The Surprising Truth About Reinforcement Learning in LLMs: What Recent Research Reveals
Priya Narayan
Systems Architect

The landscape of reinforcement learning (RL) in Large Language Models (LLMs) has undergone a significant shift in recent weeks. What once was heralded as a promising technique to help LLMs discover new reasoning paths has now been called into question, with emerging research suggesting that RL might not be able to discover anything truly new at all. This revelation has profound implications for how we understand and approach the development of more capable language models.
Understanding Reinforcement Learning in LLMs
Before diving into the recent revelations, it's important to understand how reinforcement learning fits into the LLM development pipeline. After pre-training a language model on a massive corpus of text to predict the next word, developers need to transform it from a simple autocomplete machine into a helpful assistant that can follow instructions.
This transformation typically begins with fine-tuning the model on human-labeled data that demonstrates ideal chat dialogues. However, the limited availability of such data led to the development of Reinforcement Learning from Human Feedback (RLHF).
In RLHF, researchers train a reward model from human-labeled data to rank LLM responses according to human preferences. This reward model then automatically evaluates the answers generated by the LLM, producing rewards that optimize the model through an algorithm called Proximal Policy Optimization (PPO) with a KL divergence penalty.
PPO replaces the next token prediction paradigm of pre-training with a preference for answers that receive better scores. The KL divergence penalty prevents the model from changing its behavior too drastically by measuring how much the new model's predictions differ from its previous ones.
The Rise of RLVR: Reinforcement Learning from Verifiable Rewards
While RLHF has been a cornerstone of LLM development, this article focuses on a more recent approach: Reinforcement Learning from Verifiable Rewards (RLVR). Unlike RLHF, which relies on subjective human preferences, RLVR uses deterministic rewards based on verifiable correctness.
RLVR eliminates the need for training a separate reward model by implementing a systematic way to check if an answer is correct, providing binary feedback. This approach is particularly well-suited for domains like mathematics and coding, where correctness can be automatically verified.
A key component of modern RLVR implementations is Group Relative Policy Optimization (GRPO), which gained popularity with the release of DeepSeek R1. Instead of maximizing rewards evaluated by a separate model, GRPO compares the performance of different outputs from the same model within a group (such as multiple answers to the same question) and assigns rewards relatively.
The Revelation: What Recent Research Shows About RL in LLMs
The narrative around RLVR initially suggested that this method would enable models to self-improve and discover new reasoning strategies. However, recent research has challenged this assumption, revealing that RL methods may only promote or amplify existing knowledge within an LLM rather than creating new reasoning processes.
A paper titled "Understanding R10-like Training: A Critical Perspective," published two months after DeepSeek R1, demonstrated that the much-celebrated "aha moment" was not actually a result of RLVR training. The model was already capable of exhibiting self-reflection before RLVR; the training simply enhanced this pre-existing behavior.
Furthermore, the researchers observed that responses with self-reflection did not necessarily achieve higher accuracy than those without it. They also challenged the belief that increased output length correlates strongly with performance improvement.
The actual reason GRPO generates increasingly longer responses over time is not because longer answers are more accurate, but because of a feature in GRPO where wrong responses are penalized less than shorter responses, naturally encouraging verbosity.
Does RL Actually Enhance Reasoning Capacity in LLMs?
Another paper, "Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?," took a harder look at RLVR and reached a striking conclusion: RLVR only reshapes the probability distribution of answers, making correct trajectories easier to hit, but does not add any new reasoning paths that weren't already present in the base model.
The researchers observed this pattern by sampling up to 1,000 completions across various models, RL optimization algorithms, and datasets. Their findings suggest that RL merely sharpens existing knowledge rather than introducing new capabilities.
In a surprising twist, they found that when sampling enough responses (over 128 samples), a vanilla 32B base model could outperform its RLVR-trained counterpart in total pass rates on the Minerva benchmark. This reveals how much latent ability exists in the tails of the probability distribution of base models.
The implication is clear: for creative problem-solving, you might have better luck with a base model using a large sampling parameter (K) than with a model that has undergone RLVR training, as RLVR tends to narrow the set of creative solutions the model can provide.
Distillation: A More Promising Path Forward
While the research casts doubt on RL's ability to introduce new reasoning capabilities, it did highlight a promising alternative: distillation. The study showed that a 7B model distilled from DeepSeek R1 could solve problems that the base model never could.
The distilled model's pass rate curve consistently outperformed the base model at all sampling values (K), demonstrating that new knowledge was genuinely added to the model through the distillation process. This suggests that distillation may be a more effective approach for compressing knowledge and transferring reasoning capabilities between models.
The Sparse Nature of RL Updates in LLMs
Further research titled "RL Fine-tune Small Subnetworks in LLMs" revealed another surprising aspect of reinforcement learning in LLMs: when DeepSeek researchers were developing DeepSeek R1, approximately 86% of parameters from the base model were not updated during RL training.
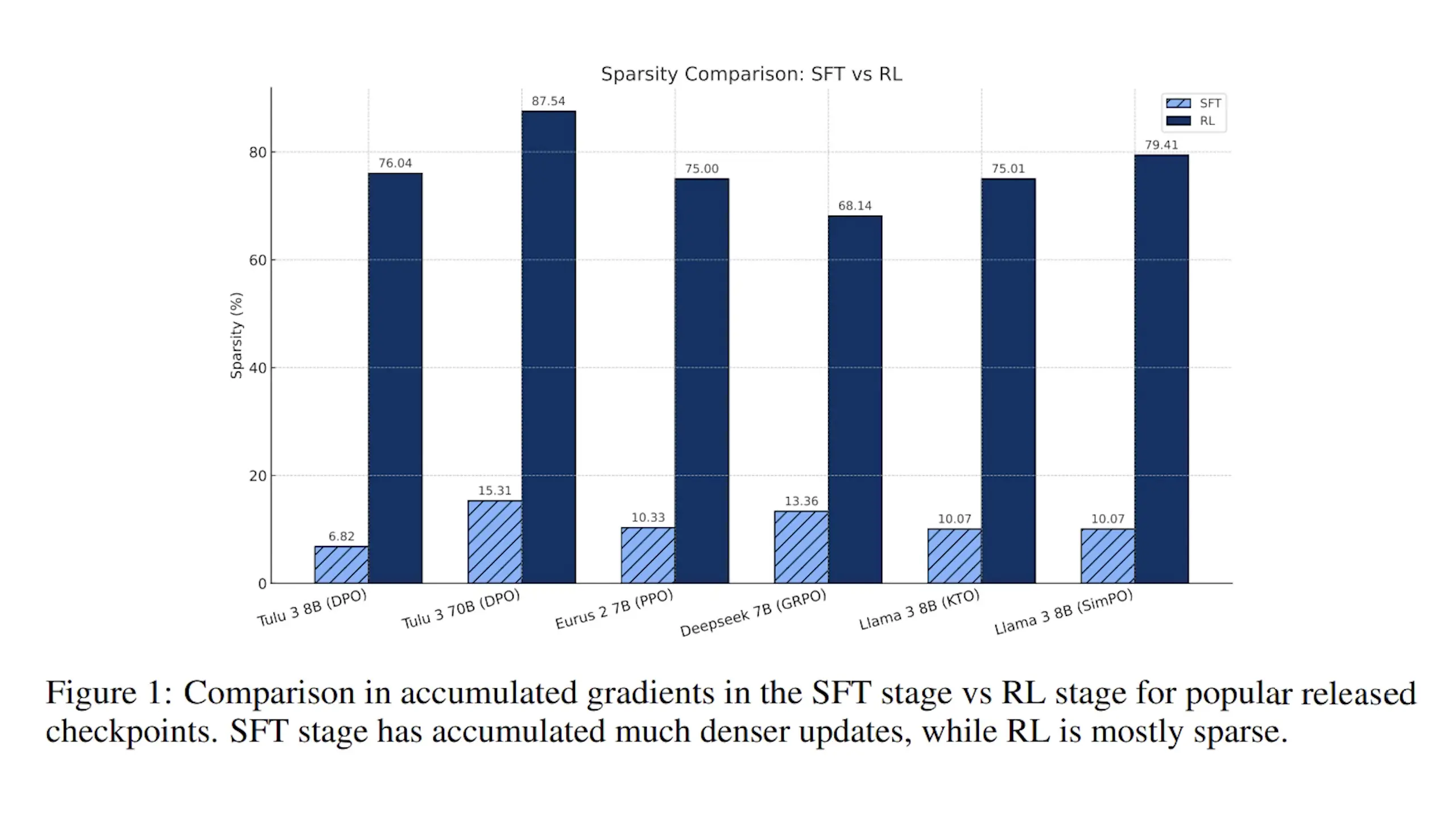
This pattern was observed across various RL algorithms applied to LLMs. While some parameter stability was expected due to KL divergence constraints, the fact that 70-95% of parameters remained untouched—with 72% never receiving any gradients at all—significantly changes our understanding of how RL affects these models.
The researchers found that RL gradients are naturally sparse, and this sparsity is not random. PPO, for instance, touches only about 30% of the MLP and attention weights, but those changes are in full rank, indicating that they are deliberate and intentional.
Remarkably, when the researchers reran RL training by targeting only those specific weights while freezing everything else, they were able to reproduce 98% of the performance of the full model. This suggests that RL's impact is highly concentrated in specific parts of the network.
Implications for the Future of LLM Development
These findings have significant implications for how we approach LLM development going forward. If RL primarily amplifies existing knowledge rather than creating new reasoning capabilities, then the quality of the pre-training data and process becomes even more crucial.
For researchers and developers, this suggests several strategic considerations:
- Focus on high-quality, diverse pre-training data that contains the reasoning patterns you want the model to exhibit
- Consider distillation as a more effective method for transferring reasoning capabilities between models
- When using RL, be aware that you're primarily reshaping probability distributions rather than teaching new skills
- For creative problem-solving applications, consider using base models with high sampling parameters instead of RL-tuned models
- Targeted parameter updates might be more efficient than full-model RL training
Teaching LLMs to Self-Verify and Self-Correct
Despite the limitations of RL in discovering new reasoning paths, research continues on how to leverage reinforcement learning to teach LLMs to self-verify and self-correct their outputs. This remains a valuable application area, particularly in domains where verifiable feedback is available.
The key insight is that while RL may not create new reasoning capabilities, it can effectively amplify and prioritize existing verification and correction mechanisms that the model has encountered during pre-training. By providing clear rewards for accurate self-checking, models can learn to more consistently apply these skills.

Conclusion: Reassessing the Role of Reinforcement Learning in LLMs
The recent research findings on reinforcement learning in LLMs challenge our previous understanding of how these models improve. Rather than discovering new reasoning paths, RL appears to primarily reshape probability distributions to favor certain outcomes that were already possible in the base model.
This doesn't mean that RL is without value in LLM development. It remains an effective tool for aligning models with human preferences and for enhancing specific capabilities that already exist in some form. However, these findings suggest that the pre-training era is far from over—in fact, it may be more important than ever.
As we continue to develop more capable language models, a balanced approach that combines high-quality pre-training, targeted reinforcement learning, and effective knowledge distillation may provide the best path forward. By understanding the true nature and limitations of each technique, we can develop more efficient and effective strategies for advancing LLM capabilities.
Let's Watch!
The Surprising Truth About Reinforcement Learning in LLMs
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence