Moonshot AI's Kimi K2: Revolutionary Architecture and the Game-Changing Muon Optimizer
Priya Narayan
Systems Architect

Moonshot AI has made waves in the artificial intelligence community with their latest model, Kimi K2. This trillion-parameter model featuring 32 billion active parameters represents a significant advancement in AI architecture design and optimization techniques. At the heart of this breakthrough is the implementation of a novel optimizer called Muon, which promises to revolutionize how large language models are trained.
The Breakthrough Performance of Kimi K2
Before diving into the technical innovations, it's worth noting Kimi K2's impressive benchmark performance. The model achieved top rankings on several important benchmarks:
- Number one on EQ Bench, a creative writing benchmark
- Top position on LM Arena for open models
- Performance slightly better than Qwen 3205B on reasoning tasks
- Comparable to GPT-4.1 and Qwen 3235B on reasoning capabilities
- Approaching the performance level of Gemini 2.5 on third-party benchmarks
These achievements positioned Kimi K2 as the state-of-the-art open-source non-reasoning model until the recent release of the new Qwen 3 model. What makes this even more remarkable is the innovative architectural approach and optimization techniques that enabled these results.
The Muon Optimizer: A Game-Changing Innovation
The standout innovation in Kimi K2's development is the implementation of the Muon optimizer. Proposed in October 2024, Muon challenges the dominance of Adam, which has been the standard optimizer in deep learning for nearly eight years.
To understand the significance of this change, it helps to visualize AI model training as navigating a complex landscape where the goal is to reach the lowest point (representing optimal predictions) by taking steps based on the slope of the terrain.
How Muon Differs from Adam
The traditional Adam optimizer measures the steepness and jitteriness of each step to adjust stride length and direction. When consecutive steps have similar slopes, Adam builds momentum. However, this momentum can cause problems when the slope changes direction, leading to overshooting and slower convergence.
Muon's approach is fundamentally different. Before each stride, it pauses to assess the situation, slowing down momentum and redistributing it evenly across all directions. This more measured approach allows for more accurate descent toward the optimal solution.
While this additional check costs about 0.5% more compute per step, it delivers an impressive return on investment by reducing total training time by up to 35%. The result is a much smoother training loss curve with fewer spikes, indicating more stable and efficient training.
Overcoming Challenges: The Birth of Muon Clip
Scaling Muon to a trillion-parameter model wasn't without challenges. During initial training, some tokens would generate extremely large query or key vectors, creating oversized learning signals that Muon couldn't dampen effectively. This created a negative feedback loop that threatened to break the training process.
The solution came from Sujin Ling (the inventor of RoPE), who proposed a technique called QK clip, later known as Muon Clip. This approach simply adds a threshold that clips out giant query and key norms before Muon processes the momentum, effectively taming the early outliers and stabilizing the training process.
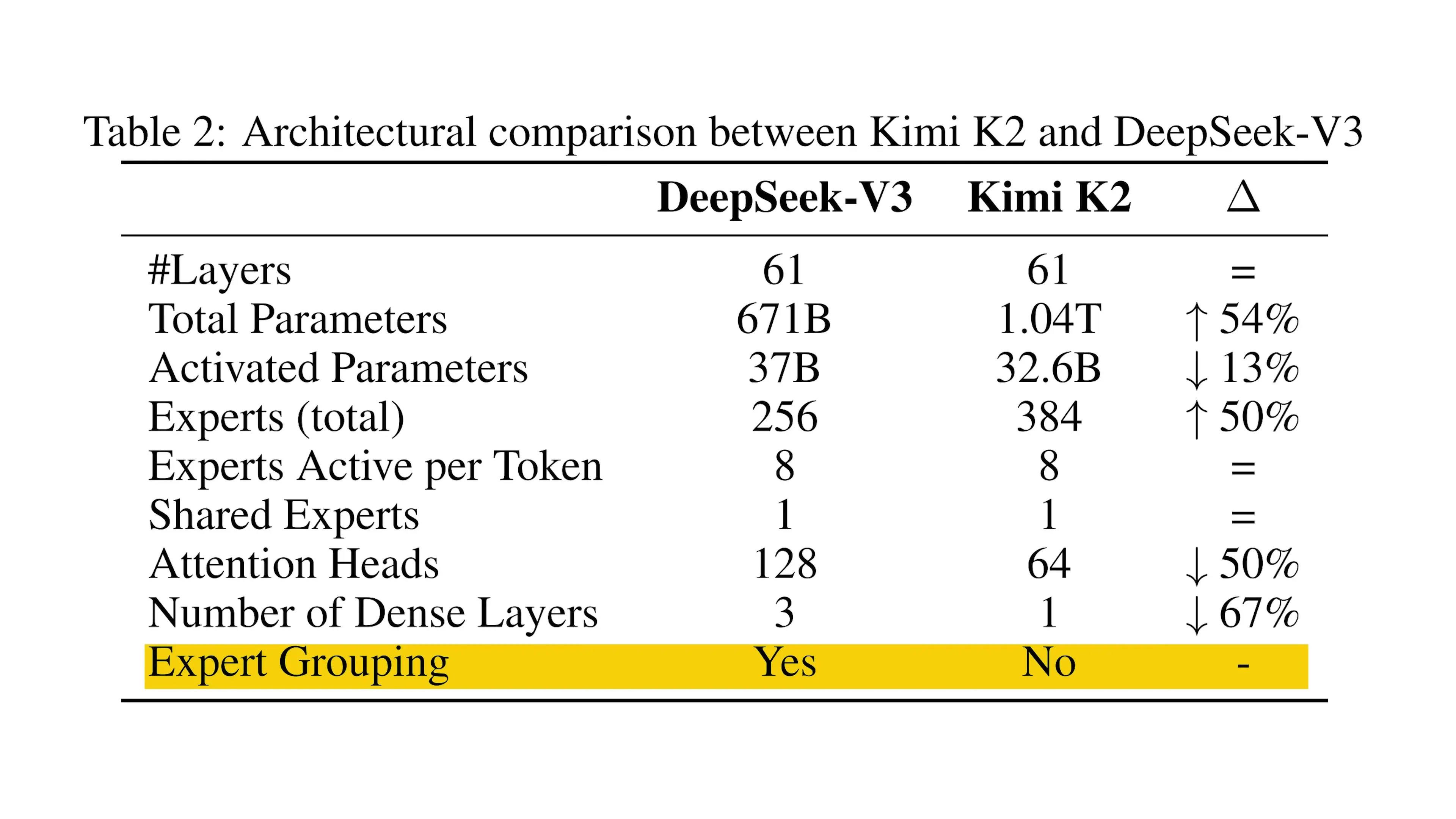
K2 Architecture: Cost-Efficient Modifications
Beyond the Muon optimizer, the Moonshot AI team made several key architectural adjustments to improve efficiency while maintaining performance. Their ablation studies confirmed that the Deep Seek V3 model design (combining MLA and MOE approaches) provided an excellent foundation, but they identified several opportunities for optimization:
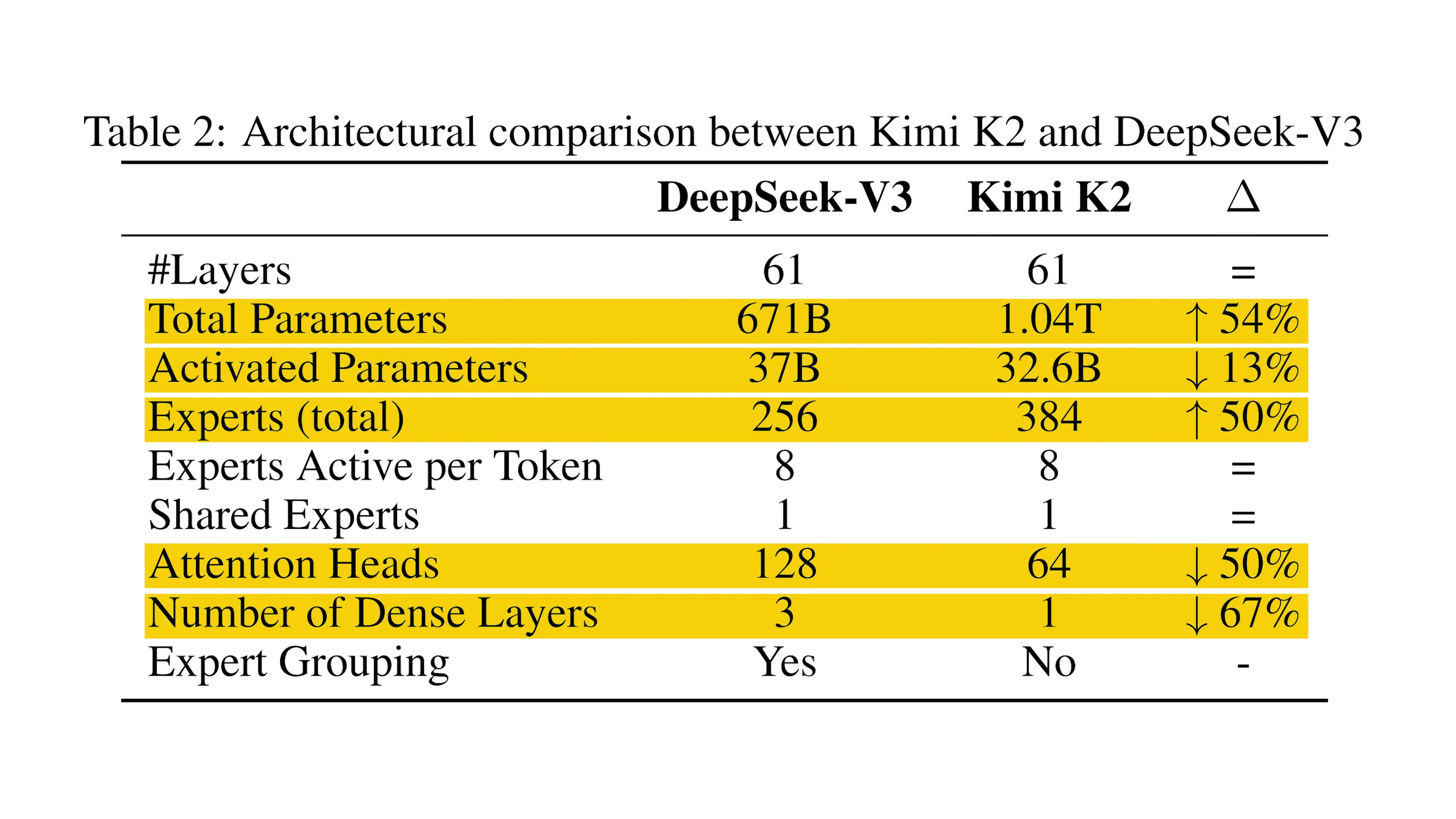
- Added 50% more experts per layer while keeping active parameters per token unchanged, increasing sparsity based on a newly discovered sparsity scaling law
- Reduced attention heads from 128 to 64, cutting the QKVO projection matrix from 10 billion to 5 billion parameters with only a 2% performance degradation
- Made only the first layer dense (instead of the first three as in Deep Seek V3), which proved sufficient for training stability
- Eliminated expert grouping in favor of a simple router that gives a flat menu of all 384 experts across the cluster, widening the search space
The Scale of Training: 384 GPUs for a Trillion Parameters
The sheer scale of training Kimi K2 is staggering. With one trillion total parameters, the model required 384 GPUs operating simultaneously during training. At this scale, each GPU effectively holds just one expert, which influenced several of the architectural decisions mentioned above.

This massive training operation cost approximately $30 million, with $20 million dedicated to generating the training loss curve alone. For an AI startup, getting it right on the first attempt was crucial, making the innovations in optimization and architecture all the more impressive.
Implications for the Future of AI Model Training
The innovations introduced in Kimi K2, particularly the Muon optimizer with Muon Clip, have potential implications far beyond this single model. By improving training efficiency by up to 35%, these techniques could significantly reduce the cost and environmental impact of training large AI models.
The architectural insights regarding expert distribution, attention head optimization, and routing strategies also provide valuable guidance for future model designs, especially at the trillion-parameter scale.
Conclusion: A Milestone in AI Architecture
Moonshot AI's Kimi K2 represents a significant milestone in AI model architecture and training methodology. By combining the innovative Muon optimizer with strategic architectural modifications, they've created a highly efficient model that delivers state-of-the-art performance in multiple benchmarks.
While Kimi K2 may have briefly held the title of best open-source non-reasoning model before being overtaken by newer releases, its technical innovations—particularly in optimization techniques—may have a lasting impact on how future AI models are trained. The introduction of Muon and Muon Clip could potentially change the pre-training meta, making the development of large language models more efficient and accessible.
Let's Watch!
Moonshot AI's Kimi K2: Revolutionary Architecture Using Muon Optimizer
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence