How DeepSeek Revolutionized Transformer Architecture with Multi-Head Latent Attention (MLA)
Sophia Okonkwo
Technical Writer

In January 2025, the AI research landscape witnessed a seismic shift when Chinese company DeepSeek released their R1 model. This highly competitive language model operates with only a fraction of the computational resources required by leading competitors. Even more remarkably, DeepSeek has publicly released the R1 model weights, inference code, and extensive technical documentation - a stark contrast to the closed approach of many American counterparts.
Behind DeepSeek's breakthrough lies a revolutionary technique called Multi-Head Latent Attention (MLA), introduced in June 2024. This innovation doesn't merely tweak the margins of existing AI frameworks - it fundamentally reimagines the core architecture of the Transformer, the computational backbone powering virtually all modern language models.
The Transformer Architecture: Understanding the Foundation
To appreciate DeepSeek's innovation, we must first understand how traditional Transformer models work. At their core, Transformers generate text one token (word fragment) at a time, with each new token being influenced by all tokens that came before it through a mechanism called attention.
Attention works by computing matrices called attention patterns. These patterns determine how information flows between different token positions in the model. For context, GPT-2 Small computes 144 attention patterns (12 attention heads per layer × 12 layers), while DeepSeek R1 computes a staggering 7,808 patterns (128 attention heads per layer × 61 layers).

The Mathematics Behind Attention Mechanisms
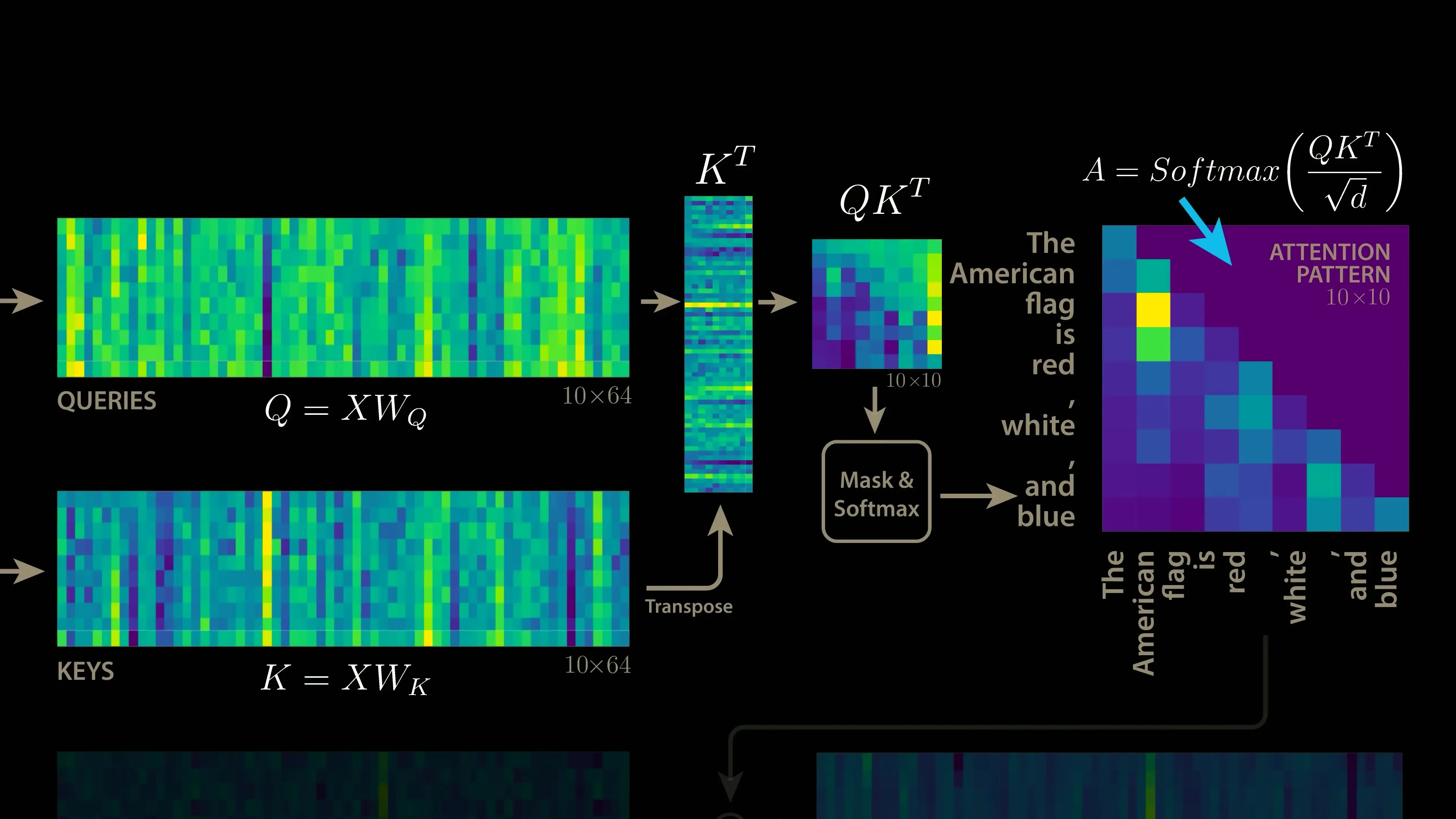
The standard attention mechanism in Transformer models involves several matrix operations. First, the input matrix X is multiplied by learned weight matrices WQ and WK to produce query (Q) and key (K) matrices. The dot product of these matrices creates an attention pattern that identifies relationships between tokens.
For example, in processing the phrase "The American flag is red white and," certain attention heads might focus on connecting the adjective "American" to the noun "flag," while others might connect "flag," "red," and "white" to predict the next token ("blue").
After computing the attention pattern, the model applies a masking operation, normalizes the result, and uses it to process data through a third weight matrix WV that creates a value (V) matrix. The final output is produced by multiplying the attention pattern by the value matrix and then by a final weight matrix WO.
The Computational Challenge: Scaling Attention
The computational complexity of attention becomes problematic as context lengths grow. Since attention patterns scale quadratically with the number of tokens (N² complexity), models like ChatGPT with 100,000+ token context windows face enormous computational demands - equivalent to computing relationships between every word pair in an entire book.
Key-Value Caching: The Traditional Solution
Language models traditionally address this challenge through key-value (KV) caching. Since models generate text one token at a time, most of the computation can be reused across generation steps. When generating a new token, only the final row of the query matrix changes, while previous keys and values remain constant.
By storing (caching) previously computed keys and values in memory, models only need to compute new keys and values for the most recent token, significantly reducing computational overhead during text generation.
DeepSeek's Multi-Head Latent Attention (MLA): The Breakthrough
DeepSeek's revolutionary Multi-Head Latent Attention (MLA) technique addresses a critical bottleneck in traditional Transformer architectures: the size of the key-value cache. In standard models, this cache grows linearly with both context length and model size, creating memory constraints that limit inference speed and efficiency.
MLA introduces a crucial innovation by projecting the high-dimensional key and value vectors into a much lower-dimensional latent space. This projection dramatically reduces the memory footprint of the KV cache while preserving the model's ability to capture complex relationships between tokens.
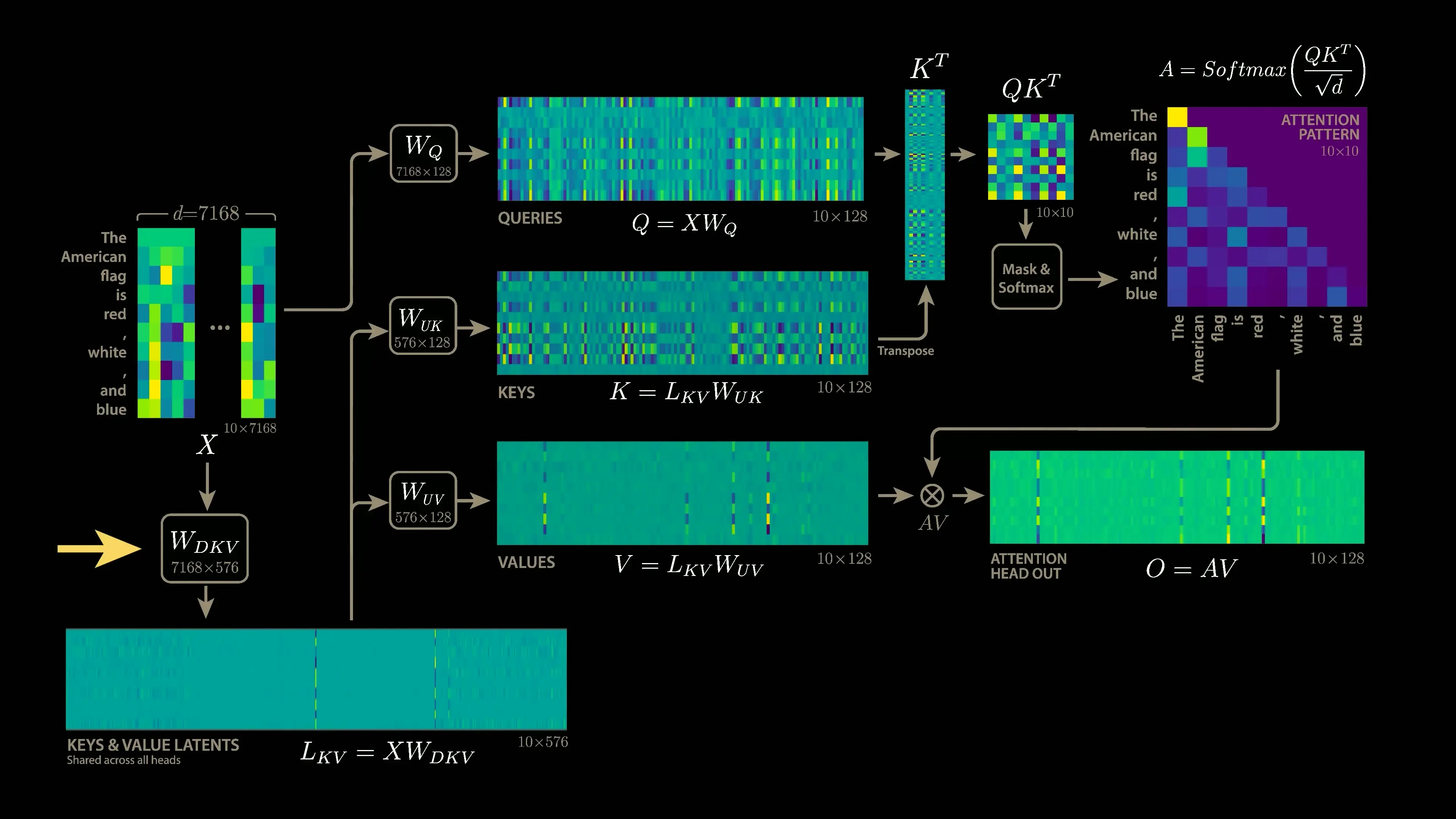
Technical Implementation of MLA
The MLA architecture introduces additional projection matrices that compress the key and value vectors before storing them in the cache. During inference, these compressed vectors are decompressed on-the-fly as needed. This approach reduces the KV cache size by an impressive factor of 57, enabling the model to generate text more than six times faster than traditional Transformer implementations.
- Project high-dimensional key/value vectors to low-dimensional latent space
- Store compressed vectors in the KV cache
- Decompress vectors on-demand during inference
- Maintain attention mechanism functionality with drastically reduced memory requirements
Benefits of DeepSeek's MLA Transformer Architecture
- 57x reduction in key-value cache size
- 6x faster text generation compared to traditional Transformers
- Improved memory bandwidth utilization
- Enhanced scalability for long-context applications
- Reduced hardware requirements for deployment
Implications for the Future of Transformer Architecture
DeepSeek's Multi-Head Latent Attention represents a fundamental advancement in Transformer architecture that could reshape the AI landscape. By dramatically reducing memory requirements while maintaining or improving performance, MLA enables more efficient deployment of large language models across a wider range of hardware configurations.
This innovation is particularly significant for applications requiring long context windows, such as document analysis, complex reasoning tasks, and conversational AI. The reduced computational requirements also make advanced AI capabilities more accessible to researchers and developers with limited computing resources.
Comparing MLA to Traditional Multi-Head Attention (MHA)
While traditional Multi-Head Attention (MHA) has been the standard in Transformer models since their inception, DeepSeek's MLA offers several advantages that address key limitations of the original architecture:
- MHA stores full-dimensional key and value vectors, while MLA compresses them into a latent space
- MHA's memory requirements scale linearly with model size and context length, creating bottlenecks for large models
- MLA maintains attention functionality while dramatically reducing memory footprint
- MLA enables more efficient inference without sacrificing model capabilities
Conclusion: DeepSeek's Contribution to Transformer Evolution
DeepSeek's Multi-Head Latent Attention represents one of the most significant advancements in Transformer architecture since its introduction. By addressing the fundamental memory bottleneck of key-value caching, DeepSeek has created a more efficient foundation for large language models that could accelerate AI development across the industry.
The public release of DeepSeek's R1 model, complete with weights, code, and technical documentation, further demonstrates the company's commitment to advancing open research in AI. As researchers and developers implement and build upon MLA, we can expect to see a new generation of more efficient, capable, and accessible language models emerge.
Let's Watch!
How DeepSeek Revolutionized Transformer Architecture with Multi-Head Latent Attention
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence