Meta's Breakthrough: How Early Fusion is Revolutionizing Multimodal AI Model Architecture
Marcus Chen
Performance Engineer

The current landscape of multimodal AI faces a fundamental architectural challenge. Popular models like Claude, Grock, and Llama can write text, analyze images, and sometimes generate visuals, but most aren't truly integrated multimodal systems. Instead, they rely on what researchers call 'late fusion' - a Frankenstein-like approach that cobbles together separate components rather than building a unified intelligence.
The Frankenstein Problem: Late Fusion in Multimodal AI
Late fusion has been the dominant paradigm in multimodal AI development, treating each modality separately during initial model training. This approach uses dedicated vision components to process images and separate large language model components to handle text. These distinct modules are connected later in the training process, typically by feeding visual features into the LLM.
The popularity of late fusion stems from its practical advantages - researchers can leverage pre-trained components already optimized for specific modalities, using established datasets and pipelines. The primary challenge becomes connecting these state-of-the-art components into something multimodal. However, this convenience comes at a cost: models lack genuine semantic understanding between text and visual concepts.
Meta's Chameleon: Pioneering Early Fusion
Meta's research group (Meta FAIR) has been at the forefront of addressing this limitation. A year ago, they published a groundbreaking paper called 'Chameleon,' demonstrating how early fusion models can effectively scale up to 34 billion parameters. This research has been further validated by Apple's recent paper showing promising scaling laws for early fusion compared to late fusion approaches.
Early fusion represents a fundamentally different approach to multimodal AI. Instead of treating modalities separately, early fusion processes raw text and visual data together from the beginning using a unified transformer architecture. This resembles how humans naturally understand both language and vision simultaneously, rather than requiring translation between specialized systems.
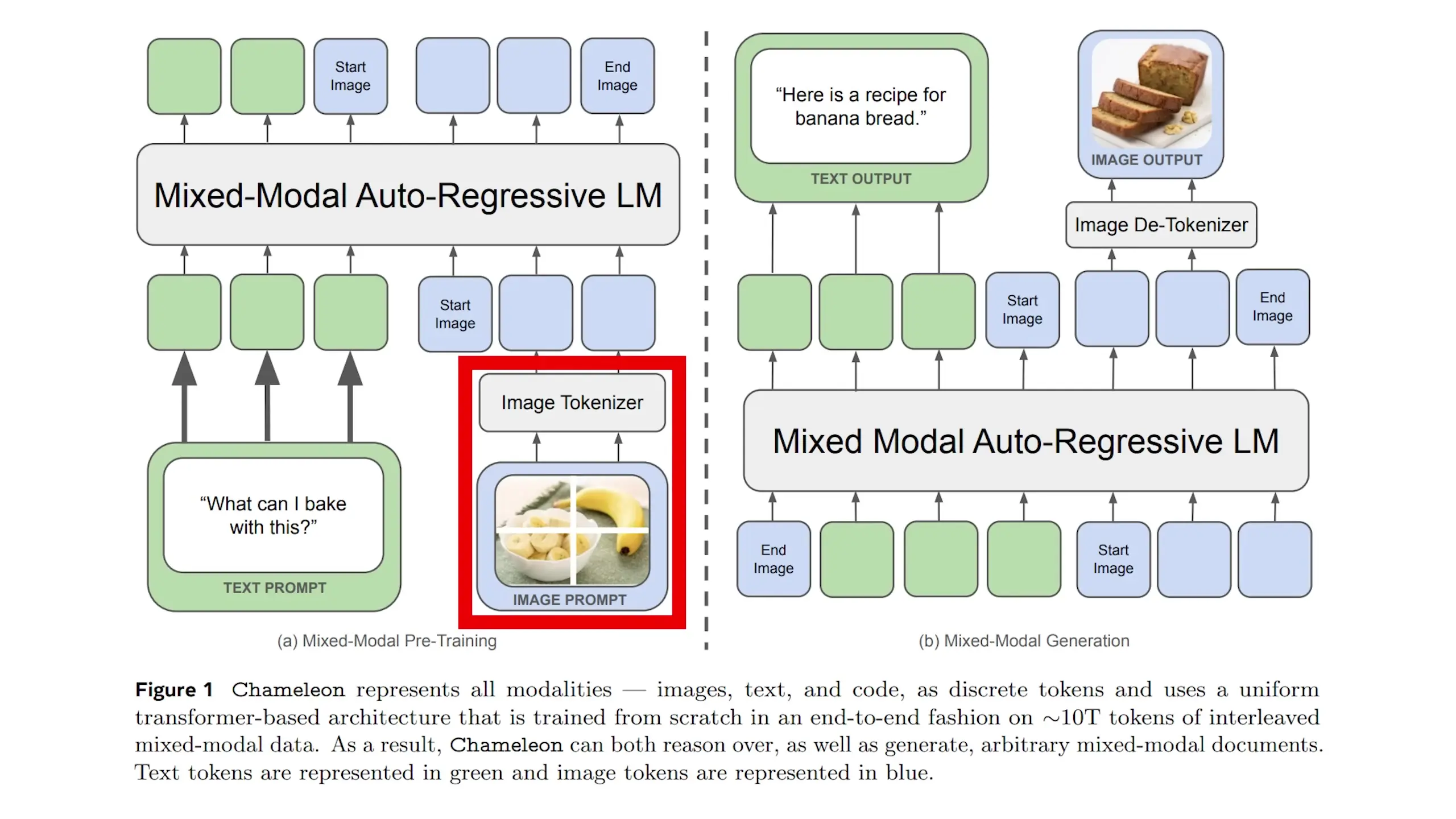
Chameleon's approach treats everything, including images, as discrete tokens that can be processed by the same transformer architecture. Images are tokenized into discrete units, allowing the base model (Llama 2 in this case) to seamlessly generate sequences that mix text and images.
Overcoming Technical Challenges
Implementing early fusion wasn't without challenges. When researchers scaled up to 8 billion parameters and 1 trillion tokens, training became unstable with divergences appearing late in the process. This instability stemmed from competition between different modality signals within the shared architecture.
Image generation, in particular, requires more extreme activation values to represent rich visual information, causing signals to compete destructively and making other functionalities unusable. The researchers solved this by normalizing signals at key points in the model, preventing different modalities from competing.
Chameleon's Capabilities: Beyond Late Fusion
The resulting early fusion model demonstrated capabilities that late fusion models simply couldn't match. Chameleon can:
- Generate documents with images and text interleaved in natural sequences
- Create images in the middle of text explanations
- Reason across modalities without artificial barriers imposed by separate encoders
- Outperform its Llama 2 baseline on language capabilities
- Surpass Flamingo, GPT-4V, and Gemini Pro on image-to-text benchmarks
Apple's Research: Confirming Early Fusion's Superiority
Despite Chameleon's impressive performance, late fusion methods continued to dominate due to their lower cost and convenience. However, a recent paper from Apple called "Scaling Loss for Native Multimodal Models" provides compelling evidence that early fusion is indeed the superior approach.
This comprehensive research involved 457 different models ranging from 300 million to 4 billion parameters, systematically comparing early and late fusion approaches. The findings validate Chameleon's approach, showing that early fusion models match or exceed late fusion performance across most benchmarks.
Surprising Efficiency Advantages
One of the most surprising discoveries from Apple's research is that early fusion models are actually more efficient than late fusion models - contrary to the prevailing wisdom in the field. Early fusion models:
- Train faster
- Use less memory
- Require fewer parameters
- Are easier to deploy
The complexity of orchestrating multiple specialist components in late fusion creates too much overhead, making early fusion more efficient overall. Additionally, multimodal models follow scaling laws nearly identical to text-only language models, simplifying the development process.
Mixture of Experts: Natural Specialization
When applying Mixture of Experts (MoE) techniques to these multimodal models, researchers observed fascinating emergent behavior. Without any guidance about the differences between text and images, the models spontaneously learned to specialize - some experts became text specialists while others became image specialists.
This natural specialization likely occurs because the signals for text and images are fundamentally different, making the organization of knowledge more intuitive. This suggests that early fusion and MoE are exceptionally compatible, with MoE providing significant performance boosts while maintaining the same inference cost.
Counterintuitive Findings on Image Resolution
Another surprising discovery challenges conventional wisdom about image processing. As image resolution increased, early fusion models actually performed better relative to late fusion models - not worse as previously assumed. This contradicts the intuition that specialized vision encoders would excel at high-resolution image processing.
The unified processing of visual information in early fusion proved more effective than specialized components. However, high-resolution images do require more tokens, making context window extension an important goal for future development.

Use Case Considerations
While early fusion shows clear advantages, it's not universally superior in all scenarios. Early fusion models excel at handling text-heavy documents mixed with images, while late fusion models still perform better on tasks requiring training on pure image-caption pairs.
The optimal architecture should be chosen based on specific use cases and available data rather than assuming early fusion is a one-size-fits-all solution. Nevertheless, early fusion's ability to learn joint representations from the ground up consistently outperforms late fusion while requiring fewer computational resources and less architectural complexity.
The Future of Multimodal AI
Looking forward, we may see an open-source paradigm shift toward native multimodal language models, with late fusion becoming a specialized approach used only when reusing pre-trained components is necessary. A unified multimodal model makes intuitive sense given how images can help unlock knowledge - recent research shows that scaling to 100 billion pre-training images improved cultural and linguistic inclusiveness of models.
One potential limitation of the current unified architecture is the use of image tokenizers, as images are continuous data and discretizing them may not be optimal. Future research might explore how multimodal diffusion language models could address this limitation.
Conclusion: Meta Leads the Way
Meta FAIR has once again demonstrated its forward-thinking approach, being approximately a year ahead of the broader industry in multimodal AI architecture. The development of GPT-4o and Gemini might have already pivoted toward unified architecture early in their development, potentially leaving other companies and open-source initiatives playing catch-up.
As the field continues to evolve, early fusion appears poised to become the dominant paradigm for next-generation multimodal AI systems, offering more natural integration of different information types and potentially bringing us closer to more human-like artificial intelligence.
Let's Watch!
Meta's Breakthrough: How Early Fusion Transforms Multimodal AI Models
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence