ByteDance's Revolutionary Model Merging Technique Cuts AI Training Costs by Millions of Dollars
Priya Narayan
Systems Architect

ByteDance, the parent company behind TikTok and Douyin, has emerged as a formidable player in the AI research landscape through its AI lab. The lab is quickly establishing itself as one of China's premier AI research institutions, with groundbreaking papers and concepts that rival work from established players like Google and OpenAI. What makes ByteDance particularly notable is not just their cutting-edge research, but their willingness to share cost-saving techniques that could potentially save millions of dollars in AI training costs.
The Challenge of AI Model Training Costs
Pre-training large language models (LLMs) has become prohibitively expensive. A single training run for a 70B parameter model can cost upwards of $2 million at market prices. This massive financial barrier has limited innovation in the field, as only the largest tech companies can afford to conduct extensive experiments with pre-training methodologies.
This expense is precisely why research on cost-saving techniques like model merging during pre-training has been scarce. The risk of spending millions on experiments with no guaranteed improvements, coupled with the reluctance to share competitive advantages, has kept many potential innovations under wraps.
ByteDance's Breakthrough: Pre-trained Model Averaging (PMA)
In their paper "Model Merging in Pre-training of LLM," ByteDance researchers introduce a technique called Pre-trained Model Averaging (PMA). This approach works by saving model checkpoints at fixed token intervals during the constant learning rate phase of training, then averaging these checkpoints to create a merged model.
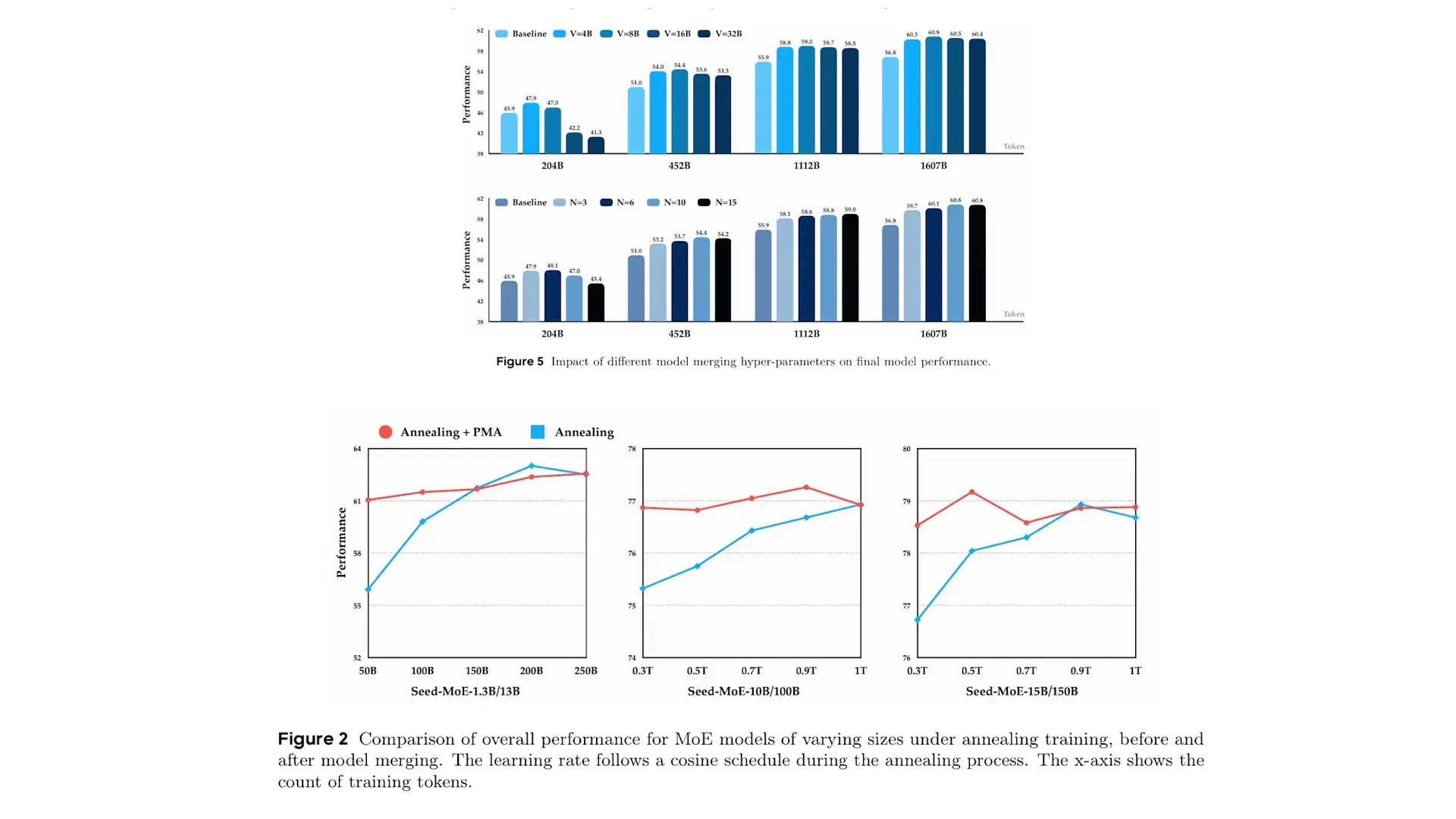
The results are remarkable: the merged model can match or even exceed the performance of models that have gone through the full annealing process (where learning rates are gradually reduced). This technique can save approximately 15% of compute budget and 3-6 days of training time while providing a 3-7% accuracy boost.
How Model Merging Works
A typical pre-training cycle follows a pattern: a warm-up period, a long stable phase with constant learning rate, and finally an annealing phase where the learning rate gradually decreases. The annealing phase has traditionally been considered essential for fine-tuning parameters and improving model performance.
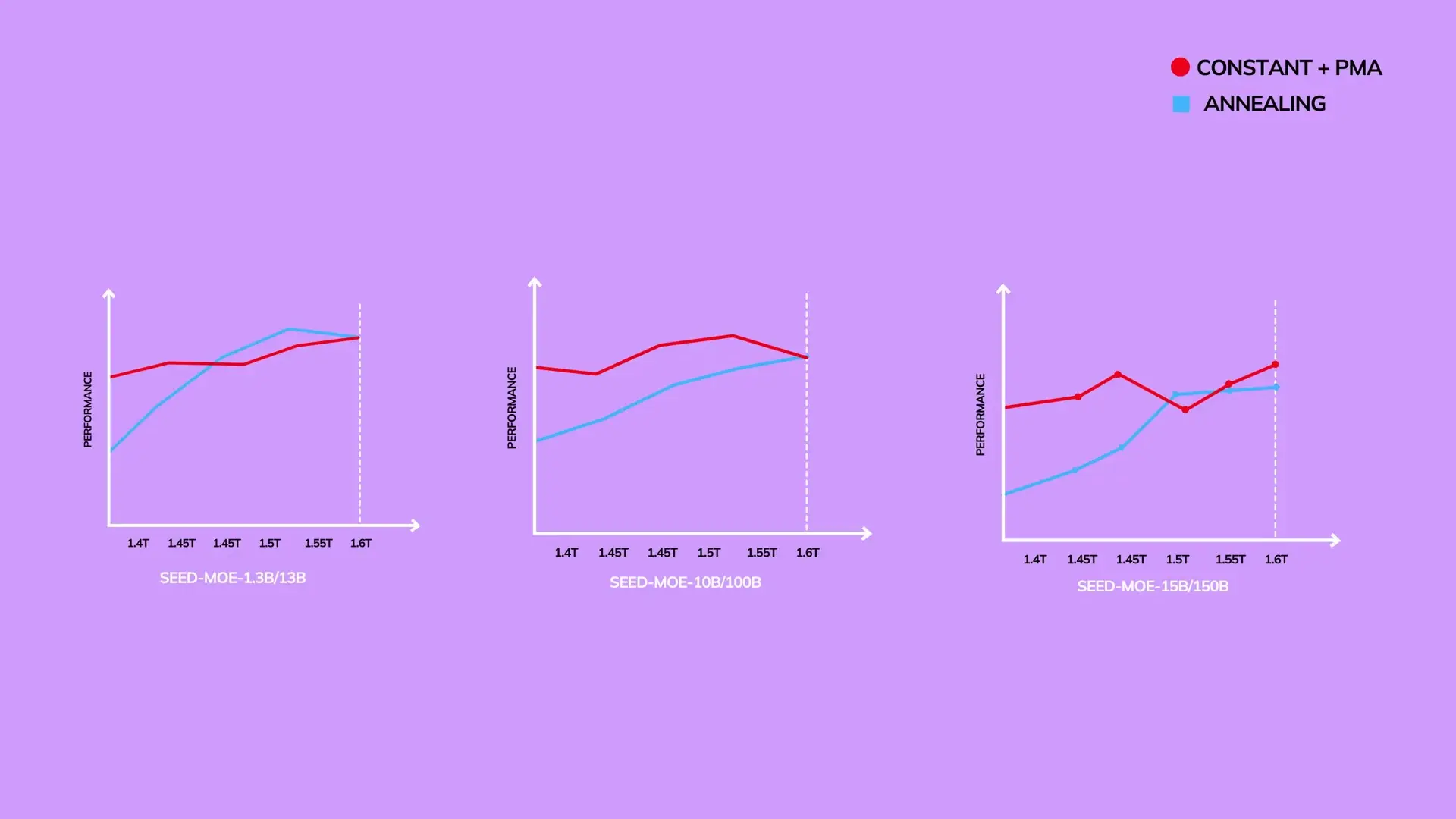
ByteDance's research challenges this assumption. By averaging checkpoints from the constant learning rate phase, they discovered that the resulting merged model immediately outperforms an annealed model. Only after approximately 1.5 trillion additional tokens of annealing does the traditionally annealed model catch up to the performance of the merged model.
The Science Behind Model Merging
The researchers tested three merging methods: Simple Moving Average (SMA), Exponential Moving Average (EMA), and Weighted Moving Average (WMA). Surprisingly, the simplest method—SMA, where all checkpoints are equally weighted—performed best.
This effectiveness can be explained by viewing the weights during constant learning rate training as a noisy signal with high-frequency oscillations gradually moving toward an optimal point. Annealing acts as a low-pass filter that dampens these oscillations iteratively. SMA achieves a similar effect in one shot, removing high-frequency noise by averaging out positive and negative deviations across checkpoints.
Practical Applications of PMA
- Cost reduction: Save 10-20% of training budget and time, especially valuable for hyperparameter sweeps and scaling law testing
- Early performance estimates: Get an accurate preview of final model quality without waiting for the full training cycle
- Crash recovery: If a loss spike derails training, merging the last few stable checkpoints can reset the model back on track
- Stabilization for noisy setups: Helps stabilize large batch or mixed precision training that can cause spiky iterations
- Distributed computing: Potential for periodic checkpoint averaging to smooth model noise across multiple workers
Extensive Testing Across Model Sizes
ByteDance demonstrated PMA's effectiveness across an impressive range of models, from 411 million to 70 billion parameters for dense models, and from 0.7B active/7B total to 20B active/200B total parameters for Mixture of Experts architectures. This extensive testing—potentially costing up to $15 million in GPU time—shows their commitment to validating this approach thoroughly.

Cost Implications for AI Research and Development
The financial implications of this research are substantial. For a 1.3B active/13B total parameter model, it would cost an extra $20,000 for an annealed model just to reach the performance level of a merged model. At larger scales, these savings multiply significantly.
By reducing the cost of pre-training experiments, PMA democratizes AI research, allowing smaller labs to conduct more extensive testing without prohibitive expenses. This could accelerate innovation in the field by enabling more diverse participants to contribute to fundamental AI research.
The Future of Cost-Efficient AI Training
As pre-training continues to be a crucial aspect of AI development, ByteDance's research on model merging is likely to have a significant impact on the field. The technique's ability to provide early performance estimates, free accuracy gains, and resilience to instability makes it a valuable tool for researchers and organizations looking to optimize their AI training processes.
What's particularly noteworthy is ByteDance's decision to publish these findings, effectively teaching everyone—including competitors—how to save millions of dollars in training costs. This open approach to research stands in contrast to the often secretive nature of AI development at major tech companies.
Conclusion
ByteDance's research on model merging represents a significant advancement in cost-efficient AI training. By demonstrating that simple averaging of checkpoints can match or exceed the performance of traditional annealing approaches, they've provided the AI community with a valuable technique for reducing training costs while maintaining or improving model quality.
As AI models continue to grow in size and complexity, techniques like PMA will become increasingly important for managing the astronomical costs associated with training state-of-the-art systems. ByteDance's willingness to share these insights may help level the playing field in AI research, allowing more organizations to participate in advancing the field without requiring Google or OpenAI-level budgets.
Let's Watch!
How ByteDance's Model Merging Technique Cuts AI Training Costs by Millions
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence