7 Shocking Ways LLM Benchmarks Are Being Manipulated in the AI Industry Today
Eleanor Park
Developer Advocate

The race to develop the most powerful AI models has turned benchmarking into a high-stakes competition where billions in funding and market dominance hang in the balance. What started as a scientific endeavor to measure model capabilities has evolved into something more problematic - a system where companies employ various tactics to artificially inflate their models' performance on popular LLM benchmarks.
The Current State of LLM Benchmarking
Benchmarking AI models should be straightforward: train a model and test it on unseen data to evaluate how well it generalizes. However, the competitive landscape has created incentives for companies to find creative ways to game these evaluation systems. Understanding these manipulation techniques is crucial for anyone evaluating model performance claims.
Training on Test Data: The Most Common Cheat
The most obvious way to manipulate LLM benchmarks is training directly on test data - essentially memorizing the answers rather than learning to solve problems. While this approach is easily detectable through simple answer reshuffling, more sophisticated techniques have emerged.
One advanced method involves prompt engineering existing language models to rephrase test data through different sentence structures and even languages. This technique can make a modest 13B parameter model appear to perform at the level of much larger models like GPT-4, while bypassing standard data contamination checks.
The Private Benchmark Problem
To combat test data leakage, private benchmarks emerged as a solution where test data remains hidden. However, this approach introduces new vulnerabilities. Since companies typically won't share their proprietary model weights, private benchmarks must evaluate performance through API calls.

This creates two significant problems. First, the private test data is actually exposed to the company being evaluated, allowing them to potentially capture and analyze it. Second, companies can submit an inferior model first, collect the benchmark data, then train their more powerful model specifically on those examples.
Even more concerning are conflicts of interest where companies fund the very benchmarks evaluating their models. A recent example involves Frontier Math by Epoch AI, where the benchmark creator reportedly had undisclosed funding from OpenAI, who also had privileged access to test answers - something other AI labs weren't aware of.

Human Preference Evaluation: The ChatGPT Arena Problem
Human preference-based benchmarks like ChatGPT Arena attempt to solve these issues by having users compare responses from different models. While this approach seems more democratic, it introduces different vulnerabilities.
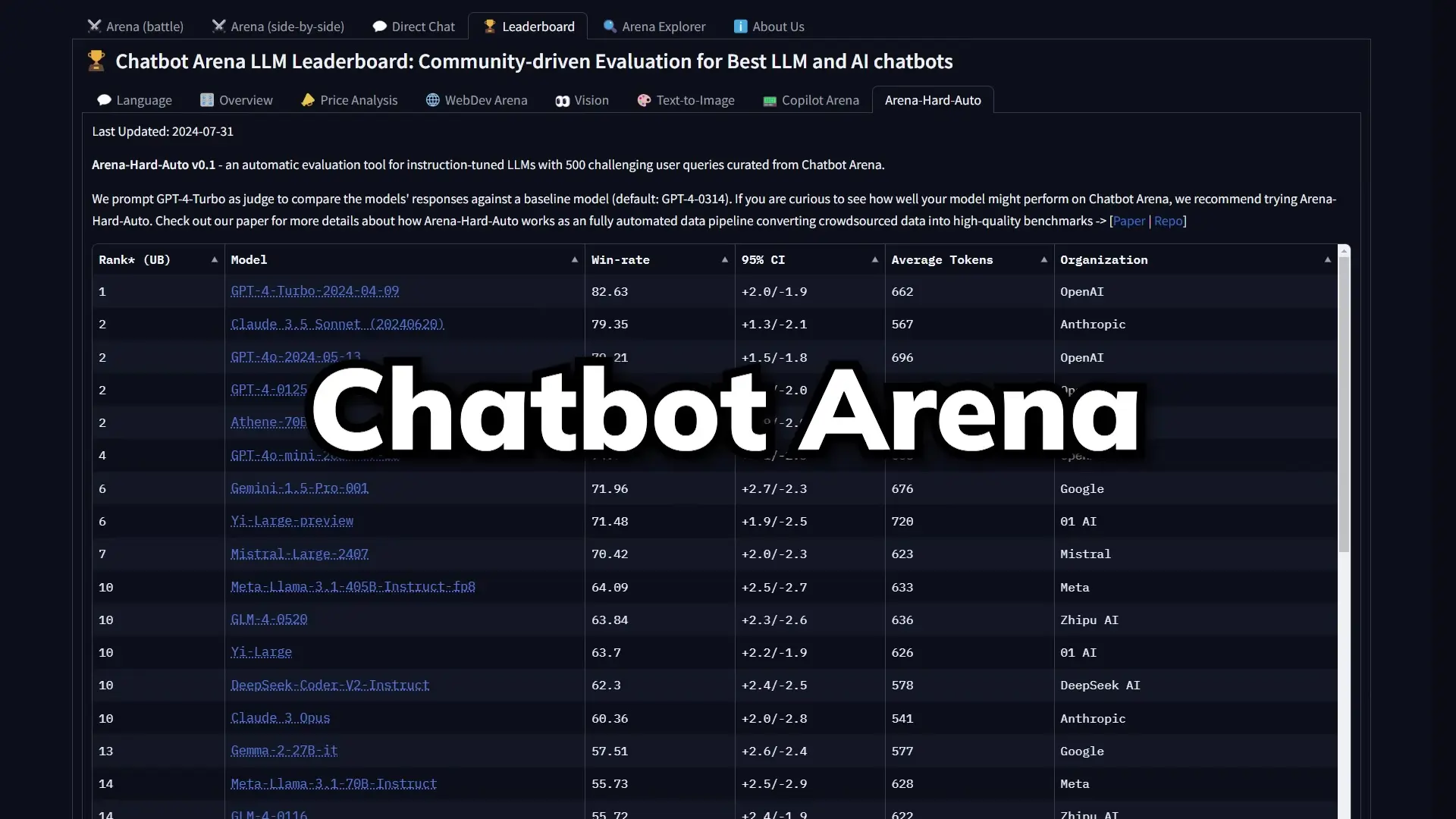
The fundamental flaw is that humans often prefer well-presented but incorrect information over correct information that's poorly presented. For complex topics like advanced mathematics or specialized fields, most evaluators can't accurately judge correctness, making style and confidence more influential than accuracy.
Gaming the ELO System
The ELO ranking system used in platforms like ChatGPT Arena can also be manipulated. Recent research on "idiosyncrasies in LLMs" demonstrated that models have identifiable word distribution patterns. This means companies could potentially create classifiers to identify their own models in blind comparisons with up to 97% accuracy.
Rather than trying to directly boost their own model's ranking, a more efficient strategy would be to systematically downvote competing models. By classifying all models in the system and strategically voting, companies could potentially move up rankings with far fewer votes than would otherwise be required.
7 Common LLM Benchmark Manipulation Techniques
- Direct training on publicly available benchmark test data
- Using existing LLMs to rephrase test data for training
- Exploiting API-based private benchmarks to capture test examples
- Submitting weaker models first to collect benchmark data
- Establishing or funding private benchmarks with privileged access
- Optimizing for human preference metrics rather than accuracy
- Manipulating ELO rankings through strategic voting
Is Fair LLM Benchmarking Even Possible?
Creating truly fair benchmarks in the current AI landscape faces significant challenges. The most equitable approach might involve allocating identical computing resources to all models being compared, but companies are unlikely to reveal such competitive advantages in third-party evaluation settings.
Perhaps the most reliable evaluation method remains personal experience. If you find a particular model works better for your specific use cases, that practical assessment likely holds more value than abstract benchmark scores that may have been influenced by various manipulation techniques.
The Future of AI Competition
The ultimate winners in the AI race may not be determined by benchmark performance alone. User experience factors like ease of use, integration capabilities, and brand loyalty will likely play equally important roles in determining which models achieve widespread adoption.
As the industry matures, we may see the development of more sophisticated and resistant benchmarking methodologies. Until then, maintaining healthy skepticism toward performance claims and understanding the limitations of current evaluation approaches remains essential for anyone navigating the rapidly evolving LLM landscape.
Let's Watch!
7 Shocking Ways LLM Benchmarks Are Being Manipulated in AI Research
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence