Inside LLMs: A Visual Breakdown of How Large Language Models Actually Work
Sophia Okonkwo
Technical Writer

Large Language Models (LLMs) like GPT-4, Claude, and Deepseek often seem like magical digital brains with an almost supernatural understanding of language. But beneath the seemingly intelligent responses lies a surprisingly focused mechanism: these models are essentially extremely sophisticated next-token predictors. In this deep dive, we'll explore exactly how LLMs work, breaking down their architecture to understand what makes these systems so powerful.
The Basic Building Blocks of LLMs
At their foundation, LLMs process text through a series of well-defined steps. When you enter a prompt, the model first tokenizes your text—breaking it into smaller chunks that might be words, parts of words, or individual characters. These tokens are then converted into vector embeddings, which are essentially numerical representations that the model can mathematically process.
Before entering the core processing components, these vectors pass through layer normalization. This crucial step keeps number values under control as they flow through dozens of processing layers, preventing them from becoming too large or too small, which would make training unstable. The model learns two additional parameters during this process—gamma and beta—which fine-tune how much these values are stretched or shifted.
The Transformer: The Heart of Modern LLMs
Once normalized, the embeddings enter the transformer block—the true engine of modern LLMs. Inside this block, each token creates three key vectors:
- Query: Represents what a token is searching for
- Key: Represents how the token describes itself
- Value: Represents the information that the token provides
The model compares queries to keys using mathematical dot products, generating similarity scores that determine how much attention each token should pay to every other token. This mechanism is called self-attention.
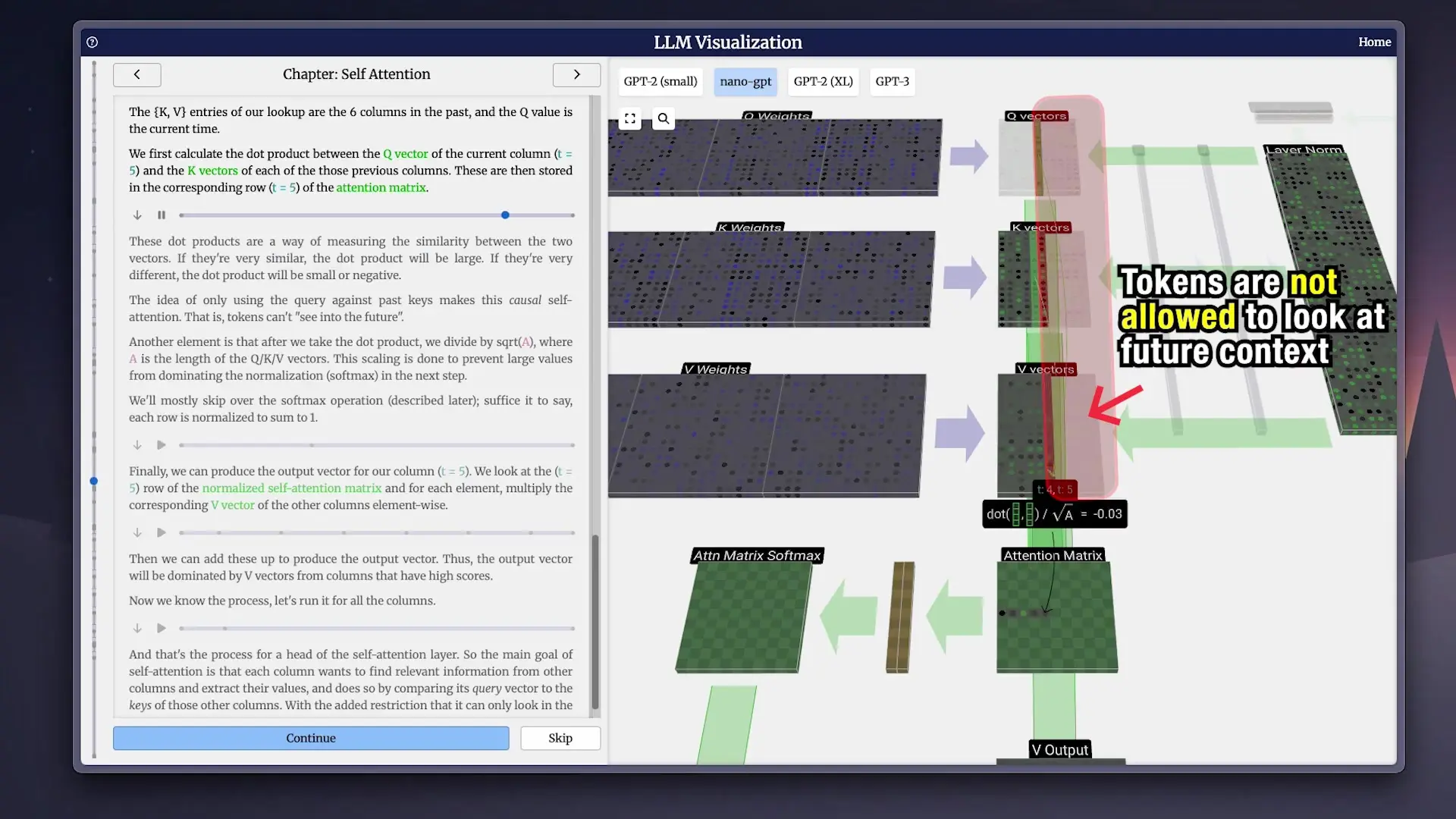
A critical aspect of GPT models is that they use causal self-attention, meaning each token can only look at previous tokens in the sequence—no peeking ahead. When predicting the sixth word in a sentence, the model only sees words one through five. This constraint is what forces LLMs to generate text from left to right without cheating.
Multiple Attention Heads: Capturing Different Relationships
Modern LLMs don't just run a single attention calculation. Instead, they implement multiple attention mechanisms in parallel through structures called heads. Each attention head can focus on different types of relationships within the text:
- One head might capture grammatical structure
- Another might track long-range dependencies between distant words
- Others might focus on subtle word associations or semantic meaning
When these parallel processes complete, their outputs are combined, projected back to the original vector size, and added to the input through a residual connection. This shortcut helps preserve the original signal so the model maintains context throughout processing.
The Feed-Forward Network: Processing Individual Tokens
The second half of the transformer block contains a multi-layer perceptron (MLP), also called a feed-forward network. Unlike self-attention which connects information across different tokens, the MLP processes each token individually.
Here's how the MLP works:
- The token vector expands into a much larger size
- It passes through a non-linear activation function (typically GELU)
- The vector is projected back down to its original size
The non-linear activation function is critical—without it, the entire model would simply be one giant linear transformation incapable of capturing complex patterns. This expansion-activation-projection pipeline enables the MLP to create feature detectors—neurons that activate for particular patterns in the data.
Feature Detectors: The Golden Gate Bridge Example
In 2024, Anthropic researchers discovered a fascinating example of feature detectors in action. They identified a specific neuron in Claude that consistently activated when the Golden Gate Bridge was mentioned. This activation occurred not just with the exact phrase, but also when related topics like "San Francisco suspension bridge" appeared in the text.
When researchers artificially boosted this neuron's activation, Claude began obsessively mentioning the Golden Gate Bridge in responses, even when completely unrelated to the input. This modified version, dubbed "Golden Gate Claude," demonstrated how specific neurons can encode surprisingly concrete concepts.
Most neurons are polysemantic (juggling multiple concepts), making such clear single-concept neurons rare. This example illustrates how MLP layers can develop highly specific feature detectors through training.
Stacking Transformer Blocks: Building Depth and Power
A single transformer block isn't sufficient for sophisticated language understanding. Modern LLMs stack dozens or even hundreds of these blocks, with each layer building upon the previous one's processing:
- Early layers identify local features like grammar and word order
- Middle layers capture context and relationships between concepts
- Deeper layers represent abstract meaning, reasoning, and world knowledge
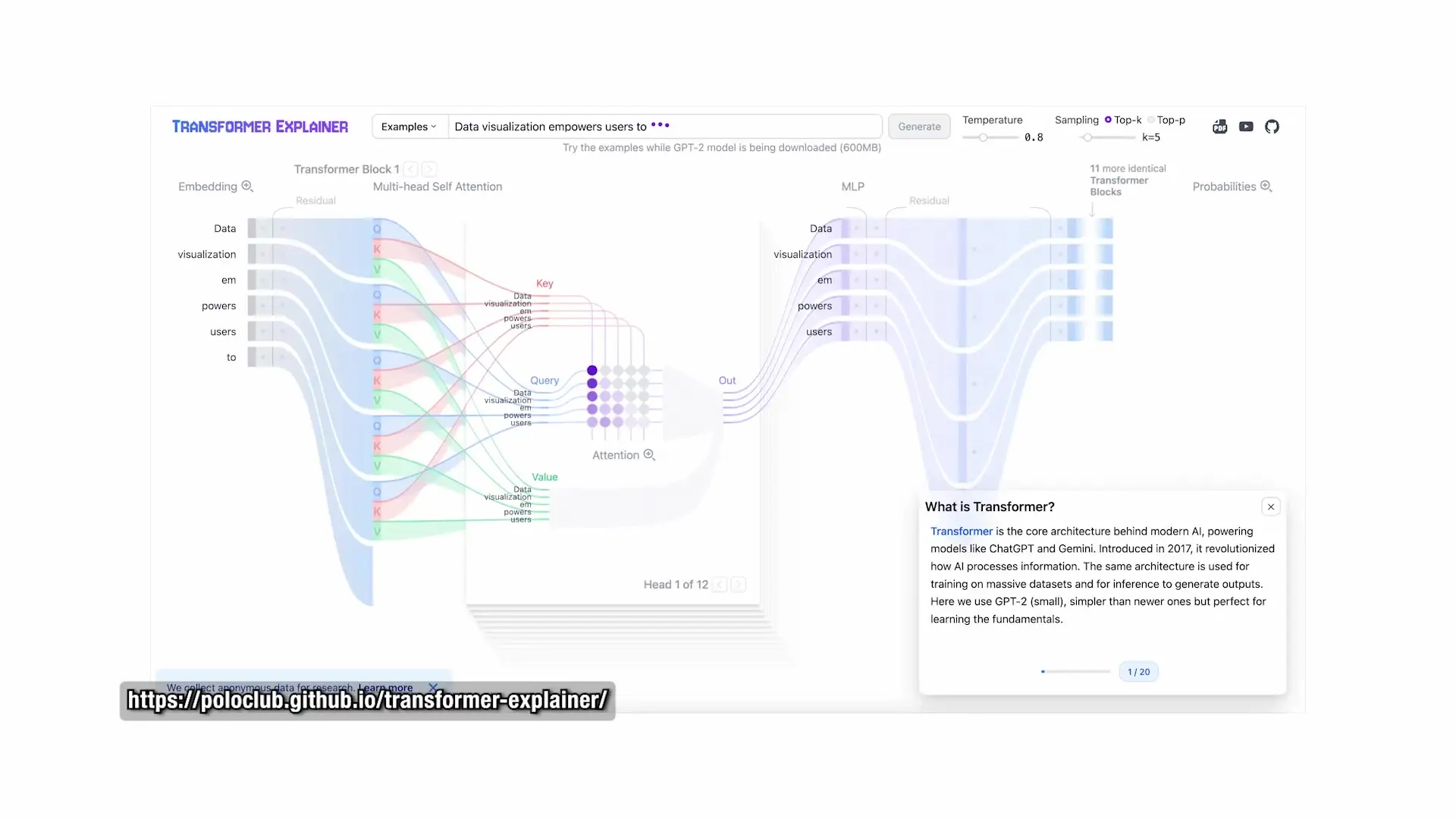
This hierarchical structure of stacked blocks gives transformers their impressive depth and capability. The scale of modern models is staggering—GPT-3 was already enormous, and newer models are orders of magnitude larger, with incomprehensible amounts of computation flowing through their layers.
From Vectors to Words: The Final Output
After processing through all transformer blocks, the final vectors are projected to match the size of the model's vocabulary. This produces a list of raw scores (logits) for each possible next token. To convert these scores into usable probabilities, the model applies a softmax function, which exponentiates and normalizes the values to create a probability distribution.
For example, the model might predict an 80% chance the next token is "cat," a 15% chance it's "dog," and a 5% chance it's "banana." The temperature setting allows users to control how deterministic these selections are:
- Low temperature: Model consistently selects the highest probability tokens (more predictable, focused responses)
- High temperature: Model more frequently selects lower probability tokens (more creative, diverse responses)
Recent Innovations in LLM Architecture
While the core transformer architecture from 2017 remains fundamental to modern LLMs, several optimizations have enhanced performance:

- Flash Attention: A technique that makes attention calculations faster and more memory-efficient
- Mixture of Experts (MoE): Specialized sub-networks where only a few activate per token, allowing for more efficient routing of different types of inputs
- Rotary Embeddings: An improved method for tracking word order, especially beneficial for long contexts
- SwiGLU Activations: A more flexible alternative to GELU that helps MLP layers train faster and capture richer patterns
The Not-So-Magical Reality of LLMs
What appears magical about large language models is actually an enormous stack of transformers performing countless mathematical operations to predict the next token in a sequence. The seemingly intelligent behavior emerges from this prediction capability, trained on vast amounts of text data.
With scale and smart engineering, these architectures produce systems that can generate coherent text, solve problems, and simulate understanding—all while fundamentally just predicting what word should come next.
Conclusion: The Math Behind the Magic
Understanding how LLMs work demystifies their capabilities while highlighting their impressive engineering. These models don't possess true understanding or reasoning—they're statistical prediction engines operating at massive scale. Yet through clever architecture and extensive training, they've become some of the most powerful and versatile AI tools available today.
As LLM technology continues to evolve, the core transformer architecture remains central to their function, with optimizations making them faster, more efficient, and more capable. What feels like magic is ultimately mathematics—an enormous amount of it—working together to predict the next word in your sentence.
Let's Watch!
Inside LLMs: How Large Language Models Actually Work Explained
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence