Inside Llama 4: Meta's Massive MoE Model and the Benchmark Controversy Explained
Eleanor Park
Developer Advocate

Meta has released Llama 4, a significant advancement in artificial intelligence that introduces a new architecture approach with massive mixture-of-experts (MoE) models. This release marks a substantial shift from previous iterations, focusing on models with enormous parameter counts but optimized for efficiency through selective parameter activation.
The New Llama 4 Model Lineup
Unlike previous releases, Llama 4 introduces three distinctly powerful models:
- Llama 4 Scout: A 109 billion parameter MoE model with 17 billion active parameters and 16 experts
- Llama 4 Maverick: A 400 billion parameter model with 17 billion active parameters and 128 experts
- Llama 4 Behemoth: A massive 2 trillion parameter model with 288 billion active parameters and 16 experts (still in training)
This represents a dramatic scaling compared to Llama 3's lineup of 8B, 70B, and 405B dense models. The current release includes Scout and Maverick, with Behemoth expected in a future Llama 4.1 update.
Understanding Mixture of Experts Architecture
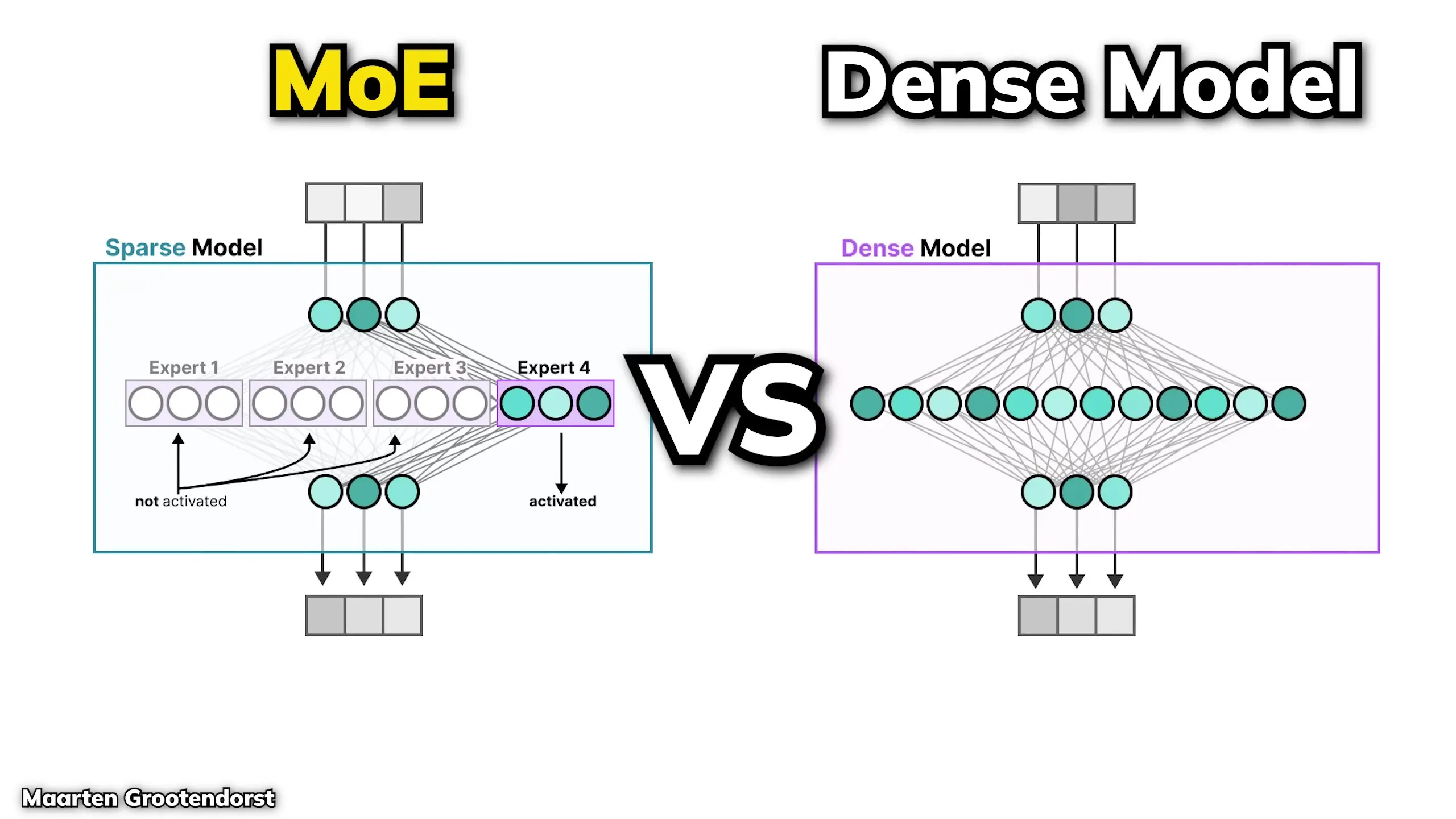
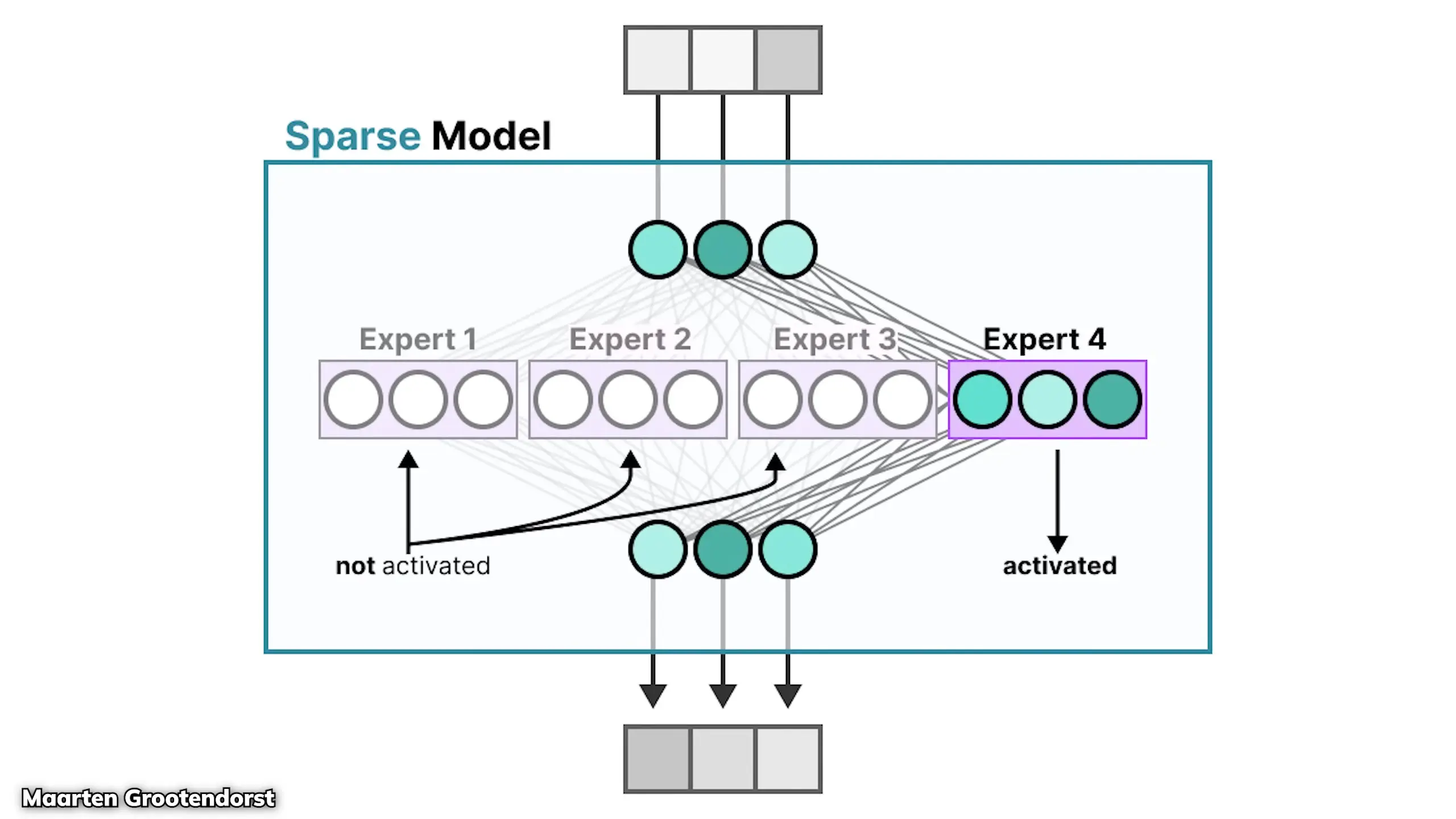
The mixture-of-experts architecture fundamentally changes how large language models process information. In traditional dense models, each token activates all parameters in the model. However, MoE models like Llama 4 only activate a fraction of the total parameters during processing.
This is achieved by having the model select from a collection of specialized feed-forward networks (the "experts") rather than using a single feed-forward block that's always activated. In Llama 4's implementation, only one expert and one shared expert are activated at a time, significantly reducing computational requirements while maintaining or improving performance.
Groundbreaking Context Window Capabilities
One of Llama 4's most impressive features is its context window size. The Scout model boasts a 10 million token context window—approximately 78 times larger than most open-source models. This is achieved through a new attention technique that enables processing of extremely long sequences.
Interestingly, despite being the larger model, Maverick doesn't share this 10M context window capability, suggesting that scaling this feature may be more challenging with larger models.
Multimodal Capabilities
Llama 4 models are multimodal, trained from the ground up with both text and images. However, unlike competitors such as Gemini and GPT-4o that can generate images, Llama 4 is currently limited to visual understanding only.
Benchmark Performance and Controversies

Meta's official benchmarks for Llama 4 look impressive on paper. The company reports an extraordinary 1417 ELO score on LM Arena, placing it second among all models and ahead of many closed-source competitors. However, these claims have sparked significant controversy in the AI community.
Independent testers have reported substantial discrepancies between Meta's claimed performance and actual results, particularly in several key areas:
- Instruction following: Both Scout and Maverick frequently fail to follow basic instructions
- Coding ability: On Aderbench, a respected coding benchmark, Llama 4 scored only 15.6%, significantly underperforming compared to competitors like DeepSeek
- Long context quality: Despite the massive context window, performance drops dramatically after the first 400 tokens on the Fiction Live Bench test
- Mathematical reasoning: While scoring well on Math 500, performance on Math Perturb (which tests generalizable mathematical reasoning) was poor
These inconsistencies have led to questions about Meta's benchmarking methodology. Some critics have pointed to the fine print in Meta's documentation, which notes that "LM Arena testing was conducted using a version of Llama 4 Maverick optimized for conversations"—suggesting the publicly released models may differ significantly from those used in benchmarks.
Allegations of Benchmark Manipulation
The controversy deepened with anonymous allegations that Meta may have trained on test data to achieve better benchmark results. While Meta researchers and executives have strongly denied these claims, the performance discrepancies have fueled skepticism.
Meta's VP of Gen AI stated that variable quality observed by users might be due to implementation or deployment errors rather than fundamental model issues. However, the practical evidence of underperformance continues to accumulate.
Implications for Developers
For developers looking to leverage Llama 4's capabilities, these controversies raise important considerations. While the models offer impressive theoretical capabilities—particularly the massive context windows—practical implementation may require careful evaluation and potentially extensive prompt engineering to achieve acceptable performance.
The poor coding performance is especially disappointing for developers who might have hoped to use Llama 4's extensive context window for code understanding and generation tasks. With a score of only 15.6% on Aderbench, the model's ability to write code appears significantly limited compared to competitors.
# Example of how Llama 4 might struggle with basic coding tasks
# Prompt: "Count the number of 'r's in the word 'strawberry'"
# What developers might expect:
def count_letters(word, letter):
return word.lower().count(letter.lower())
print(count_letters("strawberry", "r")) # Output: 2
# What Llama 4 might actually produce:
# [Fails to follow instruction format or provides incorrect solution]The Future of Llama 4
Despite the controversies, Llama 4 represents an important technical achievement in the development of mixture-of-experts models. The upcoming Behemoth model, with its 2 trillion parameters, could potentially address some of the current limitations when it's released as part of Llama 4.1.
Meta's approach of using MoE architecture to create more efficient models with selective parameter activation remains promising, even if the current implementation has shortcomings. The 10 million token context window capability, if properly implemented, could enable entirely new categories of AI applications.
Conclusion
Llama 4 represents both the promise and challenges of cutting-edge AI development. While the technical specifications are impressive—particularly the massive parameter counts and context windows—the practical performance appears to fall short of expectations in several key areas.
For the AI community, this release highlights the importance of transparent benchmarking and the need to evaluate models based on real-world performance rather than theoretical capabilities. As Meta continues to refine these models, particularly with the upcoming Behemoth release, the true potential of the Llama 4 architecture may yet be realized.
Let's Watch!
Llama 4: Meta's Massive MoE Model Faces Benchmark Controversy
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence