Nvidia's Secret Weapon: How the 9B Parameter Neotron Nano v2 Outperforms Larger AI Models
Jamal Washington
Infrastructure Lead

While tech giants make flashy announcements about their newest AI models, Nvidia has quietly released a game-changing model that deserves more attention. The Neotron Nano version 2, with just 9 billion parameters, is challenging much larger models through an innovative architecture that prioritizes efficiency without sacrificing performance.
What Makes Neotron Nano v2 Different?
Neotron Nano v2 stands apart from conventional models through its hybrid architecture. Rather than relying solely on attention layers like Llama or Qwen, Neotron uses a strategic combination of attention and Mamba 2 layers. This architectural choice delivers several key advantages:
- More efficient handling of long sequences without the quadratic slowdown typical of attention-only models
- Smaller model size with lower memory requirements
- Faster inference speeds on modest hardware
- Comparable or sometimes better reasoning abilities than much larger transformer-only models
The integration of Mamba 2 layers is particularly significant for developers working with the nvidia nemo windows ecosystem or those using the nvidia a2 vgpu profiles for deployment. These specialized layers process sequential data with linear complexity rather than the quadratic complexity of traditional attention mechanisms, enabling the model to handle longer contexts more efficiently.
Reasoning Budget Control: A Unique Feature
One of the most innovative aspects of Neotron Nano v2 is its reasoning budget control feature. This capability allows developers to set specific token limits for the model's reasoning process during inference, creating a customizable trade-off between processing speed and reasoning depth.
For applications running on nvidia vm environments or systems with gpu-nvta2 configurations, this feature provides unprecedented control over latency. Developers can fine-tune the reasoning budget based on their specific hardware constraints or application requirements, making Neotron particularly valuable for production deployments with strict performance parameters.

Performance Benchmarks: How Does It Compare?
When tested against standard benchmarks, Neotron Nano v2 consistently matches or outperforms models like Qwen 3 on reasoning, mathematics, and sometimes even coding tasks. This is remarkable considering its relatively modest 9 billion parameter size compared to competitors with significantly larger parameter counts.
In practical testing with logic puzzles that challenge many similarly-sized models, Neotron demonstrated impressive reasoning capabilities. It correctly solved the "three-legged llama" problem, the "David's brothers" question, and the complex "students and buses" optimization challenge - all while showing its step-by-step reasoning process.
Practical Deployment: Running Neotron on Your Own Hardware
For those interested in trying Neotron Nano v2, the model is available through Hugging Face and can be deployed using VLLM. Here's a simplified deployment process that works well with the nemo service nvidia ecosystem:
- Access the model through Hugging Face (not yet available on Ollama at time of writing)
- Use a cloud GPU provider like RunPod.io with an A40 or similar GPU
- Select a VLLM template and modify the container start command to point to the Neotron model
- Configure appropriate parameters for Neotron and provide your Hugging Face API token
- Connect the deployed model to a chat interface like Next.js VLLM UI for a user-friendly experience
This deployment approach is particularly effective for those working with gpu-nva2-nc configurations or similar Nvidia hardware setups, as the model is optimized to work efficiently with Nvidia's architecture.
Coding Capabilities: A Mixed Performance
While Neotron excels at reasoning tasks, its coding capabilities show both strengths and limitations. When tested with complex programming challenges like creating a ball physics simulation in a rotating hexagon, the model produced working code with some flaws - the simulation had missing elements and collision detection issues.
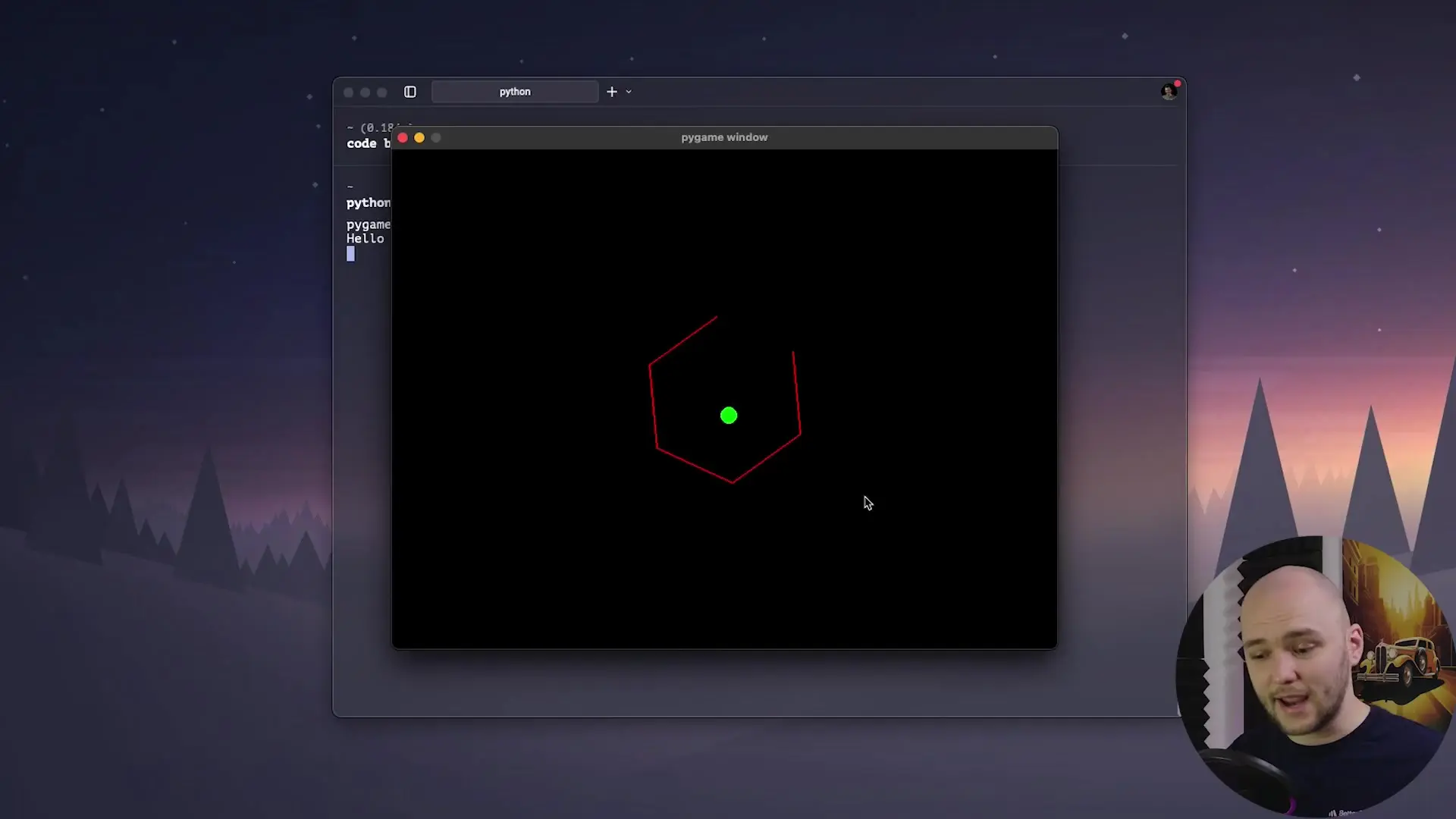
Similarly, when asked to create a snake game, Neotron correctly implemented the basic movement mechanics but struggled with collision detection and growth mechanics. It's important to note that Neotron wasn't specifically optimized for code generation - it was designed as a general reasoning model, making its coding performance still impressive for its size.
Efficiency With Reasoning Budget Control
The reasoning budget control feature proves particularly valuable in practical applications. When tested with a tight token limit, Neotron still solved complex problems efficiently:
- The three-legged llama problem was solved using only 78 tokens
- Even the more complex student bus problem was solved under a 500 token limit
This efficiency makes Neotron an excellent choice for scenarios with limited computational resources or strict latency requirements. For developers working with nvidia riva vs nemo integrations or building applications for resource-constrained environments, this balance of performance and efficiency is particularly valuable.
The Future Implications for Nvidia and the AI Landscape
Neotron Nano v2 represents more than just another AI model - it demonstrates Nvidia's growing ambitions in the AI stack. With control over both hardware and increasingly sophisticated software models, Nvidia is positioning itself as a comprehensive AI solution provider.
If Nvidia continues developing models that combine this level of efficiency and capability, they could reshape the AI landscape. For organizations already invested in the nvidia/nemo ecosystem or using nvem v2 mach3 technologies, this vertical integration offers significant advantages in optimization and performance.

Conclusion: Is Neotron Nano v2 Right for Your Projects?
Neotron Nano v2 offers an impressive combination of efficiency, reasoning capabilities, and innovative features like reasoning budget control. For developers working with limited computational resources or requiring low-latency responses, this model provides capabilities that were previously available only in much larger models.
While its coding capabilities have room for improvement, its core reasoning strengths make it an excellent choice for a wide range of applications. As Nvidia continues to refine its AI offerings, models like Neotron demonstrate how architectural innovation can sometimes be more impactful than simply scaling up parameter counts.
For those looking to experiment with powerful yet efficient AI models within the nvidia nemo windows ecosystem, Neotron Nano v2 deserves serious consideration. Its balance of performance and efficiency, combined with the unique reasoning budget control feature, makes it a standout option in an increasingly crowded field of large language models.
Let's Watch!
Nvidia's Secret Weapon: How Neotron Nano v2 Outperforms Larger AI Models
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence