Energy-Based Transformers: The Revolutionary AI Paradigm That's Changing Machine Learning
Jamal Washington
Infrastructure Lead

The current crown of language models is the reasoning paradigm, which outputs additional words to better predict what comes next. While empirically proven to improve generation accuracy, the approach lacks elegance - models simply receive rewards based on final outcomes rather than through a structured reasoning process. This creates significant challenges in scaling and verification, particularly for domains without systematic ways to check results.
Introducing Energy-Based Transformers
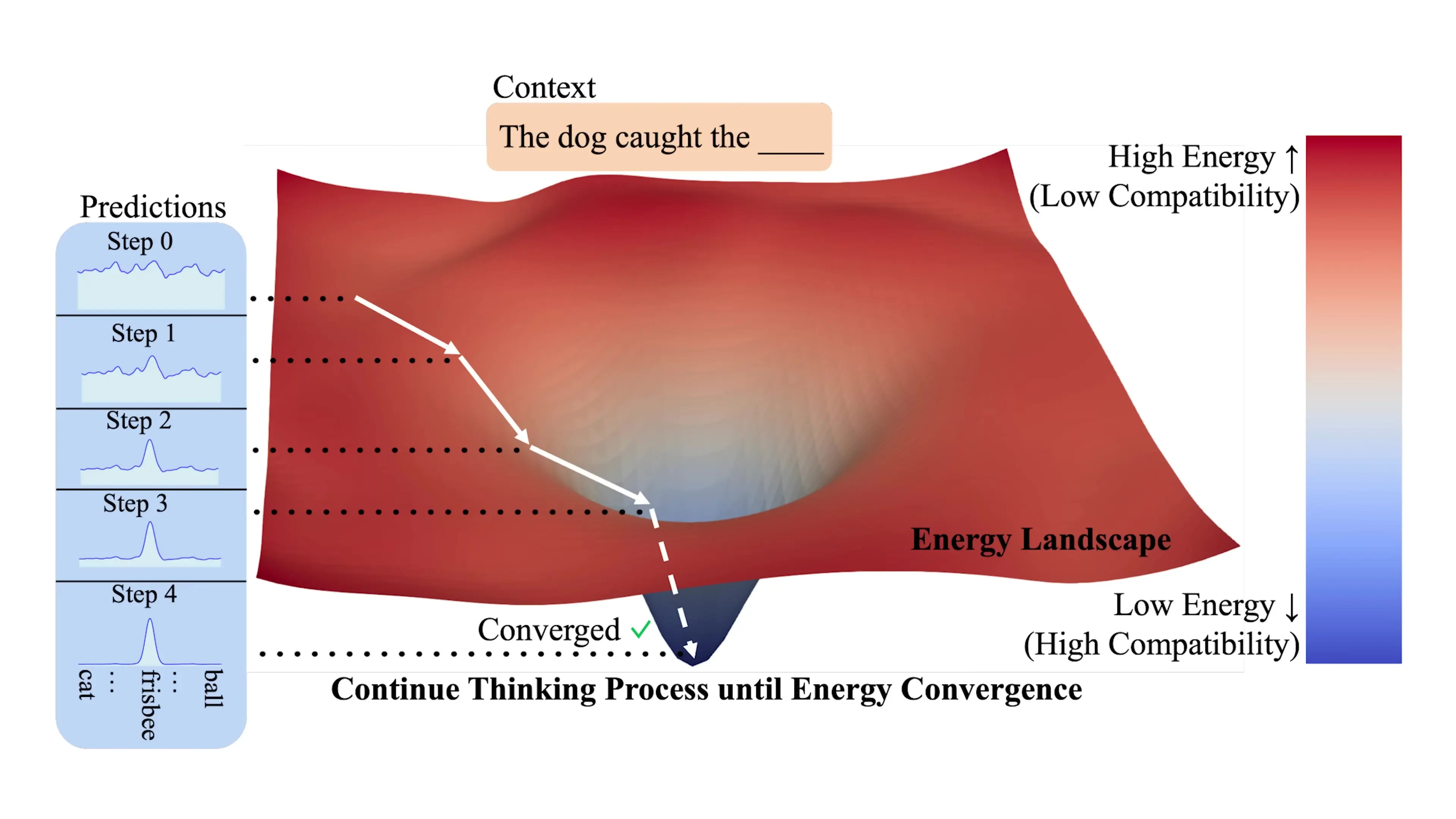
A new paradigm called Energy-Based Transformers (EBT) proposes a fundamentally different approach. Rather than learning to generate directly, EBTs use an energy-based model (EBM) that learns to generate by optimizing predictions using a learned verifier - the energy function. This shift represents a potential revolution in how AI models think and generate content.

How Energy-Based Transformers Work
In standard language models, next token prediction involves the network outputting probabilities for every possible token simultaneously, then selecting the token with the highest probability. EBT takes a different approach:
- It starts with a random token embedding as a blank slate
- The model measures how "wrong" this feels with its energy score
- It repeats this process iteratively, gradually refining its prediction
- Finally, it selects the token with the lowest energy (highest probability)
This iterative mechanism means EBT spends more compute per token than standard methods, but this can be dynamically adjusted during inference. When a token needs more thought, EBT can allocate more thinking time for that specific token - eliminating the need to measure entropy for dynamic compute allocation that many reinforcement learning approaches require.
Comparing EBT to Other AI Models
The iterative process of EBT bears resemblance to diffusion models, but with a crucial difference. Diffusion models follow a fixed schedule requiring hundreds of tiny steps, with the full answer only appearing at the end. EBT, by contrast, lets the model steer itself - after making an initial guess, it checks the energy gradient to find the direction toward a better answer, iteratively descending to a low-energy solution.
EBT also shares similarities with Generative Adversarial Networks (GANs). In GANs, two separate models exist - a generator that creates content and a discriminator that judges it. They learn by pushing against each other. EBT unifies this "artist and critic" paradigm into a single model, where the network itself provides the judgment score (energy) and polishes its guess iteratively until the energy is low enough.
Technical Implementation
Researchers have implemented EBT using transformer architectures. They created a decoder-only energy-based transformer using the GPT architecture that outputs an energy scalar instead of softmax logits. They also developed a bidirectional EBT similar to BERT and diffusion transformers. The key modification is replacing the standard softmax prediction head with a single scalar energy head, with each symbol obtained through gradient descent steps on the energy surface.
Performance and Scaling Advantages
Early research shows promising results for EBT. While classic transformers still perform better in many contexts, EBT shows steeper improvement curves when scaling training data, batch size, and model depth. This suggests that at larger scales, EBT might become more efficient at the same compute budget.
A particularly interesting advantage is EBT's ability to reduce perplexity at the token level by running additional forward passes. After just three forward passes, EBT's perplexity drops below that of standard transformers, with further improvements at 6, 15, and 30 passes. This scalability of "thinking" is straightforward - simply increase the number of forward passes during inference.
Out-of-Distribution Performance
Perhaps the most exciting finding is EBT's potential for better generalization to domains it wasn't explicitly trained on - the holy grail of AI development. Researchers observed that as data becomes more out-of-distribution, thinking in EBT leads to greater performance improvements. In downstream benchmarks, EBT outperforms classic transformers even while underperforming in pre-training tasks, suggesting better generalization capabilities.
Visualizing Token Energy
Researchers have created visualizations showing energy levels for different predicted tokens. Simple tokens like periods, "is", "a", "but" have consistently lower energies across thinking steps, indicating low uncertainty. More complex tokens like "quick", "brown", "research", and "problem" show higher energies and more difficulty achieving energy convergence, indicating greater model uncertainty.
Image Denoising Performance
For image denoising tasks, bidirectional EBT shows remarkable efficiency. The energy falls sharply within the first three forward passes, producing cleaner images that outperform diffusion transformers after their full 300-step schedule - representing a 99% improvement in efficiency.
Challenges and Limitations
Despite its promise, EBT faces significant challenges:
- Generation is at least three times slower than standard transformers due to the iterative process
- Higher memory usage requirements
- Training difficulties, especially for high-entropy token positions where many tokens might equally contest the same position
- Maintaining a smooth energy surface for effective gradient descent adds complexity
These challenges raise questions about whether EBT will scale effectively beyond trillion-token training regimes, but the initial results are promising.
Conclusion
Energy-Based Transformers represent a fascinating new direction in AI research that unifies verification and generation into a single model. While still in early stages, the approach shows particular promise for out-of-distribution tasks and offers an elegant solution to dynamic compute allocation. The trade-off of increased inference time may be worthwhile for applications requiring higher accuracy, especially in domains where verification is challenging.
As researchers continue exploring this paradigm, we may see EBT become increasingly competitive with - or even surpass - traditional transformer architectures, particularly at scale and for complex reasoning tasks. This represents yet another exciting development in the rapidly evolving field of AI model architectures.
Let's Watch!
Energy-Based Transformers: The Revolutionary AI Paradigm Explained
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence