Chinese AI Model Qwen 3 Coder vs Claude 4 and Claude K2: Real-World Coding Challenge
Marcus Chen
Performance Engineer

The AI landscape continues to evolve rapidly with new models claiming benchmark superiority almost weekly. Among the latest contenders is Qwen 3 Coder, an open-source Chinese AI model that reportedly outperforms Claude K2 and rivals the capabilities of Claude 4, widely considered the leading model in the field. But do these benchmark claims translate to real-world performance? Let's find out through a practical coding challenge.
The Challenge: Building a YouTube-to-Blog Post Converter
To evaluate these models fairly, we designed a practical test: building a Next.js application that automatically generates blog posts from YouTube video transcripts. The app needed to analyze a user's writing style from three sample blog posts and then create new content from YouTube video transcripts that matches that style.
All three models—Claude K2, Qwen 3 Coder, and Claude 4—were given identical instructions through their respective platforms: Claude through a Pro subscription, Claude K2 through Moonshot Console, and Qwen 3 Coder through Open Reader.
Claude K2 Performance
Claude K2 approached the task methodically, creating a comprehensive plan before diving into implementation. It built the application in a logical sequence:
- Created a file to analyze blog posts
- Developed functionality to process YouTube video transcripts
- Built a component to display and download the finished blog post
- Completed the project with detailed documentation
The entire process took just under 10 minutes, resulting in a fully functional application. When tested with actual blog posts and a YouTube URL, the app successfully analyzed the writing style and generated a new blog post that matched the original tone and structure.
Qwen 3 Coder Performance
Qwen 3 Coder, the Chinese AI model, demonstrated impressive speed, completing the task in just over 5 minutes—approximately twice as fast as Claude K2. It quickly established requirements, installed dependencies, and built the core functionality.
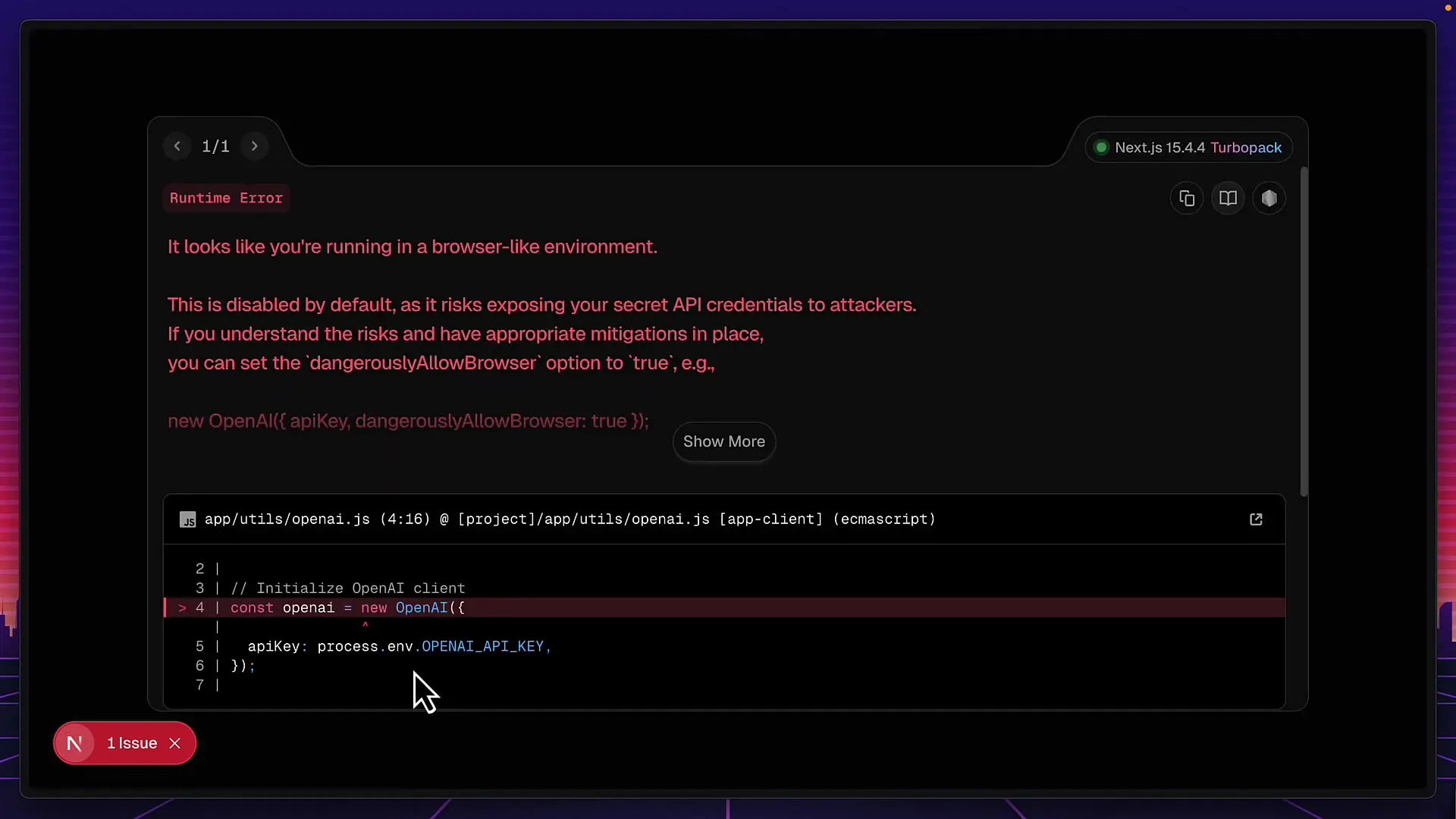
However, the application had several issues. First, it exposed API keys to the browser—a significant security concern. After manual fixes, further testing revealed that the file upload functionality was not properly implemented, requiring additional corrections. Even after these fixes, the app failed to properly extract YouTube transcripts.
Claude 4 Performance
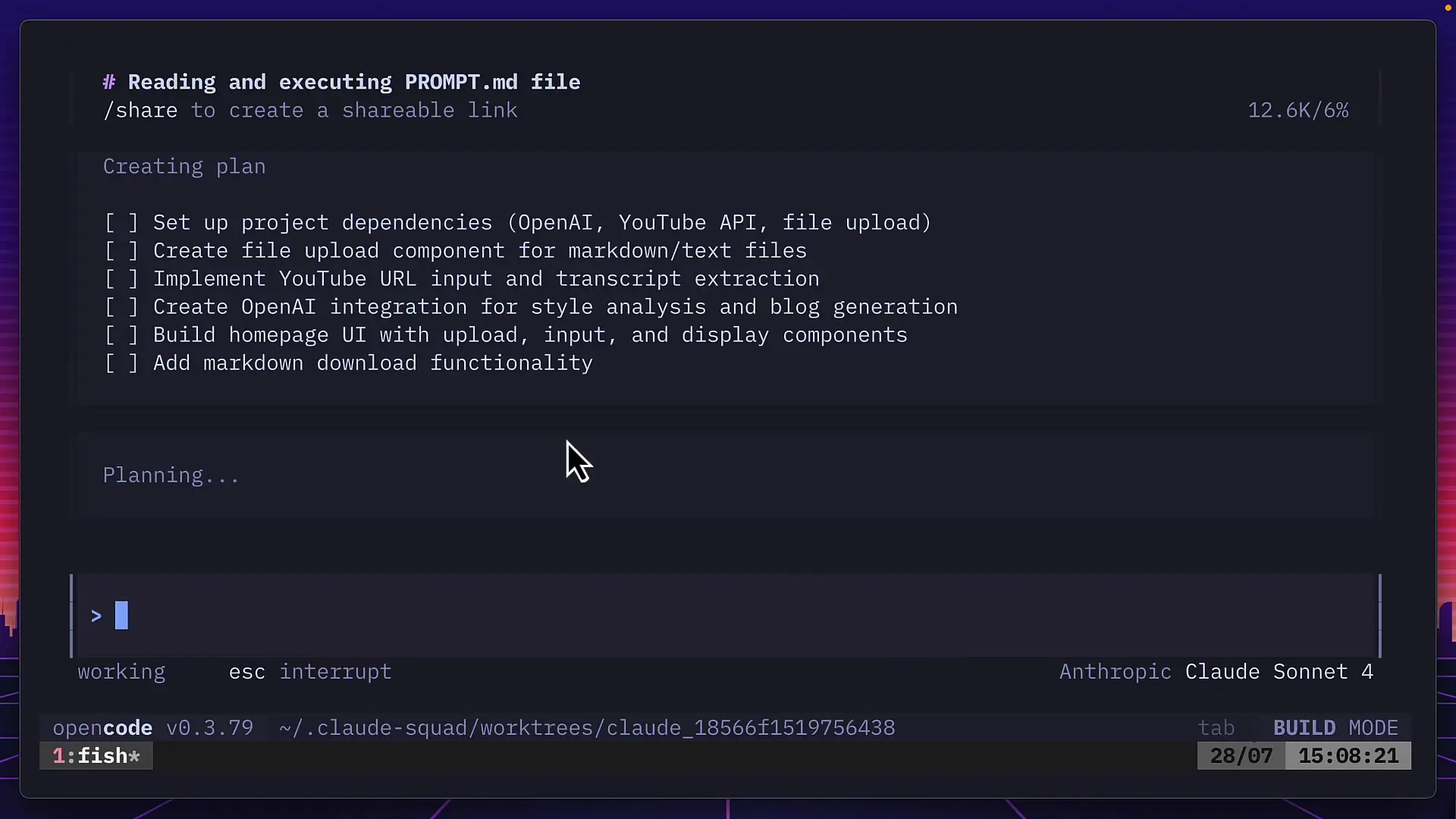
Claude 4, the supposed benchmark leader, completed the task in just over 3 minutes—the fastest of all three models. It created a well-structured plan, chose modern tools like Bun for dependency management, and implemented sophisticated prompting techniques for GPT-4 to extract information from blog posts.
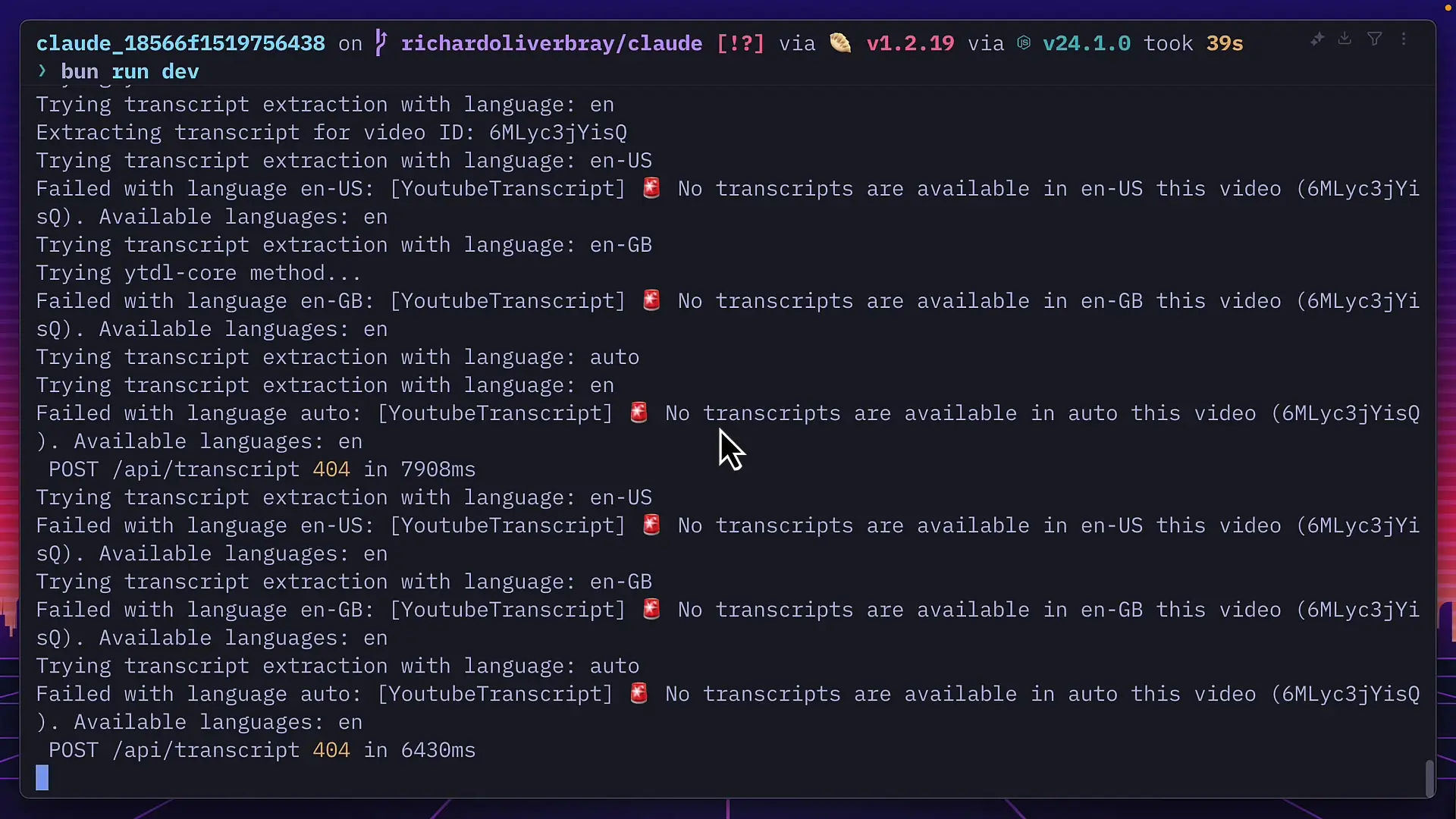
Despite its impressive speed and approach, Claude 4's application also encountered issues with YouTube transcript extraction. Even after troubleshooting attempts, it continued to report that no captions were available for the test video.
Benchmarks vs. Real-World Performance
This practical test reveals an important truth about AI models: benchmark results don't always translate to real-world performance. Despite Qwen 3 Coder's impressive benchmark claims and Claude 4's reputation as the leading model, Claude K2 was the only one to deliver a fully functional application without significant issues.
Several factors may influence real-world performance beyond what benchmarks capture:
- Environment and context sensitivity
- Prompt quality and specificity
- Task complexity and domain knowledge requirements
- Implementation approach and error handling capabilities
- Ability to debug and fix issues
Chinese AI Models in the Global Landscape
Qwen 3 Coder represents China's growing influence in the AI space. While it demonstrated impressive speed and capabilities, this test suggests that Chinese AI models, like their Western counterparts, have specific strengths and weaknesses depending on the task at hand.
The rapid development of Chinese AI technology is narrowing the gap with Western models, but real-world application testing reveals that benchmark superiority doesn't necessarily translate to better practical performance across all scenarios.
Cost Considerations
An important factor in model selection is cost. While Claude K2 was slower than both Qwen 3 Coder and Claude 4, it's significantly cheaper to use, making it potentially more suitable for smaller, less complex tasks where budget is a concern.
For more complex projects where performance and reliability are critical, investing in a more powerful model like Claude 4 may be justified, despite its higher cost.
Conclusion: The Right Tool for the Job
This comparison demonstrates that AI model selection should be based on specific use cases rather than benchmark results alone. Claude K2, despite being theoretically less capable, delivered the most reliable solution for this particular task. Meanwhile, both the Chinese AI model Qwen 3 Coder and Claude 4 fell short despite their impressive benchmark results.
For developers and businesses leveraging AI for practical applications, this suggests a pragmatic approach: test multiple models on your specific tasks, consider the cost-performance tradeoff, and remember that the "best" model on paper may not always be the best choice for your particular needs.
As AI technology continues to evolve rapidly, with new models emerging from both Chinese and Western organizations, maintaining a flexible, task-oriented approach to model selection will likely yield the best results.
Let's Watch!
Chinese AI Model Qwen 3 Coder vs Claude 4: Real-World Performance Test
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence