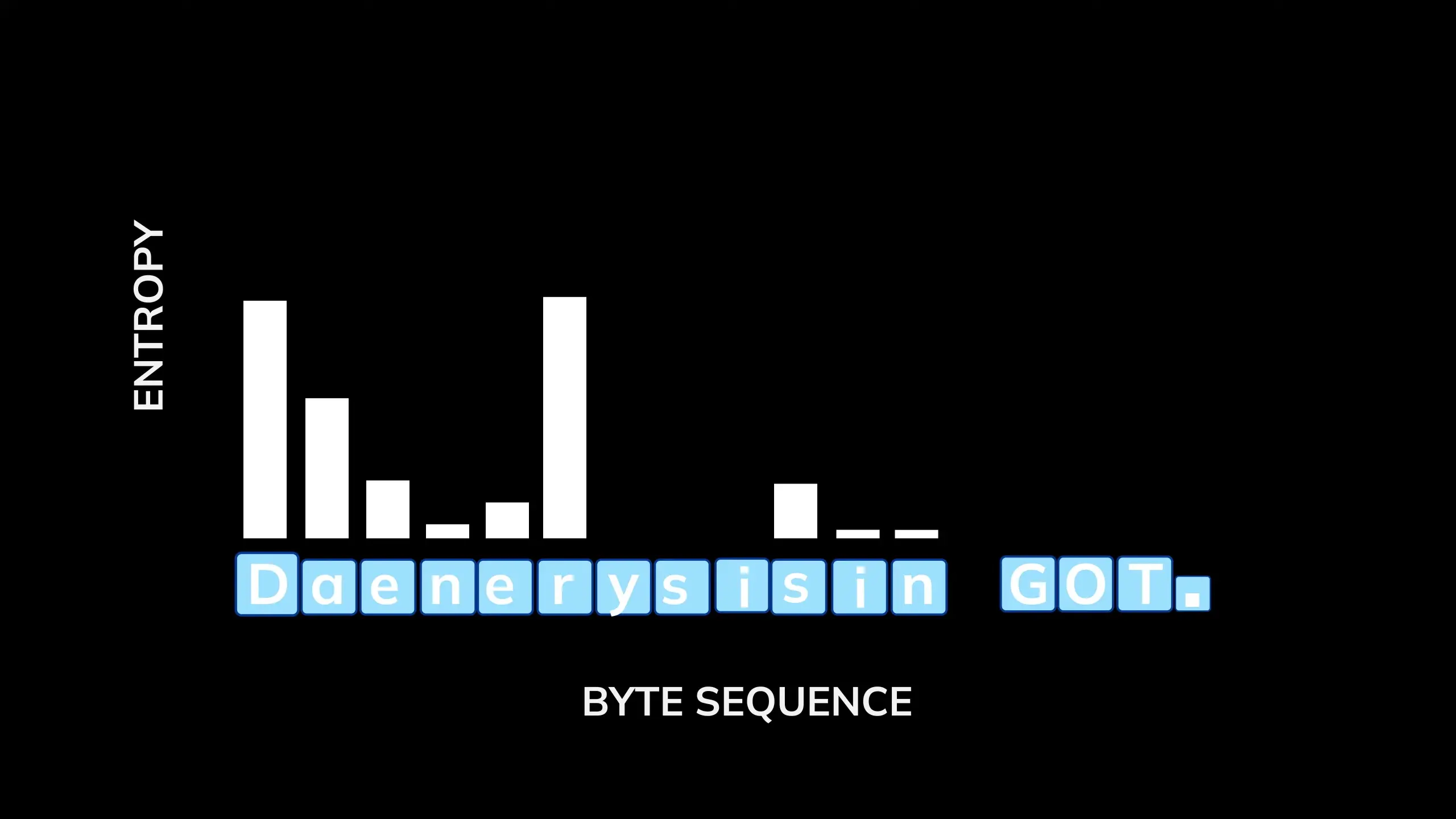
Entropy-Based Patching
BLT segments byte sequences into patches using what's called entropy-based patching. Patch boundaries are determined by two criteria:
- Global constraint: A new patch starts if the entropy (uncertainty) exceeds a global threshold, identifying points of high unpredictability
- Approximate monotonic constraint: A new patch starts if the change in entropy exceeds a relative threshold, marking unexpected shifts in complexity
This approach creates longer patches for predictable sequences (reducing the computational load) and shorter patches for information-dense or unpredictable sequences (allocating more computational resources where needed).
BLT Architecture Components
The BLT architecture consists of three main components:
- Local Encoder: Processes individual bytes with their n-gram context and creates patches based on entropy
- Latent Global Transformer: A standard transformer that operates on patch representations rather than token embeddings
- Local Decoder: Converts predicted patch representations back into byte sequences to form the generated text
To build more meaningful patches, individual bytes are embedded together with the n-grams they're part of. This provides local context before patching. To prevent an explosion of vocabulary size from all possible byte combinations, a rolling polynomial hash (roll polyhash) maps these n-grams to a fixed size.
Advantages of the BLT Approach
The BLT architecture offers several significant advantages over traditional tokenization-based LLMs:
- Computational Efficiency: BLT can match Llama 3's performance while using up to 50% fewer FLOPs at inference time
- New Scaling Axis: Efficiency can be adjusted through patch size alongside model size, offering a new dimension for optimization
- Improved Multilingual Performance: By working directly with bytes, BLT sidesteps many issues with multilingual modeling
- Better Handling of Rare Words: The architecture doesn't penalize uncommon vocabulary with excessive tokenization
- Enhanced Subword Understanding: BLT shows improvements on tasks requiring orthographic knowledge, phonology, and low-resource machine translation

Current Limitations and Future Directions
While BLT represents a significant advancement, the approach is still evolving. Recent research has explored alternatives that compress raw bytes into chunks, but these approaches have their own limitations. For example, some methods separate bytes using spaces, which doesn't work well for languages without explicit spacing (like Chinese).
However, these newer architectures offer exciting possibilities, such as the ability to predict several bytes or even multiple words in a single step. This could lead to further efficiency gains and improved performance across a wider range of languages and tasks.
Implications for the Future of LLM Development
The BLT architecture represents a promising foundation for moving beyond token-based LLMs toward models that work with lower-level representations. With Meta open-sourcing an 8B BLT model trained on 4 trillion bytes, researchers and developers now have access to this technology to build upon and improve.
As LLMs continue to evolve, approaches like BLT that eliminate artificial abstractions and allow models to learn directly from raw data may become increasingly important. These innovations could lead to more efficient, more capable, and more linguistically diverse AI systems that better understand the nuances of human language across cultures and contexts.
Conclusion
The Byte Latent Transformer represents a significant step forward in language model architecture by eliminating the need for tokenization and working directly with raw byte data. By dynamically allocating computational resources based on the complexity of the input, BLT achieves impressive efficiency gains while maintaining or improving performance across a range of tasks.
As research in this area continues to advance, we may see tokenization—a fundamental component of current LLMs—gradually replaced by more flexible, efficient approaches that better capture the full richness and diversity of human language. For developers and researchers working with language models, understanding these architectural innovations will be crucial for building the next generation of AI systems.
Let's Watch!
Beyond Tokens: How BLT Architecture Is Revolutionizing LLM Tokenization
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence