GPT-5 Coding Abilities: What Benchmarks Reveal About Its True Performance
Jamal Washington
Infrastructure Lead

When Sam Altman claimed that GPT-5 possesses PhD-level coding abilities, it sparked both excitement and skepticism within the developer community. While some programmers report remarkable experiences with the model, others find its performance surprisingly underwhelming—sometimes claiming it's not significantly better than GPT-4. This disconnect between official claims and user experiences deserves deeper investigation, especially since GPT-5 reportedly outperforms previous models on standard benchmarks.
Key Coding Benchmarks for Evaluating GPT-5
To objectively assess GPT-5's coding capabilities, we need to examine its performance across established benchmarks that the AI research community uses to evaluate large language models. These benchmarks provide standardized testing environments that allow for fair comparisons between different models.
1. SWEBench: Real-World GitHub Issues
SWEBench (Software Engineering Benchmark) presents one of the most realistic testing environments, featuring over 2,200 actual GitHub issues from popular open-source Python repositories. This benchmark tests how models perform on real-world programming challenges rather than contrived examples.
SWEBench Verified, a subset containing 500 high-quality human-verified tasks, provides an even more reliable assessment. On a fixed subset of 477 tasks, GPT-5 achieved an impressive one-try success rate of nearly 75% when using its thinking capabilities.
For fair comparison on the official SWEBench leaderboard using the Mini SWE agent infrastructure:
- Claude 4 Opus: 67.6% success rate
- GPT-5 (with medium reasoning): 65% success rate
- Claude 4 Sonnet: 64.93% success rate
When looking at the full test containing all 2,294 tasks with bash-only results using the Mini SWE agent, Claude 4 Opus leads slightly, followed by GPT-5, then Claude 4 Sonnet.
2. ADA Polyglot Benchmark: Multi-Language Proficiency
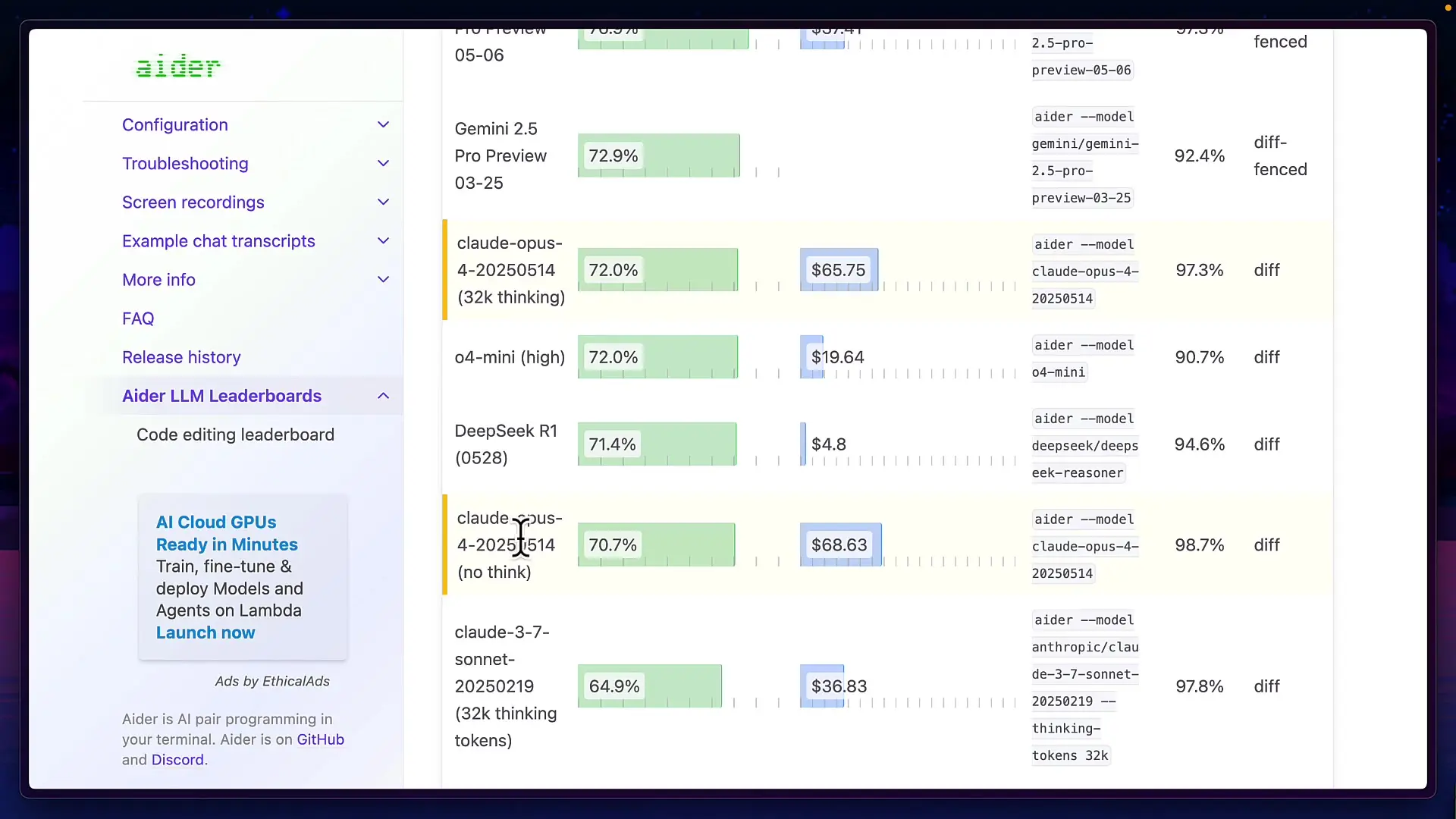
The ADA Polyglot benchmark focuses on evaluating models across multiple programming languages—hence the name "polyglot." It contains 225 questions based on Exercism's hardest coding problems across six different programming languages, testing versatility and depth of coding knowledge.
While the official leaderboard hasn't been updated with GPT-5 results yet, preliminary data shows impressive performance. OpenAI claims GPT-5 with thinking capabilities scores 88% with a two-attempt pass rate. For comparison, the current leaderboard shows:
- O3 Pro: Nearly 85% success rate
- Claude 4 Opus (with thinking): 72% success rate
- Claude 4 Opus (without thinking): Lower than 72%
These results suggest GPT-5 is highly competitive, though we should await official verification from the ADA Polyglot maintainers for confirmation.
3. LiveCodeBench: Testing on Unseen Problems
LiveCodeBench offers perhaps the most challenging test environment, as it continuously collects new questions from competitive programming platforms like LeetCode, AtCoder, and CodeForces. Unlike other benchmarks, LiveCodeBench specifically filters questions based on model training cutoff dates to evaluate performance on truly unseen problems.

LiveCodeBench v6 contains over 1,000 coding problems categorized by difficulty (easy, medium, and hard) and measures different capabilities including code generation, self-repair, and test output prediction.
While OpenAI hasn't published official LiveCodeBench statistics for GPT-5, third-party evaluations from Valve AI indicate that GPT-5 Mini actually outperforms both GPT-5 and Claude 4 Opus in terms of combined performance and speed. The official LiveCodeBench leaderboard still places O4 above Claude Opus.
Why GPT-5 Might Feel Underwhelming Despite Strong Benchmarks
Given these impressive benchmark results, why do some developers report that GPT-5 doesn't feel like a significant upgrade? The answer may lie in how GPT-5 is actually implemented. Rather than being a single model, GPT-5 appears to function as a system with a sophisticated real-time router that directs prompts to different specialized models.

This routing system analyzes each prompt and directs it to the most appropriate model in real-time. For simple coding tasks, GPT-5 might route to a more basic model that provides just the requested solution without additional insights or optimizations. This behavior contrasts with dedicated coding models that might overdeliver on simple tasks, providing extra features, optimizations, or explanations that weren't explicitly requested.
In other words, GPT-5 is all about data-driven efficiency. When you ask for something simple, it gives you exactly that—nothing more, nothing less. This efficiency-focused approach may explain why GPT-5 can be offered at a lower price point than might be expected for such a powerful system.
GPT-5 Parameters and Features: Understanding the System
While specific details about GPT-5's parameters remain proprietary, the benchmark results suggest significant improvements over GPT-4. However, it's important to understand that raw parameter count isn't necessarily the best indicator of performance. The architecture, training methodology, and system design play equally important roles.
Key features that distinguish GPT-5 include:
- Intelligent routing system that directs queries to specialized models
- Enhanced reasoning capabilities that improve performance on complex coding tasks
- Better understanding of context and programming concepts
- Improved ability to work across multiple programming languages
- More efficient resource utilization, allowing for competitive pricing
GPT-4 Limitations vs. GPT-5 Improvements
GPT-4 demonstrated impressive coding capabilities but still faced notable limitations that GPT-5 attempts to address:
- Context understanding: GPT-4 sometimes missed subtle requirements or constraints in complex coding problems. GPT-5 shows improved comprehension of problem specifications.
- Debugging capabilities: GPT-4 could identify obvious errors but struggled with complex debugging scenarios. Benchmark results suggest GPT-5 performs better at self-repair tasks.
- Language versatility: While GPT-4 was proficient in popular languages, it showed uneven performance across the programming language spectrum. GPT-5's improved scores on polyglot benchmarks indicate more consistent cross-language capabilities.
- Solution optimization: GPT-4 often produced functional but not optimal solutions. GPT-5 appears to generate more efficient code when the task requires it.
Practical Implications for Developers
For developers considering whether to upgrade to GPT-5 for coding assistance, these insights suggest a nuanced approach:
- For complex, challenging programming tasks, GPT-5 likely offers meaningful improvements over previous models
- For routine coding tasks, the difference may be less noticeable due to the routing system
- Being explicit about expectations and requirements in prompts may help trigger the more advanced capabilities
- Consider the cost-efficiency ratio: GPT-5 may offer better value despite some users perceiving minimal improvements for simple tasks
Conclusion: Is GPT-5 Truly PhD-Level at Coding?
The benchmark results largely support the claim that GPT-5 represents a significant advancement in AI coding capabilities. However, the real-world experience depends heavily on how developers interact with the model and what tasks they're trying to accomplish.
GPT-5 is all about data-driven responses, optimizing for both accuracy and efficiency. This approach means it excels at complex, well-defined tasks while potentially seeming unremarkable for simpler ones. The intelligent routing system that makes GPT-5 more efficient may ironically be contributing to the perception that it's not dramatically better than its predecessors.
As with any tool, understanding GPT-5's strengths, limitations, and design philosophy is key to leveraging its capabilities effectively. Benchmark results provide valuable objective measures, but practical application remains the ultimate test of any AI system's usefulness.
Let's Watch!
GPT-5 Coding Abilities: Benchmarks Reveal Hidden Performance Insights
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence