Multi-Token Prediction: How Large Language Models Can Predict Multiple Tokens Simultaneously
Eleanor Park
Developer Advocate

Large language models have revolutionized AI capabilities, but they face a fundamental limitation: they can only predict one token at a time from left to right. This limitation creates challenges when models need to plan ahead or maintain structural integrity throughout longer text generations. The good news is that an emerging technique called multi-token prediction (MTP) is changing this paradigm by allowing LLMs to predict multiple tokens simultaneously.
The Limitation of Next-Token Prediction
Traditional language models operate on a next-token prediction paradigm. When you ask a non-reasoning model how many words will be in a sentence it's about to generate, it typically fails to answer correctly. This isn't because LLMs are bad at counting tokens, but because they fundamentally can't see their own future generations.
The standard approach works by predicting one word at a time from left to right (autoregressive generation). This makes it incredibly difficult for models to maintain coherence over long outputs or plan structural elements that require foresight, such as matching opening and closing parentheses in code or maintaining consistent tense throughout a paragraph.
What is Multi-Token Prediction?
Multi-token prediction (MTP) offers a solution to this limitation. Instead of predicting just the next token (t+1) based on the context up to position t, MTP allows models to predict multiple future tokens (t+1, t+2, t+3, and even t+4) simultaneously.
The initial approach to MTP is architecturally straightforward. It uses a standard transformer model (called the "trunk") to process input text and generate an internal representation up to the current position. The key difference is that instead of having just one output head predicting the next token, multiple independent output heads predict several future positions in parallel.
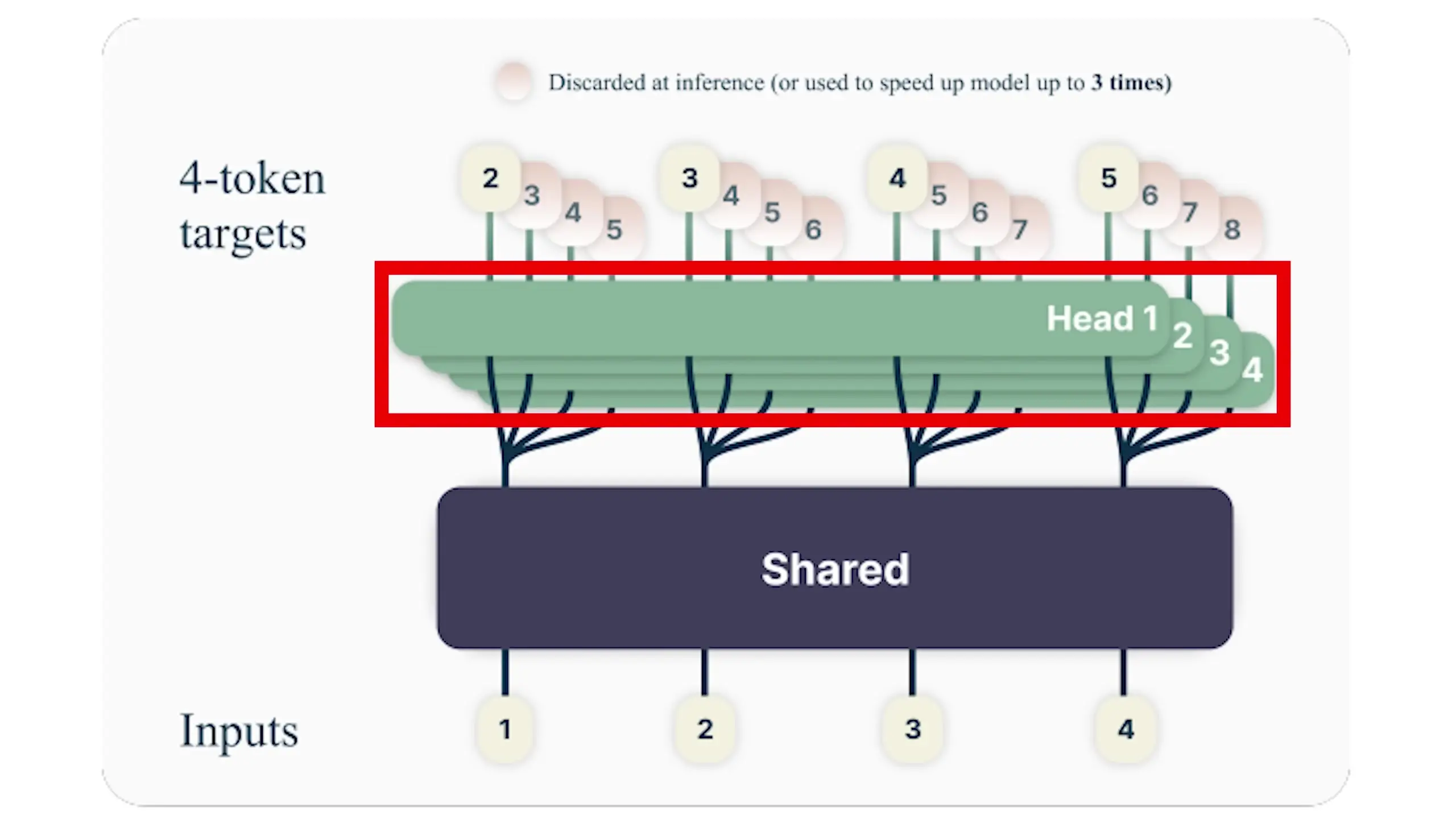
This means one forward pass of the model can effectively "shotgun" four tokens at once, potentially speeding up generation by up to four times. But does this shotgun approach make predictions less accurate? Surprisingly, research shows the opposite in many cases.
Performance Benefits of Multi-Token Prediction
When models are trained to predict multiple tokens at once, their structural and syntactic capabilities actually improve significantly. Research shows that for coding tasks, larger models benefit more from the MTP approach, with improvements ranging from 1.7% to 4.5% compared to baselines across benchmarks.
Similar improvements were observed on the ARC challenge benchmark for abstract reasoning. Counterintuitively, predicting more tokens at once often leads to better performance while also providing a 3-4x speedup in token generation. This makes MTP an extremely efficient enhancement.
The Science Behind MTP's Effectiveness
Researchers found that by analyzing a single hidden state up to position t in a model, they could approximate the model's prediction for subsequent tokens with up to 48% accuracy. This suggests that even models trained only to predict the next token implicitly develop some level of foresight in their internal representations.
This implicit capability explains why larger models show more improvement with MTP—they have more parameter space to develop these foresight mechanisms that MTP explicitly encourages.
Challenges with Basic MTP Implementation
The basic MTP approach has a significant weakness: potential inconsistency between independently predicted tokens. When each output head makes predictions without knowledge of what other heads are predicting, the resulting sequence may lack coherence.
It's like having four different weather forecasters making predictions for four consecutive days without communicating with each other. While they might all use similar training data, their disconnected predictions could create inconsistent forecasts.
DeepSeek's Advanced MTP Implementation
DeepSeek V3, currently one of the best open-source AI models, has implemented an innovative solution to the MTP consistency problem. Instead of using MTP directly during inference with parallel independent heads, they use it as a training objective to enhance their model's capabilities.
DeepSeek's approach uses sequential MTP modules rather than parallel heads. After the main transformer model processes input up to token t (producing hidden state H0), the sequential MTP process begins:
- The model first predicts token t+1 using the standard approach
- Information from this prediction is then fed into a dedicated transformer block
- This block generates token t+2, creating a causal chain
- The process can continue for additional tokens
This sequential approach maintains causality and avoids inconsistency issues. To extend our weather forecaster analogy, it's like having the day-two forecaster see what the day-one forecaster predicted before making their own prediction.

The Key Innovation: MTP as a Training Objective
The crucial aspect of DeepSeek's implementation is that learning signals (gradients) from the MTP modules flow back through the shared components, including the output head and transformer trunk. This forces the model to develop richer representations that capture longer-range foresight.
DeepSeek validated this approach rigorously, comparing models trained with and without the MTP objective. Their findings showed that models trained with MTP consistently performed better across most benchmarks, with minimal computational overhead.
Importantly, after training with MTP, the auxiliary MTP modules can be discarded, and the enhanced main model continues to benefit from the improved representations it developed during training.
Practical Applications and Benefits of MTP
Multi-token prediction offers several practical advantages for LLM development and deployment:
- Increased generation speed (up to 3-4x faster token generation)
- Improved structural coherence in outputs, especially for code generation
- Enhanced reasoning capabilities on complex tasks
- Better handling of llm token limit constraints through more efficient processing
- More consistent outputs with fewer logical contradictions
These benefits make MTP particularly valuable for applications requiring high-quality, structured outputs like code generation, complex reasoning tasks, and document creation.
The Future of Token Prediction in LLMs
While MTP represents a significant advancement, other approaches are also being explored to overcome the limitations of traditional next-token prediction:
- Diffusion language models that generate all tokens simultaneously rather than sequentially
- Bidirectional models (like BERT) that can attend to information in both directions
- Hybrid approaches combining elements of autoregressive and non-autoregressive generation
However, MTP's advantage lies in its compatibility with existing transformer architectures. It offers significant improvements without requiring the massive architectural changes of alternatives like diffusion language models.

Conclusion: The Promise of Multi-Token Prediction
Multi-token prediction represents a promising evolution in language model architecture that addresses fundamental limitations of traditional next-token prediction. By enabling models to predict multiple tokens simultaneously, MTP improves both generation speed and output quality.
The most effective implementation, as demonstrated by DeepSeek V3, uses MTP as a training objective rather than an inference method. This approach enhances the model's internal representations and reasoning capabilities without sacrificing the reliability of standard autoregressive generation.
As LLM development continues to evolve, techniques like multi-token prediction will play an increasingly important role in creating more capable, efficient, and coherent AI systems that can better understand and generate human language.
Let's Watch!
Multi-Token Prediction: How LLMs Can Predict 4 Tokens at Once
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence