Decoding GPT: Understanding How Transformer Architecture Powers Modern AI Language Models
Jamal Washington
Infrastructure Lead

The remarkable capabilities of modern AI language models like GPT (Generative Pre-trained Transformer) have transformed how we interact with technology. But what exactly does GPT stand for, and how does this technology work beneath the surface? This comprehensive guide breaks down the architecture that powers these sophisticated language models.
Understanding GPT: Breaking Down the Acronym
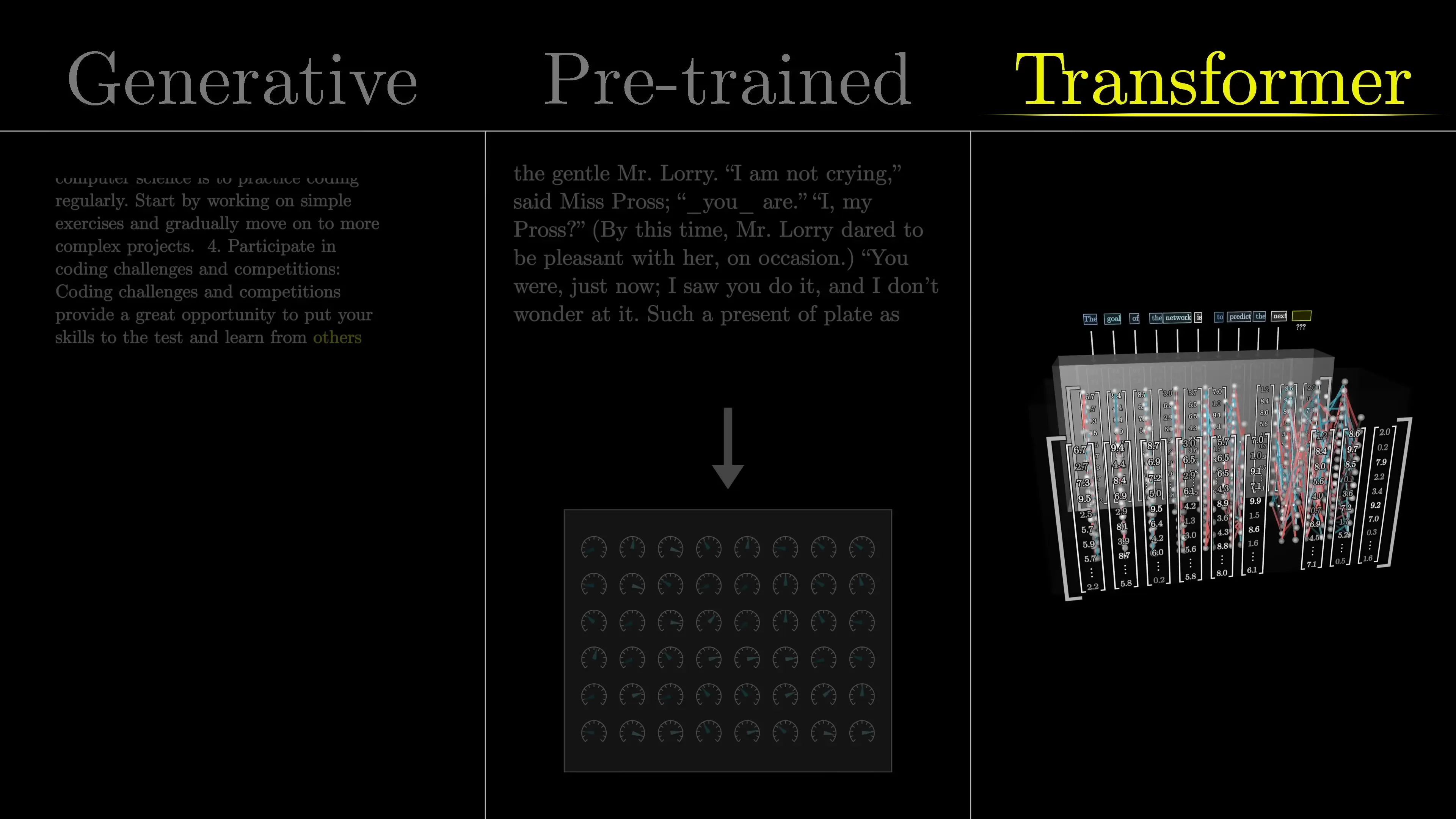
GPT stands for Generative Pre-trained Transformer, and each component of this name reveals something important about how these models function:
- Generative: These models generate new content, whether that's text, code, or other forms of output.
- Pre-trained: Before deployment, these models undergo extensive training on massive datasets, allowing them to learn patterns and relationships within language.
- Transformer: This refers to the specific neural network architecture that forms the foundation of these models—the true innovation behind their capabilities.
The Versatility of Transformer-Based Models
Transformer architecture has proven remarkably versatile, powering a wide range of AI applications beyond just text generation:
- Speech recognition models that convert audio to text
- Text-to-speech systems that generate natural-sounding voices
- Image generation tools like DALL-E and Midjourney that create images from text descriptions
- Language translation systems that maintain context and nuance
- Conversational AI assistants that can maintain coherent dialogues
While the original Transformer was designed specifically for language translation in 2017, the architecture has proven adaptable to numerous tasks requiring pattern recognition and contextual understanding.
How Language Models Generate Text
At their core, models like GPT are next-token prediction systems. They take in a sequence of text and predict what comes next, generating a probability distribution across all possible next tokens (words or word pieces). This seemingly simple task—predicting what comes next—is what enables these models to generate coherent, contextually relevant text.
The generation process follows these steps:
- The model receives an initial prompt or seed text
- It predicts the most likely next token (word or word piece)
- It samples from this probability distribution to select a specific token
- The selected token is appended to the existing text
- This new, longer text becomes the input for the next prediction
- The process repeats until the desired length is reached or a stopping condition is met
This iterative process explains why larger models like GPT-3 and GPT-4 produce more coherent text than smaller predecessors—they've been trained on more data and have more parameters, allowing them to maintain context and coherence over longer sequences.
Inside the Transformer: Data Flow and Processing
Let's explore how data actually flows through a Transformer model when generating text:
1. Tokenization
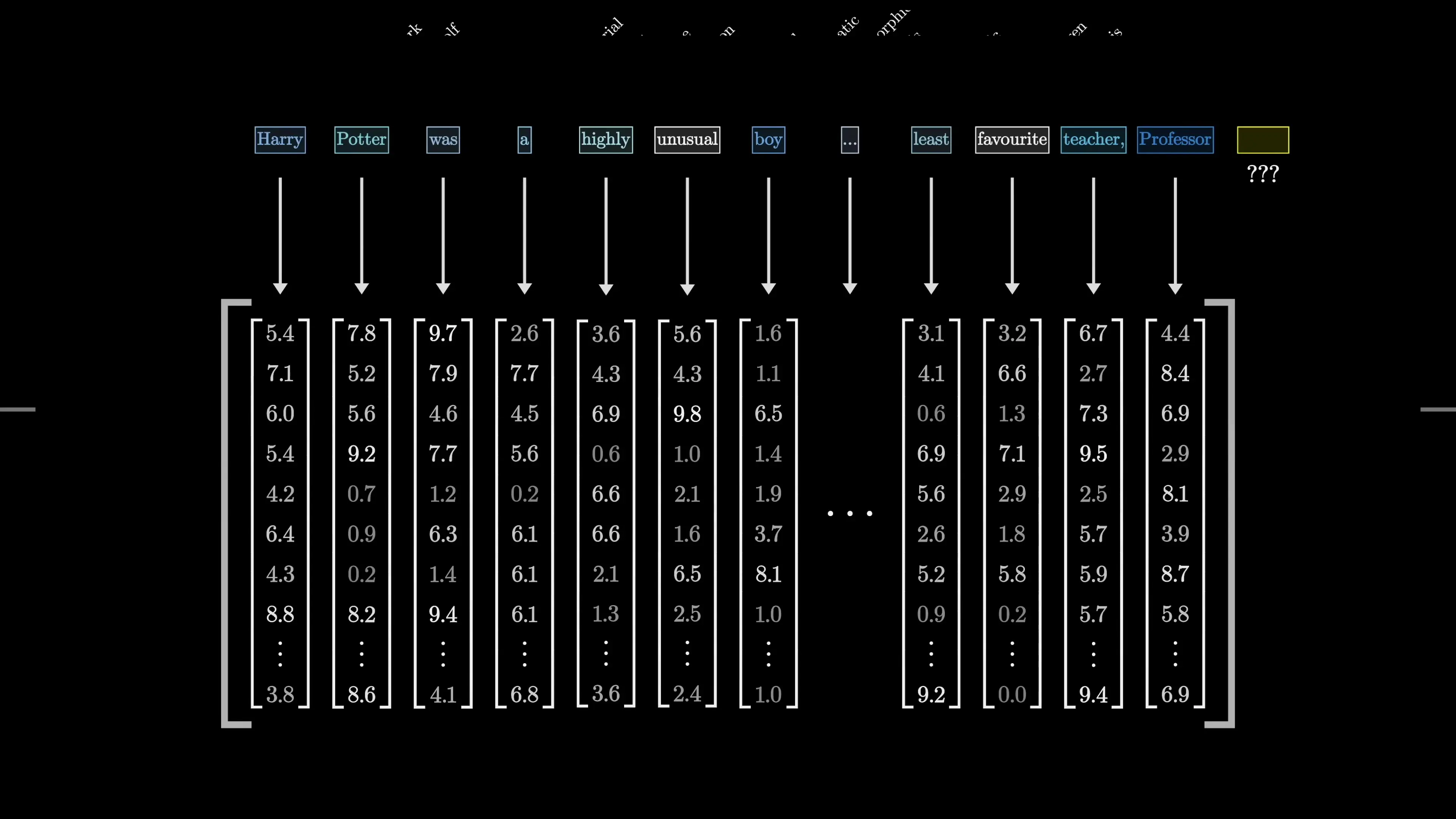
The input text is first broken into tokens—typically words, parts of words, or common character combinations. For example, the word "understanding" might be broken into "under" and "standing" as separate tokens. This tokenization process creates the basic units that the model will process.
2. Embedding Vectors
Each token is converted into a vector—essentially a list of numbers that represents that token in a high-dimensional space. Words with similar meanings tend to have vectors that are close to each other in this space. For instance, "dog" and "puppy" would have similar vector representations.
3. Attention Blocks
These vectors then pass through attention blocks, which are the defining feature of Transformer models. Attention allows each token to "look at" and be influenced by other tokens in the sequence. This is crucial for understanding context—for example, recognizing that the meaning of "bank" differs in "river bank" versus "bank account."
The attention mechanism determines which other words in the context are relevant for interpreting each specific word, allowing the model to capture relationships between distant words in a sentence.
4. Feed-Forward Networks
After the attention block, each token's vector passes through a feed-forward neural network (sometimes called a multi-layer perceptron). Unlike the attention block where tokens interact with each other, in this step each token is processed independently but using the same transformation.
This step can be thought of as asking a series of questions about each token's meaning and updating that meaning based on the answers.
5. Repeated Processing
Steps 3 and 4 repeat multiple times in what are called "layers" of the Transformer. Each layer refines the representation of the tokens, with deeper layers capturing increasingly complex patterns and relationships. Larger models like GPT-4 have more layers than smaller predecessors.
6. Output Projection
After passing through all the layers, the final vector for the last token is used to generate a probability distribution over all possible next tokens. The model then either selects the most likely token or samples from this distribution to determine what comes next.
From Next-Word Prediction to Chatbots
Converting a next-token prediction model into a conversational assistant like ChatGPT requires an additional step. The model is given a system prompt that establishes the context of a conversation between a user and an AI assistant. This prompt might contain instructions about how the assistant should behave.
When a user asks a question, it's appended to this system prompt, and the model predicts what a helpful assistant would say next. This prediction becomes the AI's response. The conversation history is maintained and used as context for future predictions, allowing for coherent multi-turn dialogues.
Why Scaling Matters in Language Models
One of the most fascinating aspects of these models is how dramatically their capabilities improve with scale. A small model using the same architecture might produce text that's grammatically correct but nonsensical, while a larger model with more parameters can generate coherent, contextually appropriate responses that appear to demonstrate understanding.
This scaling effect comes from three main factors:
- More parameters (the adjustable values in the model)
- Larger training datasets
- More computational resources for training
The difference between GPT-2 and GPT-3, for example, isn't primarily architectural—it's that GPT-3 is much larger, with 175 billion parameters compared to GPT-2's 1.5 billion. This increased scale allows the model to capture more complex patterns and relationships in language.
Training: How These Models Learn
Training a Transformer model involves two main phases:
Pre-training
During pre-training, the model is exposed to vast amounts of text from the internet, books, and other sources. It learns to predict the next word in a sequence, gradually adjusting its parameters to minimize prediction errors. This phase requires enormous computational resources but results in a model with broad knowledge about language patterns.
Fine-tuning
After pre-training, models are often fine-tuned on more specific datasets for particular tasks. For chatbots like ChatGPT, this includes fine-tuning with human feedback (RLHF—Reinforcement Learning from Human Feedback) to make responses more helpful, harmless, and honest.
This two-phase approach allows these models to develop broad language capabilities during pre-training while being optimized for specific applications during fine-tuning.
Limitations and Future Directions
Despite their impressive capabilities, current Transformer-based language models have several limitations:
- They can generate plausible-sounding but factually incorrect information
- They lack true understanding of the world and causal relationships
- They can exhibit biases present in their training data
- They have fixed knowledge cutoffs based on when they were trained
- They struggle with certain types of reasoning and mathematical problems
Future developments in this field are likely to address these limitations through multimodal models (combining text, images, audio), better grounding in factual knowledge, and improved reasoning capabilities. The core Transformer architecture will likely continue to evolve, but its fundamental principles have proven remarkably effective and versatile.
Conclusion
The Transformer architecture represents one of the most significant advances in artificial intelligence in recent years. By understanding how these models process and generate text—breaking input into tokens, converting them to vectors, applying attention mechanisms, and predicting probable next tokens—we gain insight into both their capabilities and limitations.
As these models continue to evolve and improve, they will likely become even more integrated into our digital experiences, transforming how we interact with technology and information. Understanding their inner workings helps us better appreciate both their remarkable achievements and the challenges that remain in developing truly intelligent systems.
Let's Watch!
Decoding GPT: How Transformer Architecture Powers Modern AI Language Models
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence