Mastering Reinforcement Fine-Tuning: How to Boost AI Model Performance Efficiently
Marcus Chen
Performance Engineer

When it comes to improving AI model performance, developers have several customization options at their disposal. While techniques like better prompting and retrieval augmented generation (RAG) can enhance what a model knows, reinforcement fine-tuning (RFT) stands out as a powerful method to improve how a model reasons. This advanced technique can transform your AI applications, particularly for complex tasks requiring nuanced understanding and decision-making.
Understanding Model Customization Approaches
Before diving into reinforcement fine-tuning, it's important to understand where it fits in the broader landscape of model customization techniques. There are two primary levers for improving LLM app performance:
- Improving what the model knows: Achieved through context engineering techniques like better prompting and retrieval augmented generation (RAG)
- Improving how the model reasons: This is where fine-tuning comes in, with reinforcement fine-tuning being particularly effective
It's worth noting that fine-tuning should be considered an investment. You should first maximize the potential of other approaches like prompting and RAG before turning to fine-tuning methods.
Three Fine-Tuning Techniques Compared
Currently, there are three main fine-tuning techniques available for AI model customization:
- Supervised Fine-Tuning: Uses prompt and answer pairs to teach the model a fixed pattern. Ideal for simple classification tasks or enforcing specific output patterns.
- Preference Fine-Tuning: Provides examples of better and worse outputs, teaching the model to mimic the tone and style of preferred responses. Great for marketing copy, chatbots, and applications where personality matters.
- Reinforcement Fine-Tuning (RFT): Instead of labeled answers, this method uses a grader (a rubric or rule) to score responses for accuracy. The system explores different solutions, grades them, and improves itself accordingly.
Reinforcement fine-tuning has proven especially powerful for policy compliance, legal reasoning, medical workflows, and any domain where reasoning accuracy is critical.
Key Benefits of Reinforcement Fine-Tuning
Reinforcement fine-tuning offers several distinct advantages that make it particularly valuable for complex AI tasks:
- Uniquely suited for reasoning models, which represent the future of AI development
- Highly data-efficient, requiring only tens to hundreds of examples to achieve significant improvements
- Provides clearer signals about whether your task will benefit from this technique
- Doesn't require manually labeled outputs, operating instead with graders that can be repurposed for evaluation
Organizations are already leveraging RFT to replace complex policy pipelines with single reasoning agents, improve compliance checks by training on real policy logic, and boost accuracy in specialized domains like medical coding.
How Reinforcement Fine-Tuning Works Under the Hood
What makes reinforcement fine-tuning so sample-efficient and powerful? The secret lies in how it extracts multiple learning opportunities from each example:
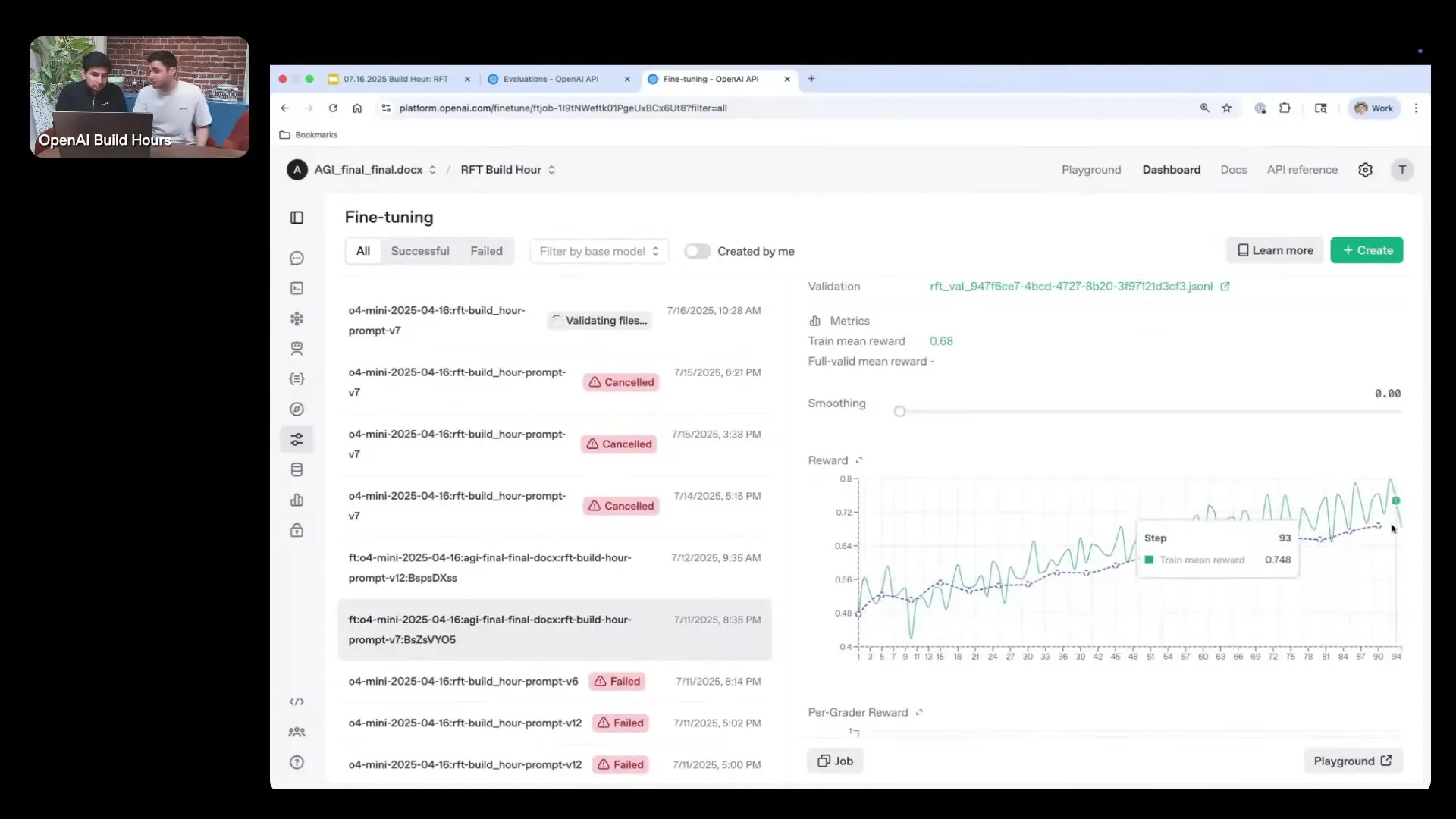
When you implement RFT, you start with your task (dataset, prompts, and answers) and choose a model. The critical component is the grader, which evaluates the quality of responses. Under the hood, the algorithm samples the same example multiple times, generating different reasoning paths and answers each time.
This approach allows the model to compare various answers and determine which reasoning paths are more effective. Each example provides substantial information about good versus less effective reasoning strategies. By training on just tens or hundreds of samples, you can significantly improve the model's reasoning capabilities and its ability to generalize across similar tasks.
This approach differs fundamentally from other fine-tuning techniques where one sample equals just one training example. With RFT, you extract much more signal from each task, making the process remarkably efficient.
Setting Up a Reinforcement Fine-Tuning Task
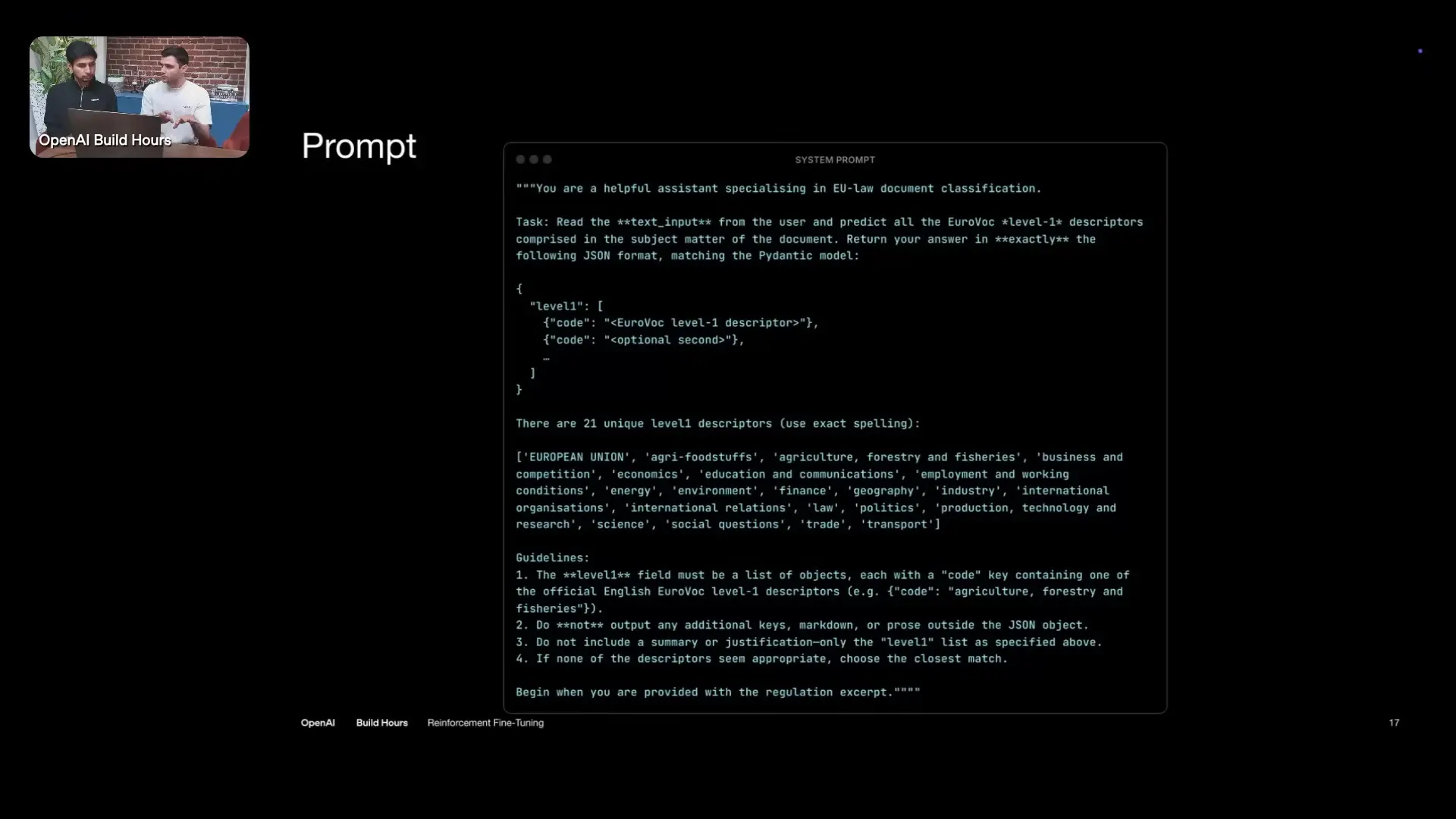
To demonstrate the practical application of reinforcement fine-tuning, let's examine a classification task involving legal texts. In this example, we need to predict which Eurovoc level one classes a given legal text belongs to. Eurovoc level one classes are the highest level, broadest thematic categories in the Eurovoc multilingual controlled vocabulary maintained by the EU Publications Office.
This classification task involves 21 different classes, and each sample can have one to six or more classes assigned to it. Rather than using numeric IDs for these classes, we convert them to semantic names that the model can better reason about.
Evaluation Metrics for Classification Tasks
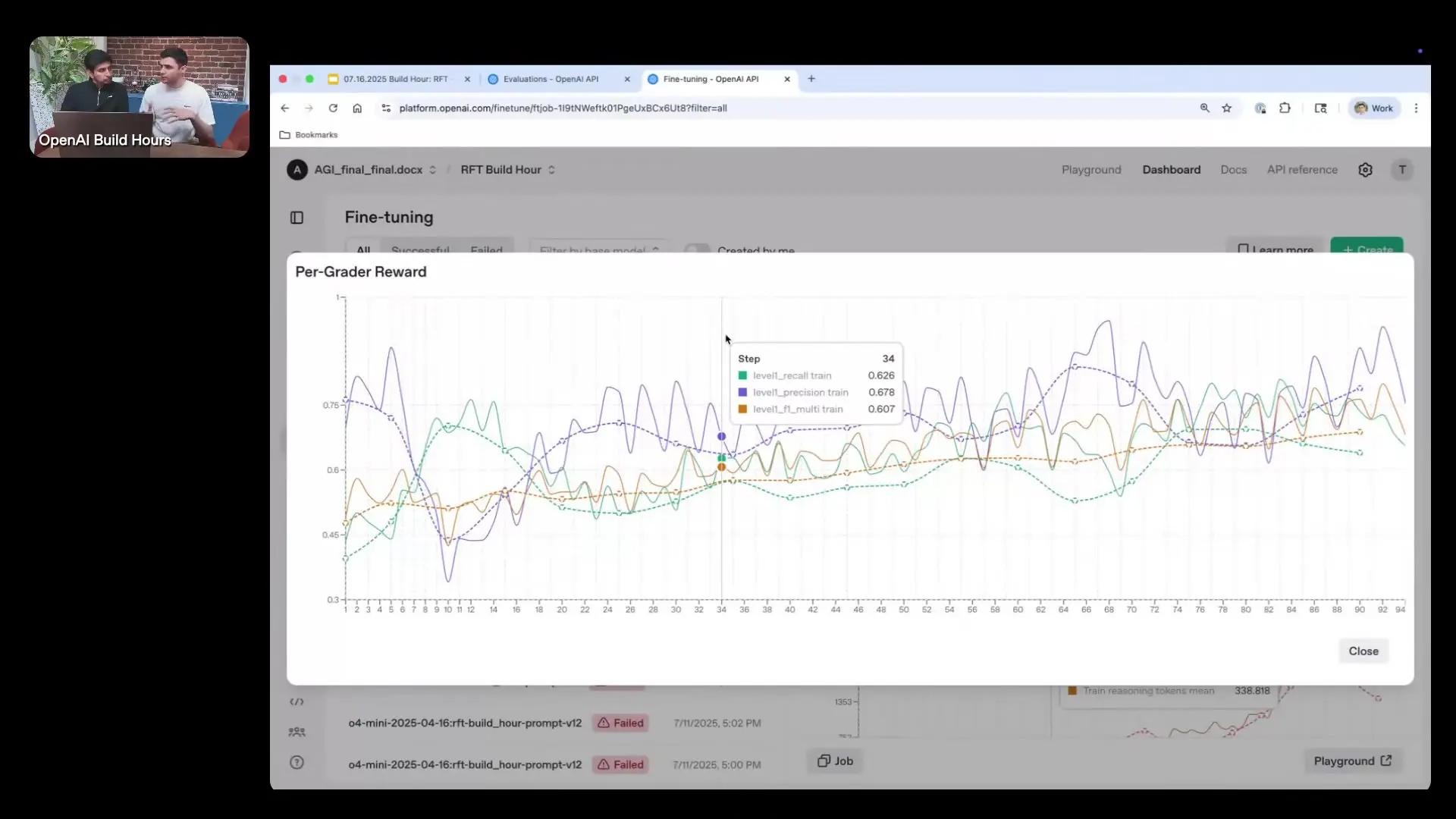
Before implementing reinforcement fine-tuning, it's essential to understand how we'll evaluate success. For classification tasks, two key metrics are particularly important:
- Precision: Of the predicted labels, how many are actually correct?
- Recall: How many of the actual labels did we successfully identify?
Since reinforcement fine-tuning requires a single grade for each training sample, we typically use the F1 score, which combines precision and recall into a single metric. The F1 score weights the lower value slightly higher, acknowledging that classification performance is often bottlenecked by whichever metric (precision or recall) is weaker.
In some cases, you might want to prioritize one metric over the other. For example, if recall is more important than precision for your application, you might use an F2 score instead, which weights recall more heavily in the calculation.
Data Preparation for Reinforcement Fine-Tuning
The quality of your data is paramount for successful reinforcement fine-tuning. When preparing your dataset, consider these key aspects:
- Transform any IDs or codes into semantic names that the model can reason about more effectively
- Ensure your examples are representative of the full range of cases the model will encounter
- Split your data appropriately into training and evaluation sets
- Design a clear, consistent grading system that can accurately evaluate model outputs
For classification tasks like our example, it's particularly important that the model understands the meaning of the categories, not just their identifiers. This semantic understanding enables better reasoning and more accurate classification.
Real-World Applications of Reinforcement Fine-Tuning
Reinforcement fine-tuning is already making a significant impact across various industries and use cases:
- Legal and compliance: Replacing complex policy pipelines with single reasoning agents that can interpret and apply policies accurately
- Healthcare: Improving medical coding accuracy by training models with expert-verified graders
- Content moderation: Enhancing the ability of models to identify policy violations with greater precision
- Financial services: Developing models that can reason through complex regulatory requirements and apply them consistently
The common thread across these applications is the need for sophisticated reasoning rather than just factual knowledge. By focusing on how models reason through problems, reinforcement fine-tuning enables more reliable, consistent, and accurate AI systems for critical applications.
Getting Started with Reinforcement Fine-Tuning
If you're considering implementing reinforcement fine-tuning for your AI application, here are some steps to get started:
- Evaluate whether you've maximized the potential of simpler approaches like prompting and RAG
- Identify tasks where reasoning quality is more important than factual knowledge
- Develop a clear grading system that can evaluate the quality of model outputs
- Start with a small, high-quality dataset (tens to hundreds of examples)
- Monitor both training performance and generalization to new examples
Remember that reinforcement fine-tuning is particularly valuable for tasks where the model already knows the necessary facts but struggles to apply them correctly or reason about them accurately. By focusing on improving reasoning capabilities, you can develop AI systems that make better decisions in complex scenarios.
Conclusion
Reinforcement fine-tuning represents a significant advancement in AI model customization, offering a powerful way to improve how models reason through complex problems. With its remarkable sample efficiency and focus on reasoning quality rather than just factual knowledge, RFT is enabling more sophisticated, reliable AI systems across various domains.
As AI continues to evolve, techniques like reinforcement fine-tuning will play an increasingly important role in developing systems that can handle nuanced, complex tasks with human-like reasoning capabilities. By understanding and implementing these advanced fine-tuning methods, developers can create AI applications that deliver more accurate, consistent, and valuable results.
Let's Watch!
Mastering Reinforcement Fine-Tuning: Boost AI Model Performance
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence