The Diffusion LLM Revolution: How This New Architecture Is Solving AI's Speed Problem
Sophia Okonkwo
Technical Writer

AI-based applications currently face a major challenge: painfully long wait times. While large language models (LLMs) need time to think and generate responses, this delay becomes even more pronounced in AI-agentic applications. The limited solutions available—using simpler models or investing in better hardware—are either insufficient or inaccessible to most users. However, a promising architecture is emerging that could revolutionize AI response times: the diffusion language model (diffusion LLM).
The Rise of Commercial Diffusion LLMs
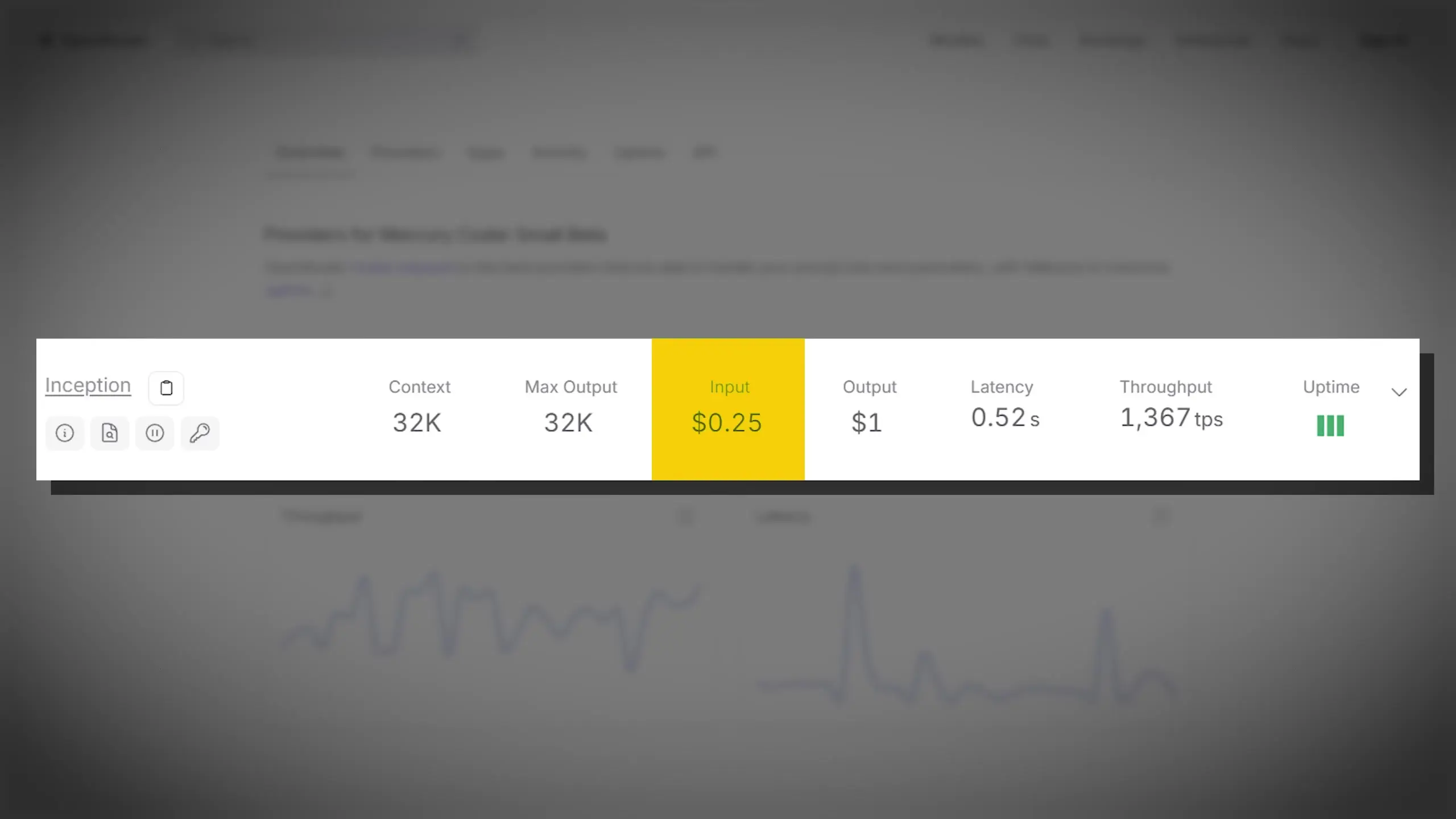
In February, Inception Labs released the first commercially-ready diffusion LLM called Mercury Coder. Their mini model demonstrated impressive capabilities, generating up to 1,190 tokens per second—five times faster than competing models like Gemini 2.0 Flashlight and Qwen 2.5 Coder 7B. More recently, Google DeepMind entered the arena with Gemini Diffusion, which achieves nearly 1,500 tokens per second with a 32K token context window.
How Diffusion LLMs Differ from Auto-Regressive Models
Unlike traditional auto-regressive models that generate text from left to right, diffusion language models start with a fully masked sequence and progressively denoise it over multiple iterations. This process resembles image diffusion but operates on discrete tokens rather than continuous pixel values. At each step, the model predicts a subset of masked positions in parallel, replacing them until the entire sequence is revealed.
This non-auto-regressive approach leverages bidirectional or even global context, making diffusion LLMs particularly effective for structured or logical tasks. While the underlying architecture still relies on transformers, the denoising method allows for parallel processing that dramatically increases generation speed.
Performance Comparison: Diffusion vs. Auto-Regressive LLMs
Current benchmarks show that diffusion LLMs excel in specific domains while still catching up in others. Mercury Coder matches or slightly exceeds baseline models in code generation tasks, with particularly impressive results in fill-in-the-middle benchmarks where it outperforms competitors by 22-30% in accuracy.
- Mercury Coder: ~800 tokens per second on H100 GPU
- Gemini Diffusion: ~1,500 tokens per second
- Fastest auto-regressive service: ~331 tokens per second
- Custom hardware solutions (e.g., Cerebras): ~2,522 tokens per second, but at much higher cost
In the Copilot Arena benchmark for code autocompletion quality, Mercury ranks sixth, though this benchmark primarily includes older models. When compared to contemporaries like GPT-3.5 and Qwen 2.5 Coder, diffusion LLMs appear to be approximately 8-10 months behind private models and only about 3 months behind open-source models in the coding domain.
Current Limitations of Diffusion LLMs
Despite their speed advantages, diffusion LLMs still face challenges. Google's benchmarks show that Gemini Diffusion falls behind Gemini 2.0 Flashlight in language and reasoning tasks, with notable gaps in areas like GPQA accuracy (16% lower), multilingual QA (10% lower), and general reasoning (6% lower). The model only shows a slight advantage in mathematical reasoning with 3% higher performance.
These performance gaps may reflect the current focus on coding data rather than indicating fundamental limitations of the diffusion approach. Additionally, open-source diffusion LLMs face optimization challenges with KV cache management, meaning downloadable models won't immediately achieve the advertised 1,000+ tokens per second without significant tuning.
The Promising Future of Diffusion LLMs
Recent research suggests diffusion LLMs may have distinct advantages in data-scarce, compute-rich scenarios. The same dataset can provide up to 25 times more learning signals to diffusion LLMs compared to traditional auto-regressive models. This efficiency could accelerate progress as researchers explore higher confidence thresholds, additional denoising iterations, larger model sizes, and optimized hyperparameters.
Multimodal applications represent another promising frontier for diffusion LLMs, where their parallel processing capabilities could offer significant advantages over sequential generation methods. As commercial APIs become more widely available, developers will have increasing opportunities to incorporate these ultra-fast models into responsive applications.

Practical Applications for Developers
For developers looking to leverage diffusion LLMs in their applications, several options are emerging. Mercury Coder is currently available through Inception Labs' API with pricing at 25 cents per million tokens input and $1 per million tokens output. Google's Gemini Diffusion is available through a waitlist program, with wider access expected in the coming months.
These models are particularly well-suited for applications requiring rapid response times, such as code completion tools, interactive chatbots, and real-time content generation systems. The dramatic speed improvements could transform user experiences in AI-powered applications, eliminating the frustrating wait times that currently plague many LLM implementations.
Conclusion
Diffusion language models represent a significant advancement in AI text generation, offering unprecedented speed while maintaining competitive quality in specific domains. While they haven't yet matched the reasoning capabilities of leading auto-regressive models across all tasks, their rapid evolution suggests they may soon close this gap.
As research continues and commercial implementations expand, diffusion LLMs could fundamentally change how we interact with AI systems. The days of waiting for AI responses may soon be behind us, opening new possibilities for responsive, real-time AI applications that feel truly interactive rather than merely assistive.
Let's Watch!
Diffusion LLM Revolution: Solving the AI Speed Problem
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence