The Mysterious Boundary AI Can't Cross: Understanding Neural Scaling Laws and AI Limitations
Jamal Washington
Infrastructure Lead

As artificial intelligence continues to advance at a breathtaking pace, researchers have discovered something peculiar: there appears to be a boundary that AI models cannot cross, regardless of their size or computational resources. This phenomenon, observed across various neural network architectures, raises profound questions about the fundamental limits of AI and whether we're approaching theoretical ceilings in machine intelligence capabilities.
The Discovery of Neural Scaling Laws
In 2020, OpenAI published groundbreaking research that revealed clear performance trends across language models of various sizes. Their findings demonstrated that AI model performance follows predictable power laws related to three key factors: computational resources (compute), model size (parameters), and training dataset size.
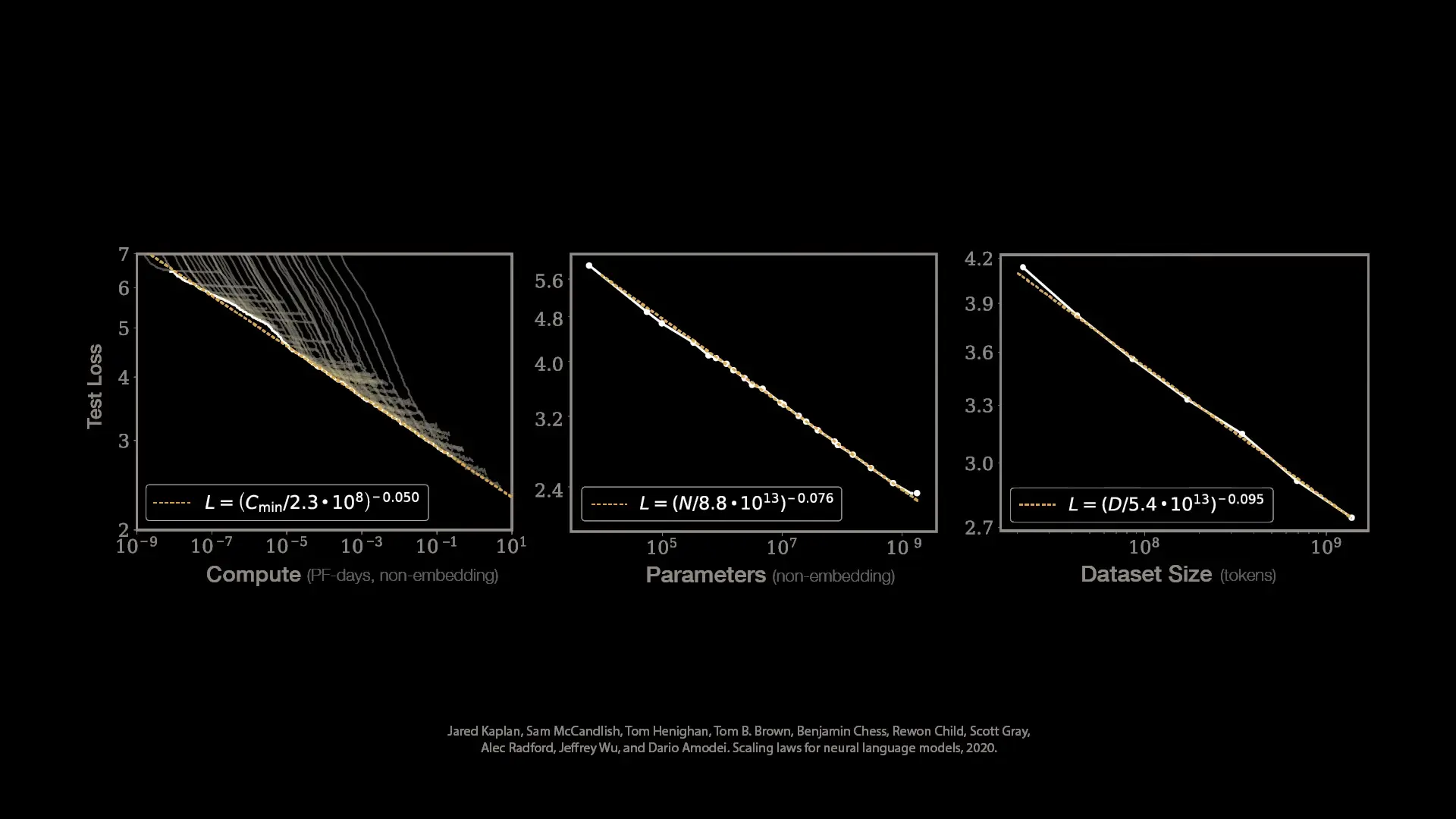
When plotted on logarithmic scales, these relationships appear as straight lines, with the slope representing the exponent in the power law equation. Most importantly, researchers identified a clear boundary that no model could cross – the compute-efficient frontier – suggesting fundamental ai limitations that persist regardless of scale.
Understanding the Compute-Efficient Frontier
The compute-efficient frontier represents an apparent limit to how efficiently neural networks can convert computational resources into performance gains. This boundary appears consistent across different model architectures, suggesting it may represent a fundamental property rather than a limitation of current approaches.
This discovery raises a crucial question: Have we uncovered a fundamental law of nature governing intelligent systems, similar to the ideal gas law in physics? Or is this merely a transient result specific to our current neural network-driven approach to AI? Understanding this boundary could reveal critical insights about ai challenges 2025 and beyond.
GPT-3: A Massive Bet on Scale
Following their scaling law discoveries, OpenAI made an enormous bet on scale with GPT-3. Partnering with Microsoft, they built a supercomputer with 10,000 V100 GPUs to train the 175 billion parameter model using 3,640 petaflop-days of compute – hundreds of times larger than previous models.
GPT-3's performance followed the trend lines predicted by scaling laws remarkably well. However, it still didn't flatten out, suggesting that even larger models would continue improving performance. This raised new questions about the limits of AI and whether performance would eventually plateau.
The Mathematics of AI Limitations
To understand ai limitations, we need to examine how model performance is measured. Language models like GPT-3 are trained to predict the next word in a sequence based on previous words. Their predictions are probability distributions across their entire vocabulary (over 50,000 words for GPT-3).
Performance is typically measured using cross-entropy loss, which quantifies how confidently the model predicts the correct next word. A perfect model would have zero loss, but this is theoretically impossible for natural language because there's often no single correct next word – language has inherent uncertainty or entropy.
The Entropy Barrier: Why AI Struggles with Ambiguity
One key reason why ai fails to achieve perfect performance relates to the inherent entropy in the data it's modeling. For example, following the phrase "a neural network is a," multiple valid completions exist. The best a model can do is assign realistic probabilities to possible continuations.
- Natural language has inherent ambiguity that creates an irreducible error
- This fundamental uncertainty is called the entropy of natural language
- Even infinite compute and data couldn't drive error to zero
- The best models can only match the probability distribution of human responses
This inherent ambiguity explains why some scaling curves eventually flatten – they approach the irreducible entropy of the data. For certain problems like image classification, researchers have been able to estimate this entropy barrier, but for natural language, the entropy remains difficult to quantify precisely.
The Curse of Dimensionality: Another AI Barrier
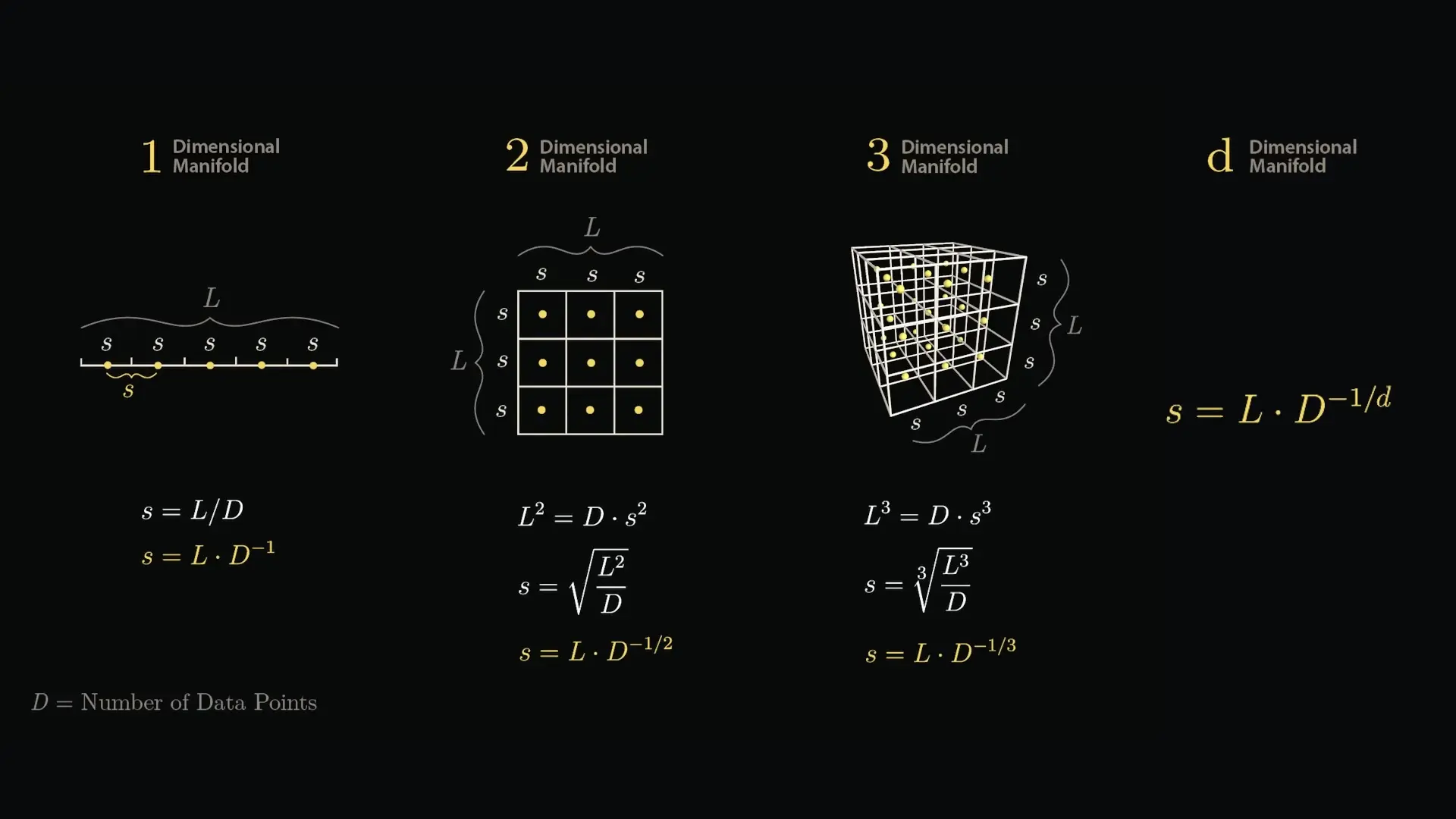
Beyond entropy, AI faces another fundamental challenge: the curse of dimensionality. As the dimensionality of data increases, the volume of the space increases so rapidly that available data becomes sparse. This creates regions where models must extrapolate rather than interpolate, leading to ai generalization issues.
The mathematical reality is that as dimensions increase, exponentially more data is required for the same coverage density. This creates fundamental ai knowledge limits that cannot be overcome simply by scaling up existing approaches.
Feature Representation and AI Understanding Problems
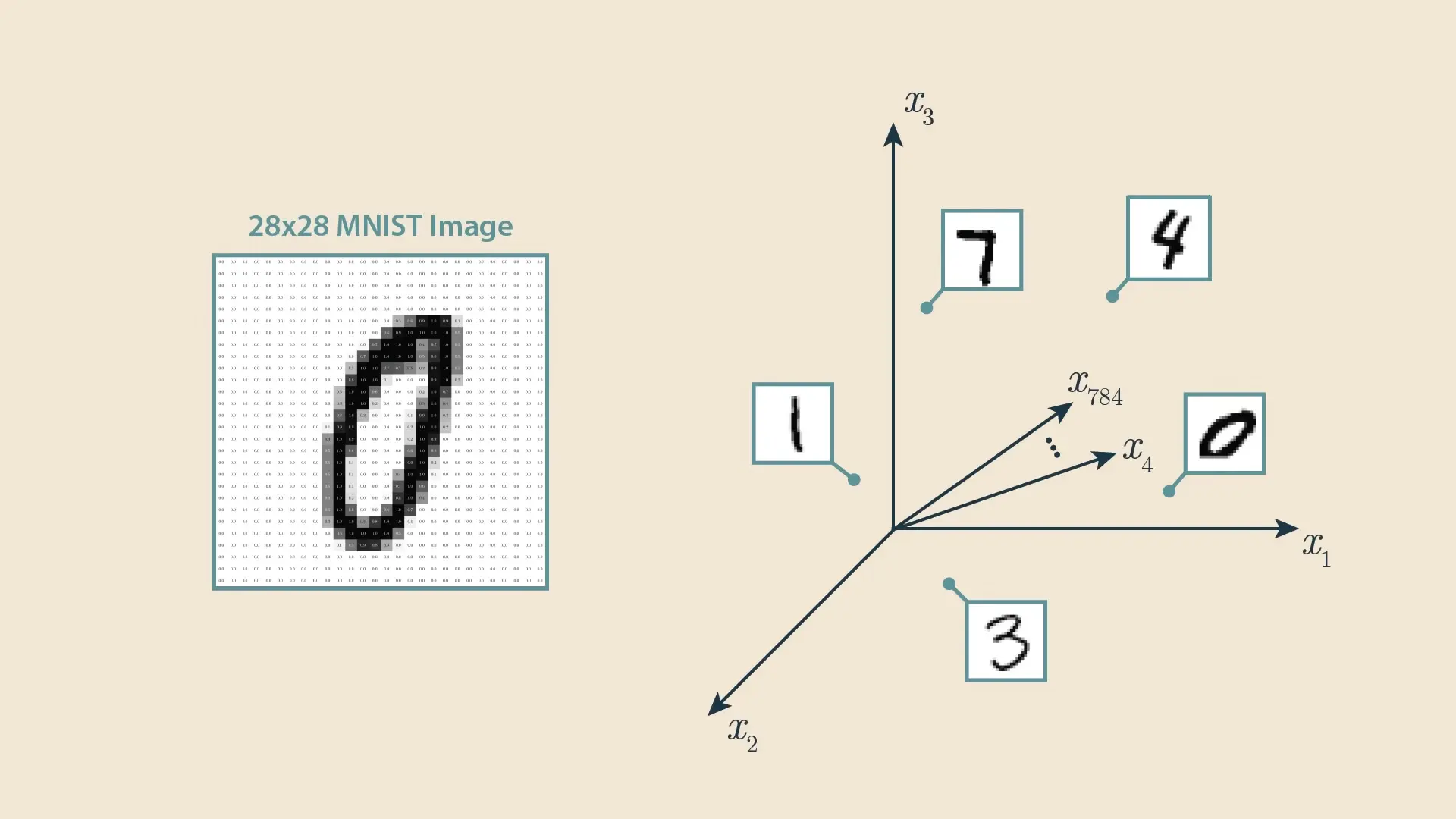
Neural networks learn by transforming input data into increasingly abstract feature representations. For instance, when processing MNIST digits, early layers detect edges, while deeper layers identify more complex patterns. This transformation creates a multi-dimensional feature space where similar concepts cluster together.
However, this approach leads to ai understanding problems. The models don't truly "understand" concepts as humans do – they map statistical patterns in high-dimensional spaces. This creates fundamental ai reasoning problems that scaling alone cannot solve.
Recent Developments: Confirming the Boundary
In more recent research, Google DeepMind conducted massive neural scaling experiments that confirmed curvature in the compute-efficient frontier for natural language. Their work suggests that even with infinite resources, AI models would still encounter irreducible error due to the entropy of natural text.
These findings support the existence of fundamental ai barriers that cannot be overcome simply by scaling current approaches. They've developed more sophisticated scaling laws that separate loss into three components: one scaling with model size, one with dataset size, and an irreducible term representing the entropy of natural text.
Implications for the Future of AI Research
Understanding these limitations has profound implications for the frontier of ai research. If current neural network approaches are approaching fundamental limits, breakthrough advances may require entirely new paradigms rather than just larger models.
- Researchers may need to develop novel architectures that overcome current limitations
- Hybrid approaches combining neural networks with symbolic reasoning might address ai reasoning problems
- Understanding the theoretical limits could help focus resources on more promising directions
- New metrics beyond cross-entropy loss may better capture human-like understanding
- Addressing ai explainability problems becomes crucial as we push against these boundaries
Conclusion: The Mystery at the Frontier
The discovery of neural scaling laws and their implied boundaries represents one of the most significant findings in modern AI research. These laws reveal that while we can continue improving AI by scaling up resources, we will eventually hit fundamental limits that cannot be overcome without radically new approaches.
This unexplained ai behavior – the inability to cross certain performance thresholds – reminds us that despite impressive achievements, artificial intelligence remains fundamentally different from human intelligence. Understanding these differences and limitations may ultimately lead to the next breakthrough in AI research, potentially addressing current ai weaknesses and unsolved problems that scaling alone cannot solve.
Let's Watch!
The Mysterious Boundary AI Can't Cross: Understanding Neural Scaling Laws
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence