Understanding LLM Tokens in TypeScript: A Comprehensive Developer's Guide
Jamal Washington
Infrastructure Lead
Many developers are working with Large Language Models (LLMs) without understanding the fundamental concepts that power them. One of the most important concepts to grasp is tokens - the basic units that LLMs process. In this deep dive, we'll explore what tokens are, how they work, and why they matter, all through the lens of TypeScript code examples.
What Are Tokens in LLMs?
Tokens are the currency of LLMs. When you send an input like "Hello World" to an LLM, that text gets broken down into its constituent tokens. These tokens are then processed by the model, which produces output tokens that are converted back into human-readable text.
Each LLM provider has their own tokenization system. For example, sending "Hello World" to OpenAI might result in 3 tokens, while the same prompt sent to different models could result in different token counts. This variation affects both processing and cost, as LLM providers typically charge based on the number of tokens processed.
How Token Counting Works
Let's demonstrate token counting using the AI SDK with different models:
// Using Anthropic's Claude 3.5 Haiku
const anthropicResponse = await anthropic.messages.create({
model: "claude-3-haiku-20240307",
max_tokens: 1000,
messages: [{ role: "user", content: "Hello world" }]
});
console.log("Text:", anthropicResponse.content);
console.log("Usage:", anthropicResponse.usage);
// Output: 11 input tokens, 20 output tokens
// Using Google's Gemini 2.0 Flashlight
const googleResponse = await genAI.generateContent({
model: "gemini-2.0-flashlight",
contents: [{ role: "user", parts: [{ text: "Hello world" }] }]
});
console.log("Text:", googleResponse.text);
console.log("Usage:", googleResponse.usage);
// Output: 4 input tokens, 11 output tokensWhy do we see different token counts for the same input? This is because each model has its own token vocabulary - a collection of words, subwords, and characters that it recognizes as individual tokens.
The Token Encoding Process
Every LLM has a different token vocabulary. These tokens are all the different words, subwords, and characters that the model knows. Each of these linguistic units gets assigned a number, and that number is the token.
When we call an LLM, it encodes the text we send it into tokens. For example, "Hello World" gets split up into its largest individual tokens in the vocabulary (which might be "hello", " ", "world"). The model then identifies the numbers in the vocabulary that match each word or subword.
We can examine this process using the JS TikToken library, a JavaScript implementation of OpenAI's tokenizer:
import { Tiktoken } from "js-tiktoken";
// Using the tokenizer for GPT-4o
const tokenizer = new Tiktoken("cl100k_base");
// Read some text
const content = "The wise owl of moonlight forest, where ancient trees stretch their branches toward the starry sky.";
// Encode the text into tokens
const tokens = tokenizer.encode(content);
console.log(`Content length: ${content.length} characters`);
console.log(`Number of tokens: ${tokens.length}`);
console.log(`Tokens: ${tokens}`);
// Try with a simpler example
const simpleContent = "Hello world";
const simpleTokens = tokenizer.encode(simpleContent);
console.log(`Content length: ${simpleContent.length} characters`);
console.log(`Number of tokens: ${simpleTokens.length}`);
console.log(`Tokens: ${simpleTokens}`);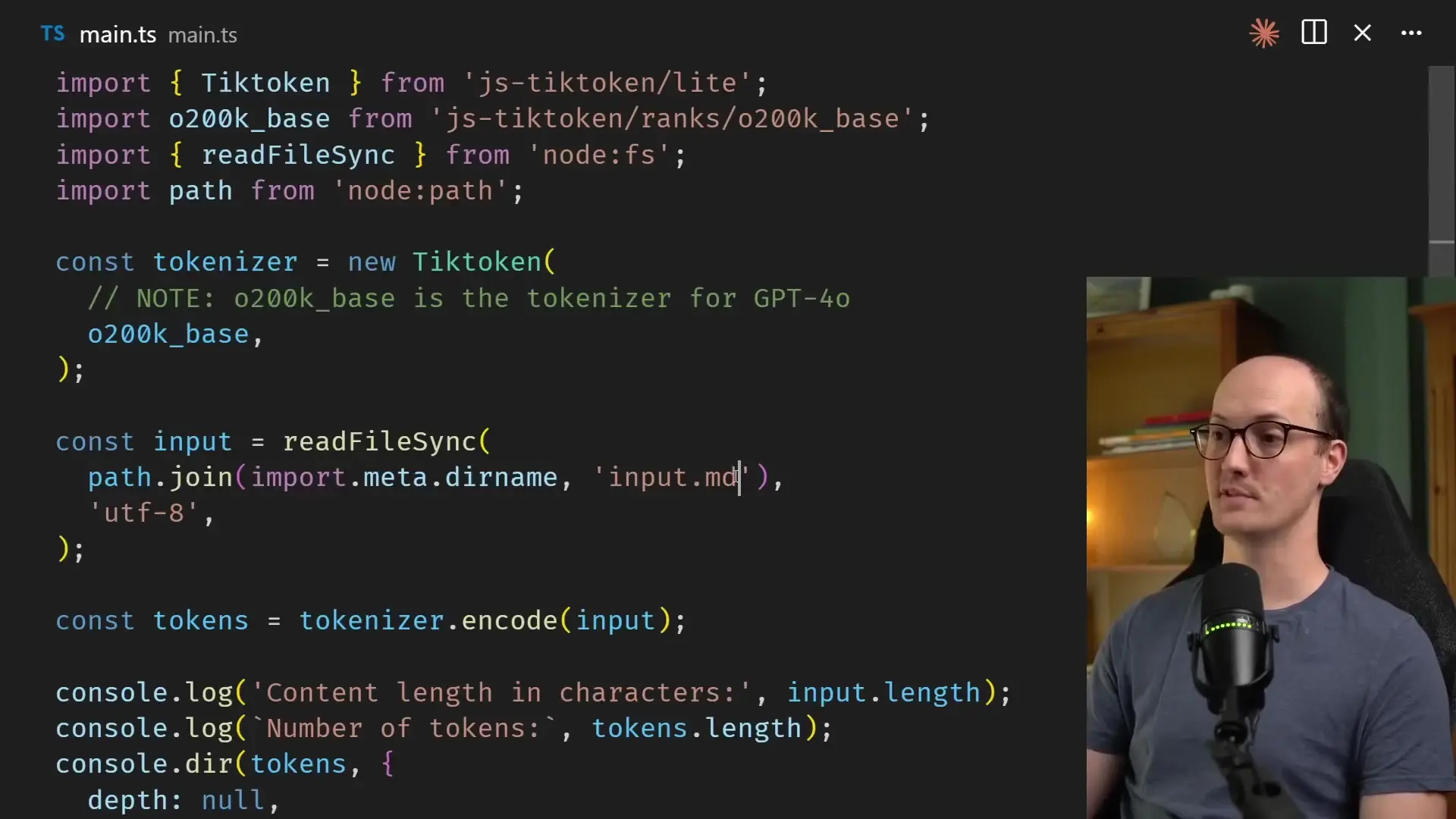
The Full LLM Process
Let's look at the complete LLM process from end to end:
- Text input (e.g., "Hello world") is sent to the model
- The text is split into the largest chunks recognized in the vocabulary
- These chunks are encoded into tokens (numbers) by looking up their assigned values in the vocabulary
- The LLM processes these tokens and generates output tokens
- The output tokens are decoded back into text by reversing the process
- The decoded text is returned as the response
It's important to understand that all the computation in an LLM is done on numbers (tokens), not on text directly. The model only deals with these numeric representations of chunks of text.
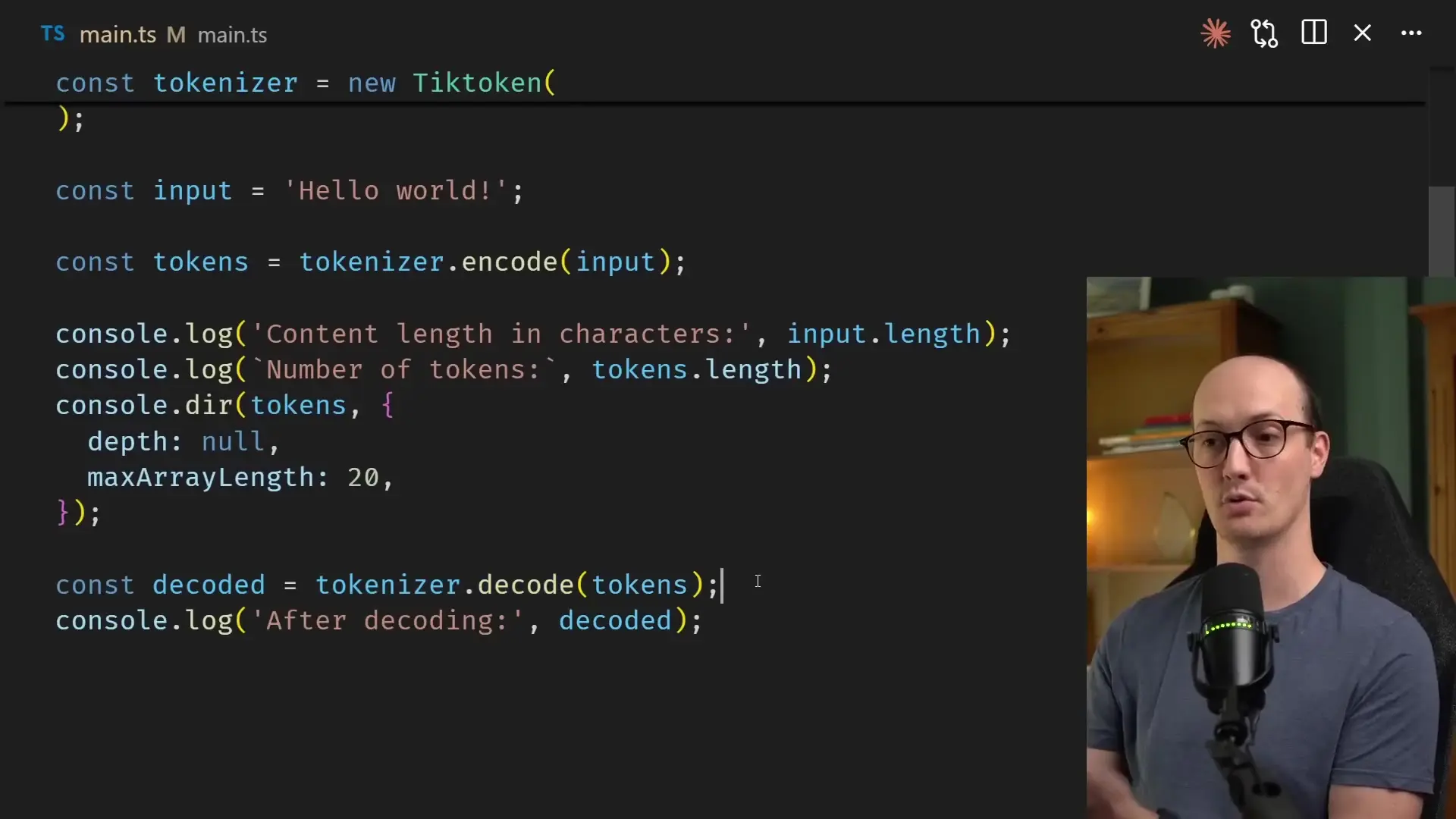
// Decoding tokens back into text
const decodedText = tokenizer.decode(tokens);
console.log(`Decoded text: ${decodedText}`);How Tokenizers Are Built
To understand why different models tokenize text differently, we need to explore how tokenizers are trained. Tokenizers are typically built using the same corpus of text that the model itself is trained on.
Let's implement a simple character-level tokenizer in TypeScript to understand the basics:
class CharacterLevelTokenizer {
private mapping: Record<string, number> = {};
private reverseMapping: Record<number, string> = {};
constructor(dataset: string) {
// Extract unique characters from the dataset
const uniqueChars = [...new Set(dataset)].sort();
// Assign a token ID to each unique character
uniqueChars.forEach((char, index) => {
this.mapping[char] = index;
this.reverseMapping[index] = char;
});
}
encode(text: string): number[] {
// Convert each character to its token ID
return [...text].map(char => this.mapping[char] || 0);
}
decode(tokens: number[]): string {
// Convert each token ID back to its character
return tokens.map(token => this.reverseMapping[token] || '').join('');
}
}
// Usage
const dataset = "the cat sat on the mat";
const tokenizer = new CharacterLevelTokenizer(dataset);
const input = "cats sat mat";
const tokens = tokenizer.encode(input);
console.log(`Input length: ${input.length} characters`);
console.log(`Number of tokens: ${tokens.length}`);
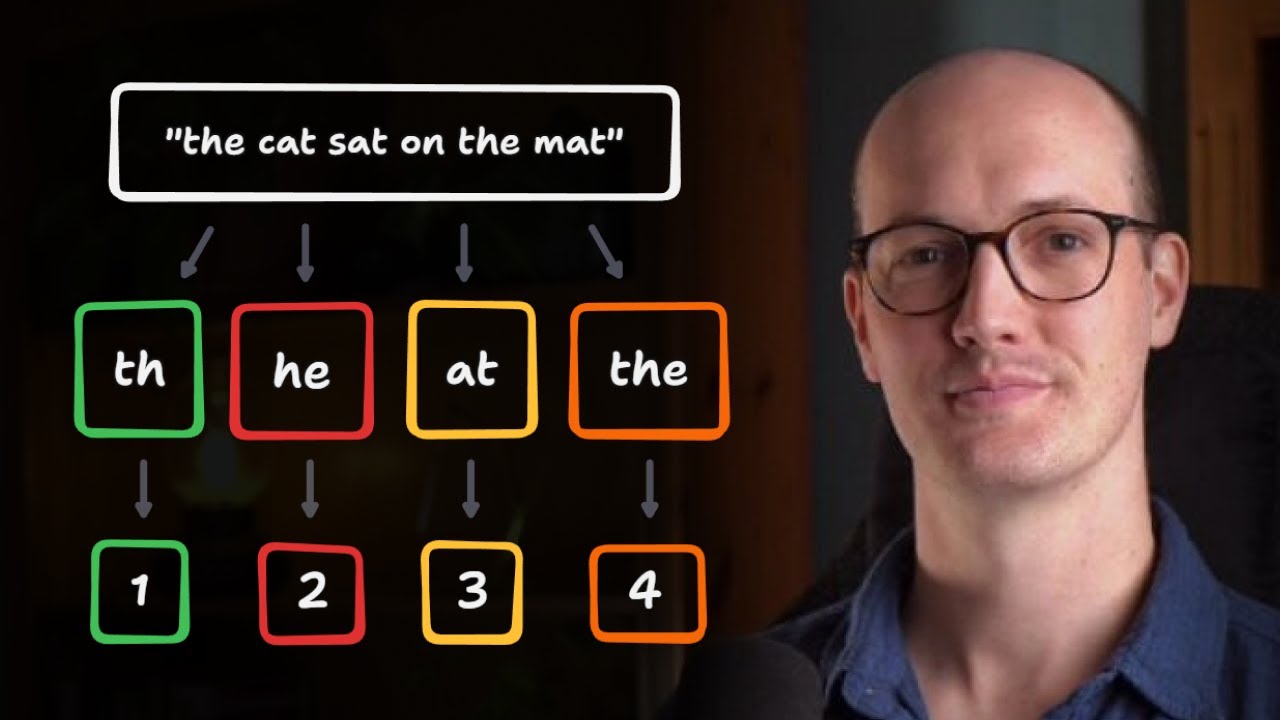
console.log(`Tokenizer vocabulary: ${JSON.stringify(tokenizer.mapping)}`);With this character-level tokenizer, the number of tokens will always equal the number of characters, which isn't efficient. Real tokenizers use subword tokenization to reduce the number of tokens needed to represent text.
Subword Tokenization
A more efficient approach is subword tokenization, which identifies common character sequences and treats them as single tokens. Here's a simplified implementation:
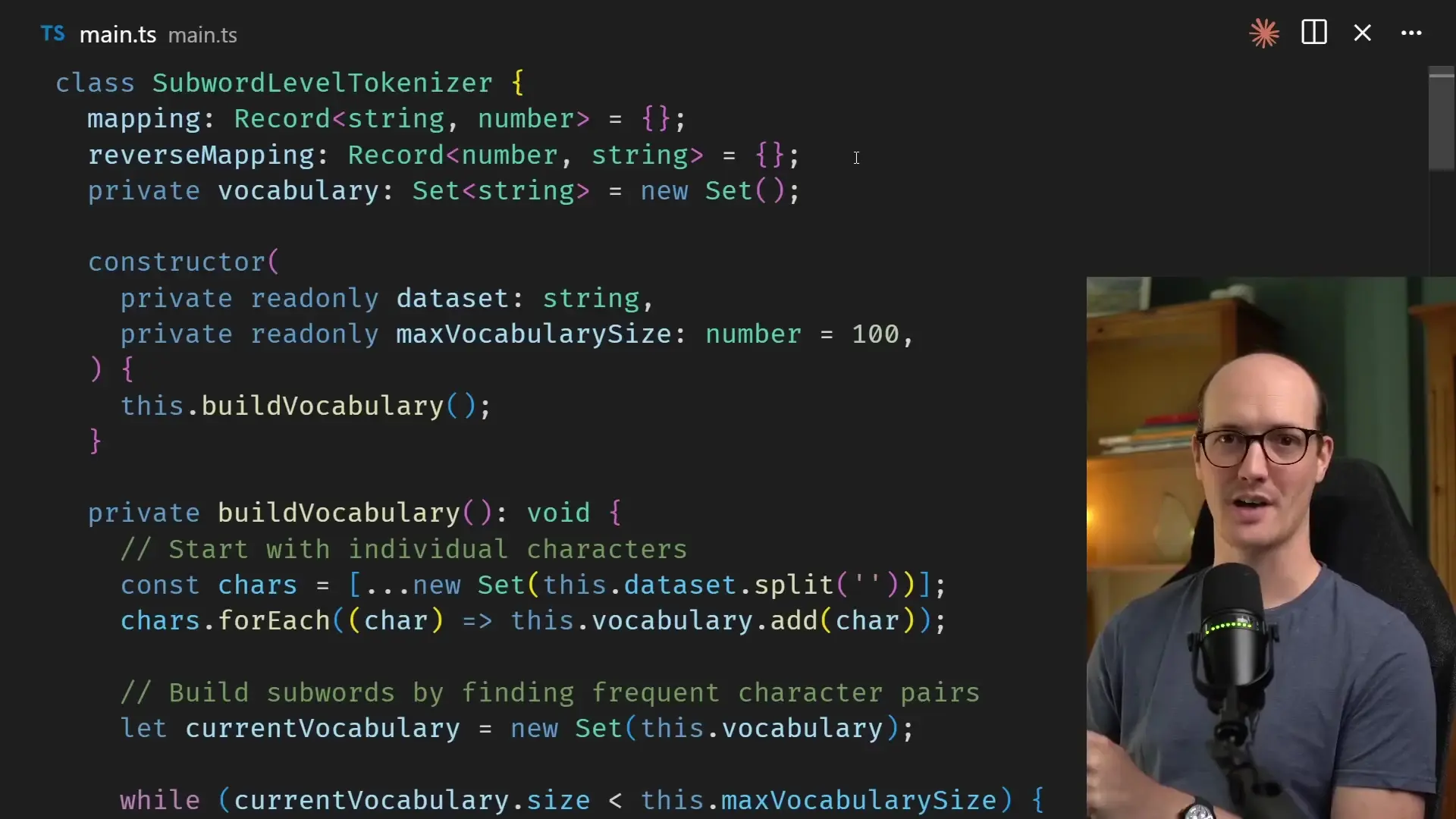
class SubwordLevelTokenizer {
private mapping: Record<string, number> = {};
private reverseMapping: Record<number, string> = {};
private subwords: string[] = [];
constructor(dataset: string) {
// First, add all individual characters
const uniqueChars = [...new Set(dataset)].sort();
let tokenId = 0;
uniqueChars.forEach(char => {
this.mapping[char] = tokenId;
this.reverseMapping[tokenId] = char;
tokenId++;
});
// Find common character pairs
for (let i = 0; i < dataset.length - 1; i++) {
const pair = dataset.substring(i, i + 2);
if (!this.subwords.includes(pair)) {
this.subwords.push(pair);
this.mapping[pair] = tokenId;
this.reverseMapping[tokenId] = pair;
tokenId++;
}
}
}
encode(text: string): number[] {
const tokens: number[] = [];
let i = 0;
while (i < text.length) {
// Try to match the longest possible subword
let matched = false;
// Check if we can match a 2-character subword
if (i < text.length - 1) {
const pair = text.substring(i, i + 2);
if (this.mapping[pair] !== undefined) {
tokens.push(this.mapping[pair]);
i += 2;
matched = true;
continue;
}
}
// If no subword matched, use the single character
if (!matched) {
tokens.push(this.mapping[text[i]] || 0);
i++;
}
}
return tokens;
}
decode(tokens: number[]): string {
return tokens.map(token => this.reverseMapping[token] || '').join('');
}
}
// Usage
const dataset = "the cat sat on the mat";
const tokenizer = new SubwordLevelTokenizer(dataset);
const input = "cats sat mat";
const tokens = tokenizer.encode(input);
console.log(`Input length: ${input.length} characters`);
console.log(`Number of tokens: ${tokens.length}`);
console.log(`Tokenizer vocabulary: ${JSON.stringify(tokenizer.mapping)}`);With this subword tokenizer, we can represent the same text with fewer tokens, making processing more efficient. Real tokenizers use more sophisticated algorithms to identify larger subword chunks based on frequency in the training corpus.
Vocabulary Size Trade-offs
The size of a tokenizer's vocabulary significantly impacts efficiency. With a small vocabulary of around 1,000 tokens, a word like "understanding" might be split into five tokens: "under", "st", "and", "ing". With a larger vocabulary of 50,000 tokens, it might be just two tokens: "under", "standing". The larger the vocabulary, the fewer tokens needed to represent text.
However, there's a trade-off: larger vocabularies increase model size and memory requirements. Different model providers make different decisions about this trade-off, which is why the same text can result in different token counts across models.
How Tokenizers Handle Unusual Words
When a tokenizer encounters an unusual word that wasn't common in its training data, it typically breaks it down into smaller subwords or even individual characters. For example, a made-up word like "frabjous" (from Lewis Carroll's poem) might be split into multiple tokens because it's not common in the training data.
// Tokenizing unusual words
const unusualText = "O frabjous day";
const unusualTokens = tokenizer.encode(unusualText);
console.log(`Text: ${unusualText}`);
console.log(`Tokens: ${unusualTokens}`);
console.log(`Number of tokens: ${unusualTokens.length}`);
// Decode to see how it was split
const decodedPieces = unusualTokens.map(t => tokenizer.decode([t]));
console.log(`Token pieces: ${JSON.stringify(decodedPieces)}`);This behavior has important implications for using LLMs with different languages or specialized domains. Text in languages that were less represented in the training data will typically require more tokens, as will technical jargon or domain-specific terminology.
Practical Implications for Developers
- Cost optimization: Understanding tokens helps you estimate and reduce API costs when working with LLMs
- Context window management: Since LLMs have limited context windows measured in tokens, efficient tokenization helps maximize the information you can include
- Performance considerations: Fewer tokens generally means faster processing
- Language support: Be aware that non-English languages may use more tokens, affecting costs and context limits
- Programming languages: Common programming languages like JavaScript typically tokenize more efficiently than less common ones
Summary
Tokens are the fundamental units that LLMs process. They represent words, subwords, or characters in a numeric format that models can work with. The process involves encoding text into tokens, processing those tokens, and then decoding the output tokens back into text.
Different model providers use different tokenization strategies, which is why the same text can result in different token counts. Understanding how tokenization works helps developers optimize their LLM applications for cost, performance, and effectiveness.
By implementing simple tokenizers in TypeScript, we've seen how the process works under the hood and gained insights into the trade-offs involved in tokenizer design. This knowledge is essential for any developer working with LLMs in production environments.
Let's Watch!
Understanding LLM Tokens in TypeScript: A Developer's Guide
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence