How Google's Context Caching Implementation Can Reduce Your LLM API Costs by Up to 90%
Priya Narayan
Systems Architect

As Large Language Models become more powerful and context windows grow larger, API costs can quickly skyrocket with increased usage. For developers working with LLMs at scale, finding cost optimization strategies is crucial. Enter context caching - a technique that can reduce your LLM API costs by up to 90% while potentially serving as an alternative to Retrieval Augmented Generation (RAG) for smaller document sets.
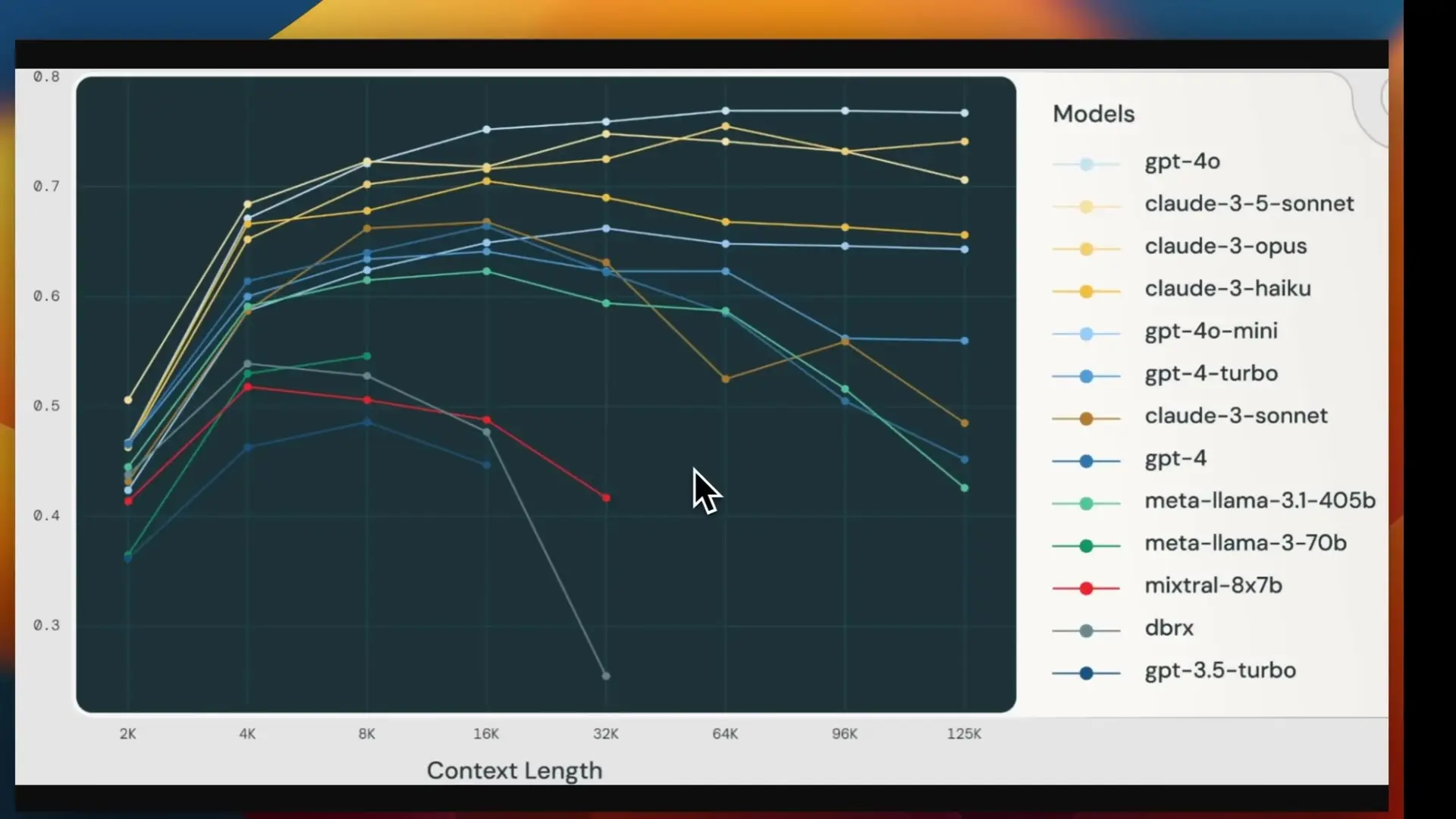
What is Context Caching and Why Does it Matter?
Context caching is a technique implemented by major LLM API providers including Google, Anthropic, and OpenAI that allows you to store prompt content (context) and reuse it across multiple API calls without paying the full token cost each time. This is particularly valuable when users interact repeatedly with the same large documents.
The benefits of context caching include:
- Significant cost reduction (up to 75-90% depending on the provider)
- Faster response times due to pre-processed content
- Simplified architecture compared to RAG for certain use cases
- Elimination of vector store overhead (indexing, storage, maintenance)
- Support for multimodal content including images and text
Context Caching vs. RAG: When to Use Each
While Retrieval Augmented Generation (RAG) has become the standard approach for enabling LLMs to work with external data, context caching offers an intriguing alternative for specific scenarios. Here's when you might consider context caching over RAG:
- When working with relatively small document sets (that fit within context windows)
- For short-term user interactions with specific documents
- When users repeatedly query the same document(s)
- To avoid the complexity of setting up vector stores and embeddings
- When working with multimodal content like scanned documents
RAG still remains preferable for large document collections, permanent knowledge bases, and when semantic search capabilities are essential.
Cost Comparison: Cached vs. Non-Cached Tokens
The primary motivation for implementing context caching is cost reduction. Let's look at the savings you can expect with Google's Gemini models:
- Gemini 2.5 Pro: Approximately 75% cost reduction for cached tokens vs. non-cached tokens
- Gemini 2.0 Flash: Similar savings profile
- Gemini 2.5 Flash: Context caching coming soon
It's important to note that there is an additional storage cost for cached tokens, measured in tokens stored per hour. For the Pro version, this is approximately $4.50 per million tokens per hour. This makes it essential to consider both how many tokens you're caching and for how long.
Implementing Context Caching with Google's Gemini API
Google's implementation of context caching offers more control compared to OpenAI and Anthropic. Let's walk through a practical implementation using Python and the Google Generative AI package.
Step 1: Install Required Packages
pip install google-generativeaiStep 2: Setup the Gemini Client
import google.generativeai as genai
import os
# Configure API key
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
# Initialize the model client
model = genai.GenerativeModel("gemini-2.0-flash")
Step 3: Create a Cache with Your Document
# Define system instructions
system_instruction = "You are an expert at summarizing documents."
# Create the cache
cache = model.create_cache(
configurations={
"system_instruction": system_instruction
},
contents=[
{"file_path": "document.pdf"} # Or other content you want to cache
]
)The document can be a PDF, image, or text file. For PDFs and images, Gemini will use its multimodal capabilities to process the content, which works well even with scanned documents.
Step 4: Interact with the Cached Content
# Configure request to use the cache
config = genai.generation_config.GenerationConfig(
cache=cache.name
)
# Make a request using the cached content
response = model.generate_content(
"Provide a concise summary of the document.",
generation_config=config
)
print(response.text)When you make this request, you'll only be charged for the new input tokens (your query) and the output tokens (the model's response), not for the cached document tokens. This is where the substantial cost savings come from.
Step 5: Manage Your Cache
Google's implementation offers several helpful functions for cache management:
# List all available caches
caches = model.list_caches()
for c in caches:
print(c.name)
# Update cache duration (time to live in seconds)
cache.update(ttl_seconds=300) # Set to 5 minutes
# Delete the cache when done
cache.delete()By default, caches expire after 1 hour if no TTL (time to live) is specified. For cost efficiency, it's best to set this to the minimum time needed for your use case and delete caches when they're no longer required.
Advanced Use Case: In-Context Learning with Cached Documentation
Beyond simple document interaction, context caching enables powerful in-context learning scenarios. For example, you can cache technical documentation and then have the model create new implementations based on that documentation.
Here's an example using GitHub repository documentation:
# Install gitingest for processing GitHub repos
pip install gitingest
# Process a GitHub repo into LLM-ready format
from gitingest import GitIngest
repo_content = GitIngest().ingest_repo(
"https://github.com/username/repo",
include_file_extensions=[".py", ".md"]
)
# Create cache with the repository documentation
cache = model.create_cache(
configurations={
"system_instruction": "You are an expert Python developer."
},
contents=[repo_content]
)
# Use the cached knowledge to generate new code
response = model.generate_content(
"Create a new implementation of X based on the documentation.",
generation_config=genai.generation_config.GenerationConfig(cache=cache.name)
)
Implementation Considerations and Best Practices
To get the most out of context caching while managing costs effectively, consider these best practices:
- Set appropriate TTL values: Longer caching means higher storage costs, so set TTL to match your expected usage patterns.
- Monitor token usage: Track both the input/output tokens and the cached tokens to optimize costs.
- Delete caches proactively: When a user session ends or a document is no longer needed, delete the cache to avoid unnecessary storage costs.
- Consider document size: For very large documents, evaluate whether splitting into multiple caches or using RAG might be more cost-effective.
- Cache system instructions: If you have complex system prompts, consider caching those along with your documents to further reduce token usage.
Provider Comparison: Google vs. OpenAI vs. Anthropic
While this article focuses on Google's implementation, it's worth noting the differences between major providers:
- Google Gemini: Offers the most control over cache management with explicit create/update/delete functions and configurable TTL. Initially required 32,000 tokens to cache but now works with as few as 4,000 tokens.
- OpenAI: Implements prompt caching with less granular control but similar cost benefits.
- Anthropic: Offers prompt caching with Claude models, focusing on simplicity over configurability.
Conclusion: Is Context Caching Right for Your Use Case?
Context caching represents a powerful optimization technique that can dramatically reduce LLM API costs for specific use cases. While it doesn't replace RAG for all scenarios, it offers a compelling alternative when working with smaller document sets, multimodal content, or when implementing in-context learning.
The implementation is straightforward, especially with Google's Gemini API, and the cost benefits can be substantial. By carefully managing your caches and understanding the tradeoffs between caching duration and storage costs, you can achieve significant savings while maintaining or even improving your application's performance.
As LLM applications continue to scale and evolve, techniques like context caching will become essential tools in the developer's toolkit for building cost-effective AI solutions.
Let's Watch!
How Context Caching Can Slash Your LLM API Costs by 90%
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence