7 Essential Messaging Patterns for Building Resilient, Scalable Microservices Architecture
Sophia Okonkwo
Technical Writer
Building microservices that can handle billions of requests requires more than just basic knowledge of REST APIs and synchronous communication. As systems scale, the messaging patterns you choose become critical to maintaining reliability, performance, and fault tolerance. This guide explores advanced messaging strategies that solve real-world challenges in distributed systems.
The Challenge of Scaling Message Consumers While Preserving Order
When scaling microservices, one of the trickiest challenges is maintaining message order while increasing throughput. Imagine a scenario where a sender publishes three sequential events: order created, order updated, and order cancelled. If multiple service instances or threads process these messages in parallel, there's no guarantee they'll be handled in the correct sequence—potentially leading to data inconsistency and business logic errors.
Modern message brokers like Kafka and AWS Kinesis solve this problem through partitioned channels (also called shards). Here's how they work:
- Each channel is divided into multiple shards
- The sender includes a shard key (like an order ID) in the message header
- The broker hashes this key to determine which shard receives the message
- All messages with the same shard key are routed to the same shard
- Each shard is assigned to exactly one consumer instance at a time
This approach ensures that related messages (those sharing the same shard key) are processed in order, even as you scale horizontally. Consumer instances are typically grouped as one logical unit (called a consumer group in Kafka), and the broker automatically rebalances shard assignments as instances scale up or down.
Handling Duplicate Messages with Idempotent Consumers
In an ideal world, message brokers would deliver each message exactly once. However, the reality is that most brokers like Kafka, RabbitMQ, and AWS SQS implement an "at least once" delivery model, which means duplicates can and will occur.
Consider this scenario: a consumer processes a message, updates its database, but crashes before acknowledging receipt to the broker. The broker, not seeing an acknowledgment, assumes the message was lost and redelivers it—resulting in duplicate processing.
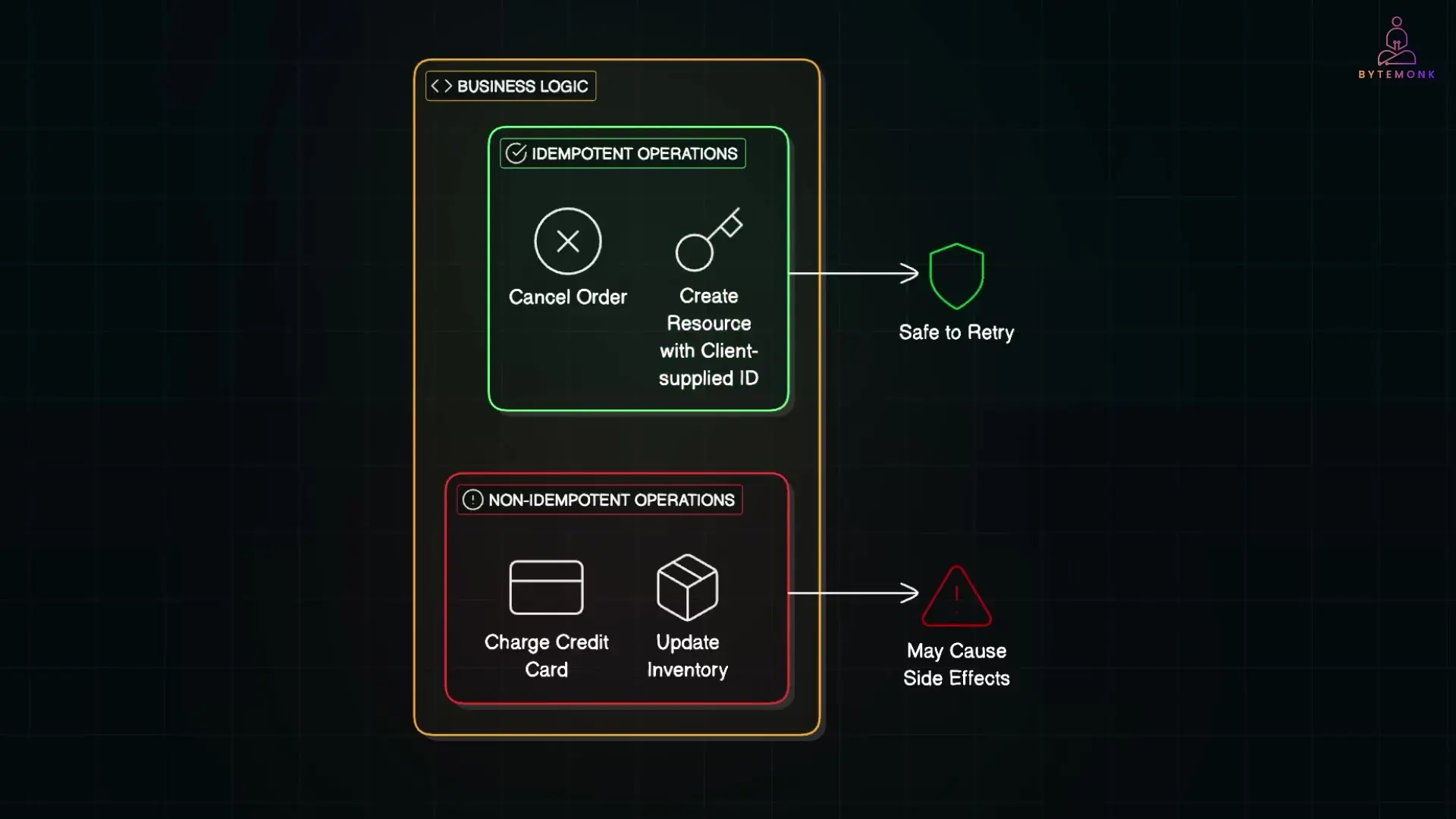
There are two main strategies to handle duplicate messages:
1. Write Idempotent Message Handlers
If your business logic is idempotent—meaning processing the same message multiple times has the same effect as processing it once—you're naturally protected against duplicates. Examples include:
- Canceling an already-canceled order
- Creating a resource with a client-supplied ID
- Setting a property to a specific value (rather than incrementing/decrementing)
2. Track and Discard Duplicate Messages
Since most business operations aren't naturally idempotent, you'll often need to implement duplicate detection. A clean approach is to maintain a record of processed message IDs:
- When a message arrives, log its unique message ID in a "processed_messages" table
- Make this part of the same transaction that performs your business logic
- If the message ID already exists, the insert fails, indicating a duplicate
- Discard duplicate messages without executing business logic again
This pattern effectively provides "exactly once" semantics on top of an "at least once" delivery model. For systems without full transaction support (like some NoSQL databases), you can embed the message ID directly in your business data tables as an alternative approach.
Choosing Between Synchronous and Asynchronous Communication
REST APIs are ubiquitous and often the default choice for service-to-service communication. However, REST is synchronous—the client sends a request and then waits for a response. This creates tight coupling between services, reducing overall system availability.
Consider an order service that needs to call both a consumer service and a restaurant service to validate a request. For this flow to succeed, all services must be available simultaneously. If any one service is down, the entire chain breaks.
The availability math is brutal: if each service is 99.5% available, the overall availability quickly drops below 99% (0.995 × 0.995 × 0.995 = 0.985 or 98.5%). This problem worsens as you add more dependencies.
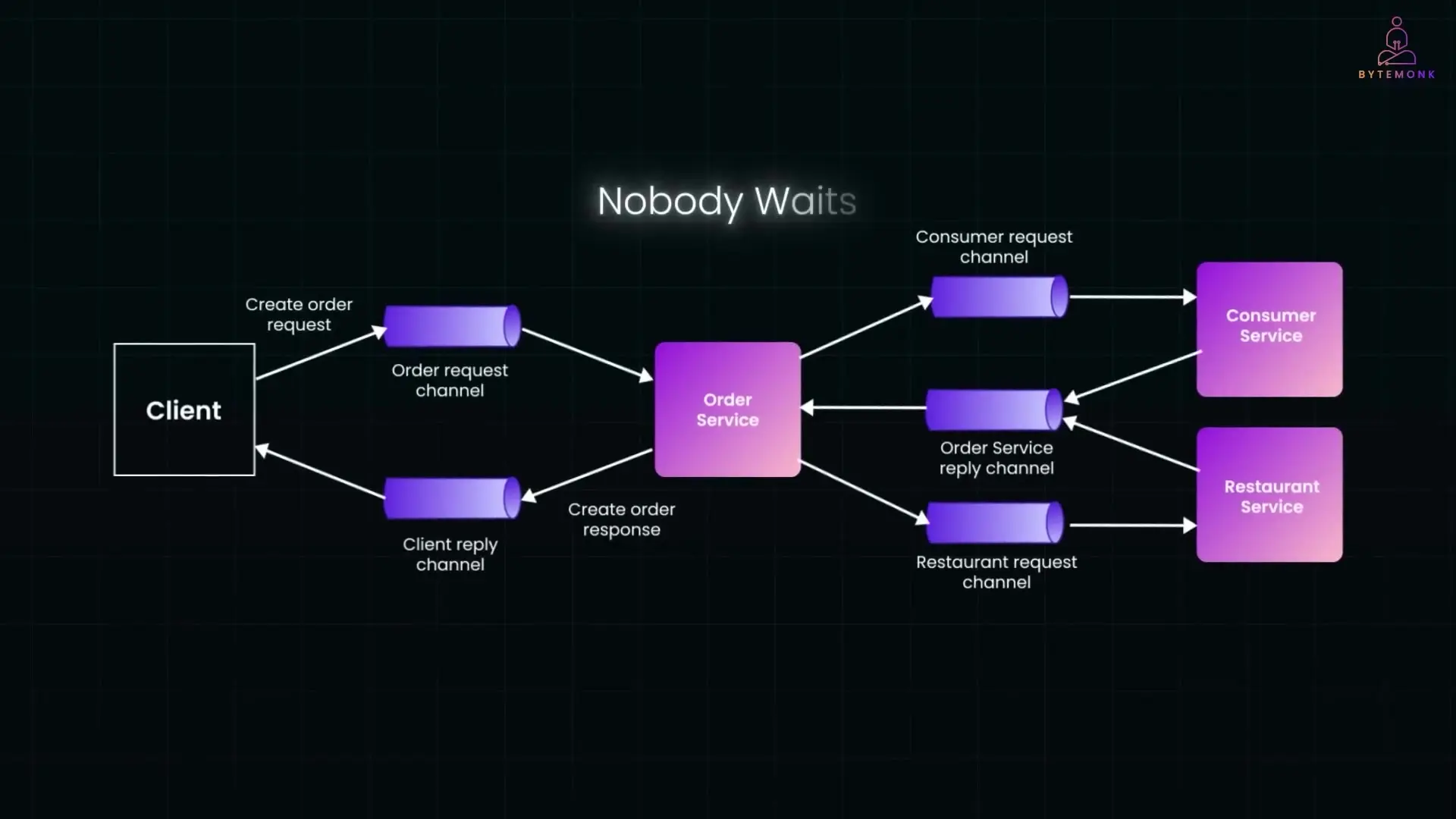
The Asynchronous Messaging Alternative
Asynchronous messaging addresses these availability concerns by decoupling services. Instead of direct calls, services communicate through message channels with a broker acting as an intermediary buffer.
The key advantage is that no service waits for another. If a downstream service is temporarily offline, messages wait in the queue until it recovers. This architecture is inherently resilient to partial outages.
Practical Implementation Strategies
While internal service communication benefits from asynchronous messaging, many public-facing APIs still need to provide synchronous responses to clients. Here are two patterns to reconcile these requirements:
Strategy 1: Data Replication Pattern
Instead of calling other services at runtime, maintain local copies of required data:
- Services publish events when their data changes (e.g., "customer_updated", "menu_changed")
- Your service subscribes to these events and updates its local database
- When handling client requests, use the local data instead of making synchronous calls
- This dramatically improves availability—your service can function even if dependent services are down
Strategy 2: Respond Early, Process Asynchronously
For operations that must update other services:
- Validate what you can locally and save the request with a "pending" status
- Respond immediately to the client with a success message
- Behind the scenes, send messages to other services to complete processing
- Update the status as responses come back from other services
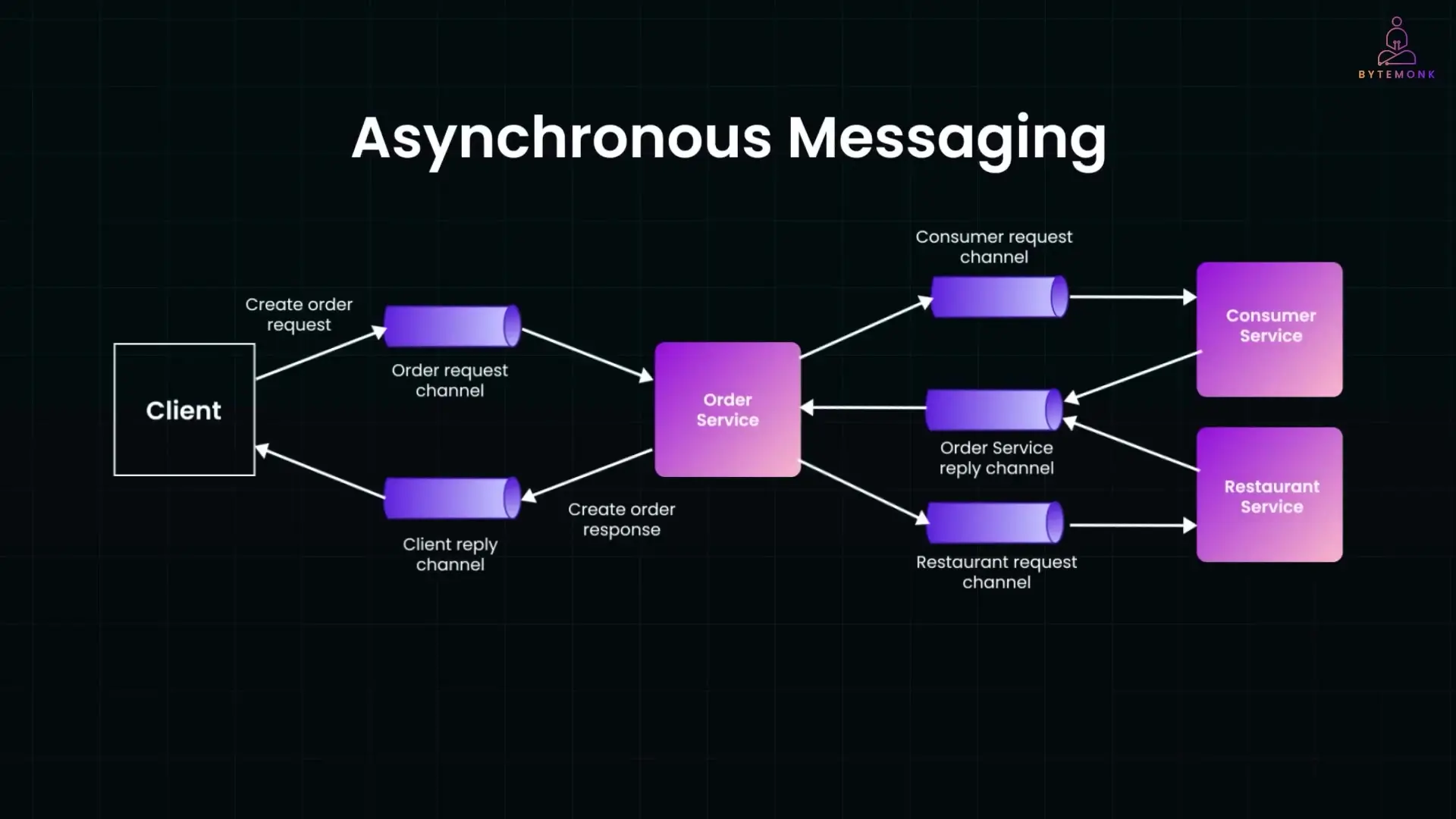
Implementing Message Brokers in Microservices
Message brokers are the backbone of asynchronous communication in microservices. Popular options include Kafka, RabbitMQ, AWS SQS/SNS, and Google Pub/Sub. Each has different characteristics that make them suitable for specific use cases:
- Kafka: Excellent for high-throughput event streaming with strong ordering guarantees and persistence
- RabbitMQ: Versatile broker supporting multiple messaging patterns with strong delivery guarantees
- AWS SQS: Simple, fully-managed queue service with minimal configuration
- AWS Kinesis: Managed service for real-time streaming data with strong ordering guarantees
Conclusion: Choosing the Right Messaging Pattern
The messaging patterns you choose significantly impact your microservices architecture's scalability, resilience, and maintainability. As systems grow to handle billions of requests, these considerations become increasingly critical.
For most large-scale systems, a hybrid approach works best: use asynchronous messaging for internal service communication to maximize resilience and availability, while providing synchronous APIs where required by external clients. Implement data replication or early response patterns to bridge these two worlds.
By understanding these messaging patterns and their trade-offs, you'll be better equipped to design microservices architectures that can scale reliably while maintaining system integrity and performance.
Let's Watch!
7 Advanced Messaging Patterns for Scaling Microservices Architecture
Ready to enhance your neural network?
Access our quantum knowledge cores and upgrade your programming abilities.
Initialize Training Sequence