The Ultimate Guide to Machine Learning Algorithms: How to Choose the Right One for Any Problem
Sophia Okonkwo
Technical Writer

Machine learning is revolutionizing industries across the globe, but choosing the right algorithm for your specific problem can feel overwhelming. This comprehensive guide breaks down the most important machine learning algorithms, provides an intuitive understanding of each, and offers a simple strategy for selecting the perfect algorithm for any data challenge.
What is Machine Learning?
According to the formal machine learning definition, it's a field of study in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalize to unseen data, thus performing tasks without explicit instructions. Much of the recent advancements in AI are driven by neural networks and other sophisticated algorithms that we'll explore in this article.
The Two Main Branches of Machine Learning
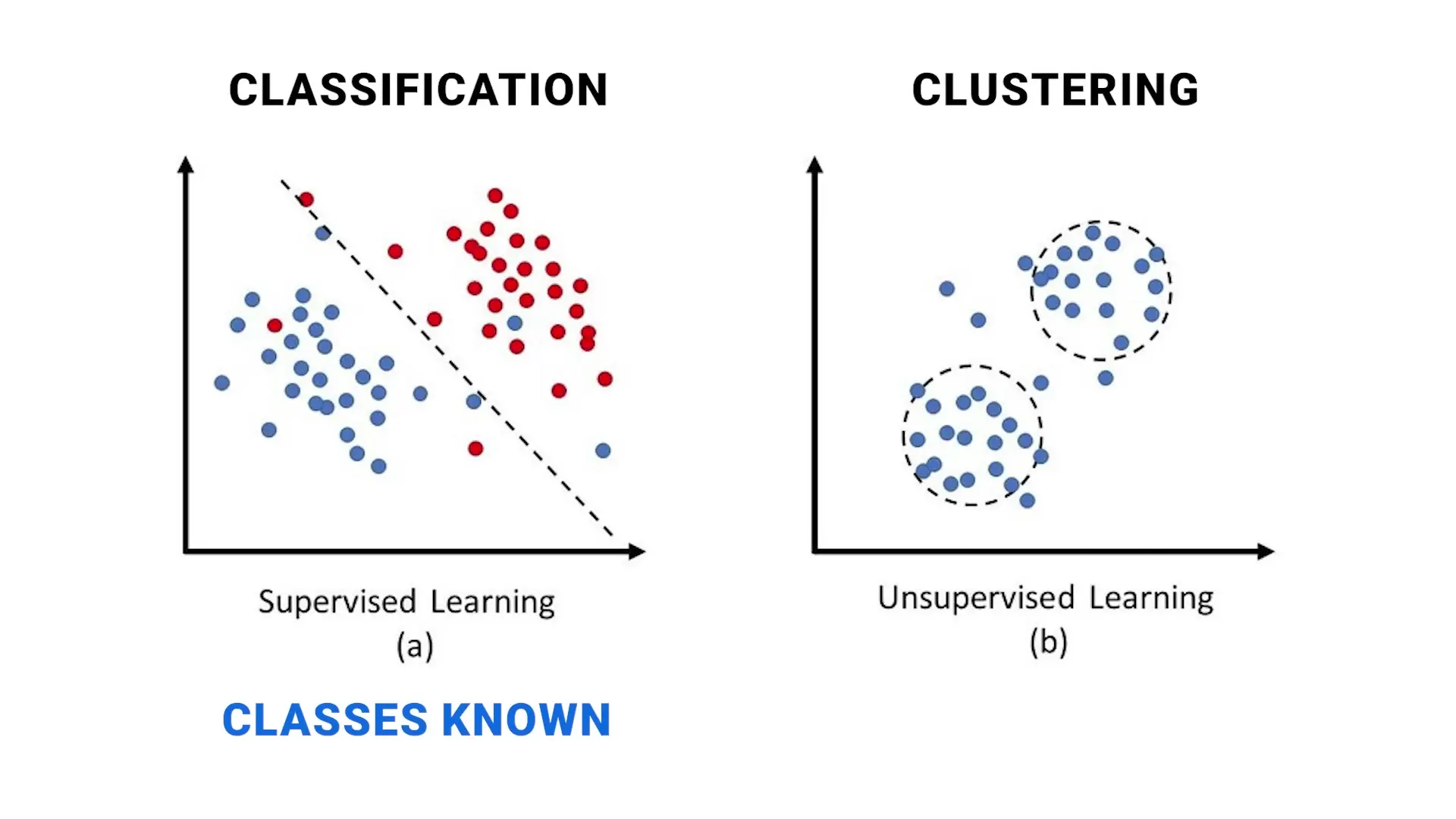
Machine learning is typically divided into two primary categories: supervised learning and unsupervised learning. Understanding this fundamental division is the first step in selecting the right algorithm for your problem.
Supervised Learning
In supervised learning, we work with labeled data. This means we have a dataset with input variables (features) and a corresponding output variable (target) that we want to predict. The algorithm learns the relationship between inputs and outputs from training data where the correct answers are provided, then applies this knowledge to make predictions on new, unseen data.
Examples of supervised learning include:
- Predicting house prices based on features like square footage, location, and year of construction
- Categorizing objects as cats or dogs based on image features
- Determining whether an email is spam or not based on its content and sender information
Unsupervised Learning
Unsupervised learning deals with unlabeled data where no truth about the data is known. The algorithm must find patterns, structures, or relationships within the data without explicit guidance.
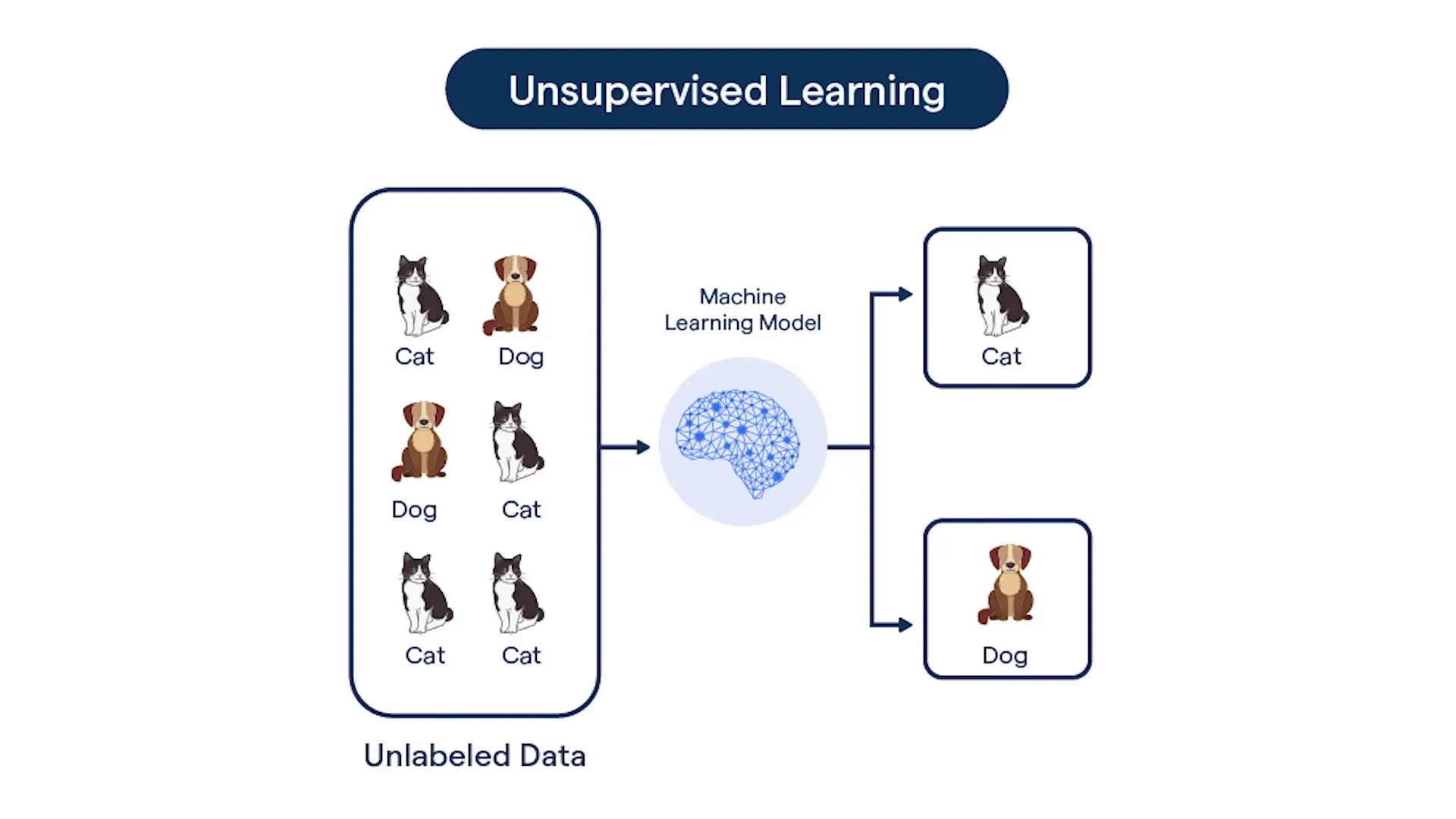
To illustrate the difference: supervised learning is like showing a child pictures of cats and dogs with labels, then asking them to identify a new animal. Unsupervised learning is like giving a child who has never seen animals before a pile of pictures and asking them to group similar ones together without any guidance.
Examples of unsupervised learning include:
- Sorting emails into unspecified categories that you can later name
- Customer segmentation for marketing purposes
- Anomaly detection in network traffic or financial transactions
Supervised Learning Algorithms
Supervised learning can be further divided into regression (predicting continuous values) and classification (predicting discrete categories). Let's explore the most important algorithms in each category.
Linear Regression
Linear regression is often considered the mother of all machine learning algorithms. It attempts to establish a linear relationship between input and output variables by fitting a line to the data that minimizes the sum of squared distances between the actual data points and the regression line.
This algorithm is ideal for problems where you can reasonably assume a linear relationship exists between variables. For example, the relationship between a person's height and shoe size might be approximately linear. The algorithm will tell you that for every one unit increase in shoe size, a person might be, on average, 2 inches taller.
You can extend linear regression to handle multiple input features (multivariate linear regression), making it more powerful for complex real-world problems.
Logistic Regression
Despite its name, logistic regression is a classification algorithm, not a regression algorithm. It's an extension of linear regression adapted for classification tasks.
Instead of fitting a straight line, logistic regression fits a sigmoid function to the data, which conveniently outputs values between 0 and 1 that can be interpreted as probabilities. For example, it might predict that an adult person with a height of 180cm has an 80% probability of being male.
Logistic regression is particularly useful for binary classification problems (two classes), though it can be extended to handle multiple classes.
K-Nearest Neighbors (KNN)
The K-Nearest Neighbors algorithm is an intuitive and versatile algorithm that can be used for both classification and regression tasks. It's a non-parametric method, meaning it doesn't try to fit parameters to a model.
The core idea is beautifully simple: for any new data point, predict its value or class based on the K nearest data points in the training set. For classification, this means assigning the most common class among the K neighbors. For regression, it means taking the average value of the K neighbors.
For example, to predict a person's gender using KNN, we might look at the 5 people most similar in height and weight and assign the majority gender. For predicting weight, we might average the weights of the 3 people closest in height and chest circumference.
The choice of K (the number of neighbors to consider) is a critical hyperparameter that significantly impacts performance:
- Too small (e.g., K=1 or 2): The model will fit training data perfectly but won't generalize well (overfitting)
- Too large (e.g., K=1000): The model will be too generalized and perform poorly (underfitting)
- The optimal K value depends on your specific dataset and problem
Support Vector Machines (SVM)
Support Vector Machines are powerful supervised learning algorithms primarily designed for classification but adaptable for regression. SVMs work by finding the optimal decision boundary (hyperplane) that maximizes the margin between different classes.
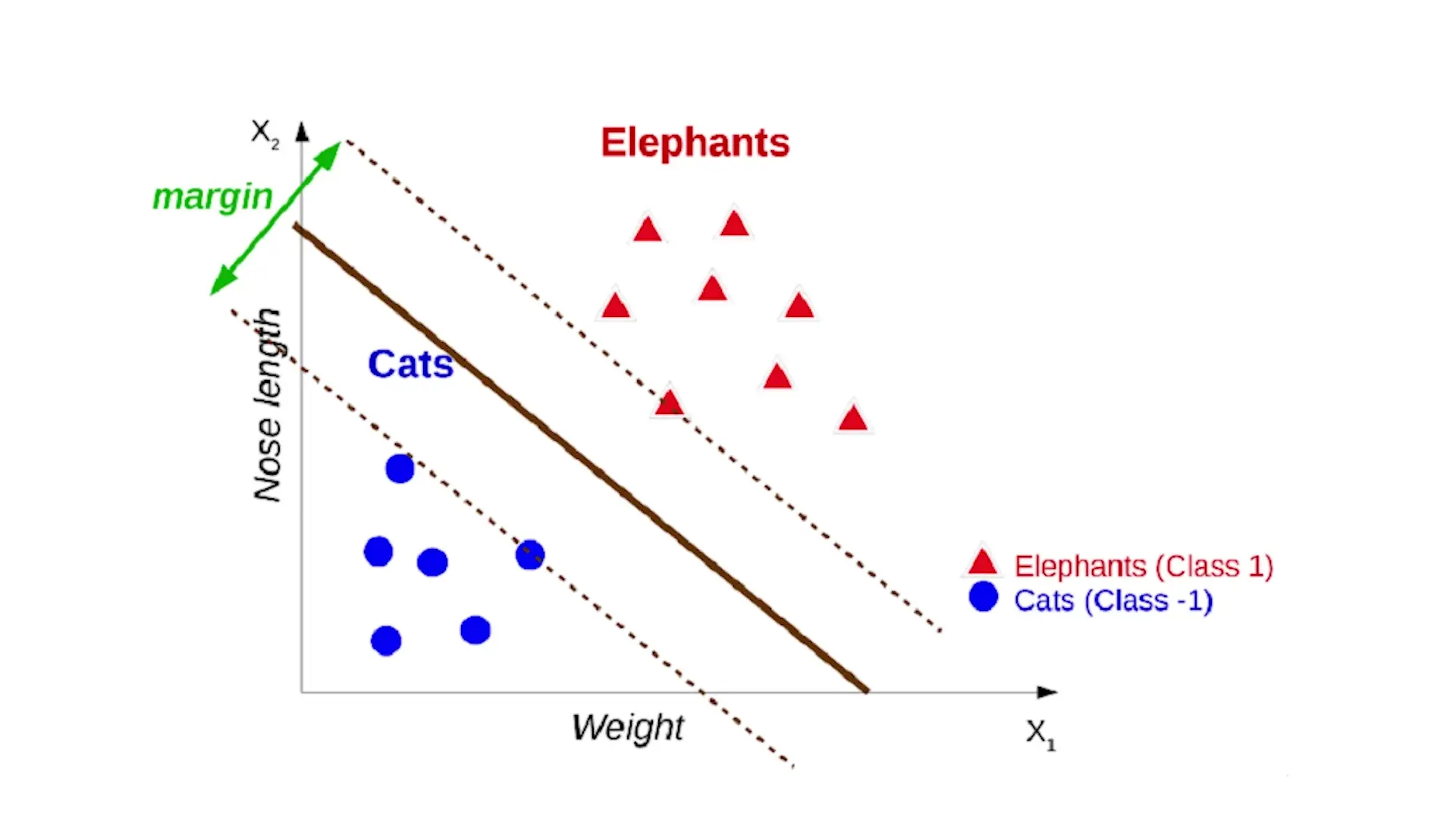
In the example of classifying cats and elephants based on weight and nose length, an SVM would find the line that separates the two classes with the largest possible margin. The data points that lie on the edge of this margin are called support vectors, and they're the only points needed to define the decision boundary.
Key advantages of SVMs include:
- Effectiveness in high-dimensional spaces where features outnumber data points
- Memory efficiency since only support vectors are needed for classification
- Versatility through kernel functions that allow for complex, non-linear decision boundaries
Kernel functions are a powerful feature of SVMs that implicitly transform the original features into more complex ones, enabling the algorithm to find non-linear decision boundaries without explicitly computing the transformations (known as the 'kernel trick').
Unsupervised Learning Algorithms
K-Means Clustering
K-means is one of the most popular unsupervised learning algorithms, used for partitioning data into K distinct clusters based on similarity. The algorithm works by iteratively assigning data points to the nearest cluster center and then recalculating those centers.
Applications of K-means clustering include:
- Customer segmentation for targeted marketing
- Document classification
- Image compression
- Anomaly detection
Like KNN, choosing the right value of K (the number of clusters) is crucial and depends on the specific problem and dataset.
How to Choose the Right Machine Learning Algorithm
Selecting the appropriate algorithm for your specific problem is a critical decision that impacts the success of your machine learning project. Here's a simple strategy to guide your choice:
- Define your problem: Is it supervised (with labeled data) or unsupervised (without labels)?
- For supervised learning, determine if it's a regression problem (predicting continuous values) or classification (predicting categories)
- Consider your data characteristics: size, dimensionality, linearity of relationships
- Factor in computational constraints: some algorithms are more resource-intensive than others
- Start simple: Begin with basic algorithms (linear/logistic regression) before moving to more complex ones
- Evaluate multiple algorithms: Compare performance using appropriate metrics for your problem type
- Fine-tune hyperparameters: Optimize the chosen algorithm(s) for your specific dataset
Algorithm Selection Guide
Here's a quick reference guide for choosing algorithms based on common problem types:
- For simple linear relationships: Linear Regression (regression) or Logistic Regression (classification)
- For complex, non-linear relationships: SVMs with kernels, Neural Networks
- When interpretability is crucial: Decision Trees, Linear/Logistic Regression
- For high-dimensional data: SVMs, Principal Component Analysis (for dimensionality reduction)
- When you have limited labeled data: KNN, SVMs
- For grouping similar items: K-Means Clustering
- For detecting unusual patterns: Isolation Forests, One-Class SVM
Conclusion
Understanding the fundamental machine learning algorithms and their appropriate applications is essential for anyone working in data science or AI. By following the simple strategy outlined in this guide, you can confidently select the right algorithm for your specific problem, avoiding the overwhelm that often comes with the vast machine learning landscape.
Remember that no single algorithm is universally best for all problems. The right choice depends on your specific data, problem constraints, and goals. Often, the most effective approach is to try multiple algorithms and let the results guide your final decision.
Whether you're just starting your machine learning journey or looking to expand your algorithmic toolkit, this guide provides the foundation you need to make informed choices and build effective models for real-world applications.
Let's Watch!
The Ultimate Guide to Machine Learning Algorithms: Which One Is Right for Your Problem?
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence