Machine Learning
Best practices, tools, and frameworks for implementing machine learning algorithms in production software systems encompass the full lifecycle from data preparation to model deployment and monitoring. Effective machine learning operations (MLOps) require robust data pipelines that handle preprocessing, feature engineering, and validation while maintaining consistent transformations between training and inference environments. Model development best practices emphasize reproducibility through version control for both code and datasets, with platforms like DVC and MLflow tracking experiments, parameters, and performance metrics to enable comparison between approaches and facilitate collaboration among data scientists. Deployment strategies have evolved from simple batch predictions to sophisticated serving architectures including real-time inference APIs, with frameworks like TensorFlow Serving, ONNX Runtime, and TorchServe standardizing the process of moving models from research to production environments. Modern ML systems implement continuous integration and continuous deployment (CI/CD) pipelines specifically adapted for machine learning workflows, automatically retraining models when new data becomes available or performance degrades below defined thresholds. Operational considerations extend beyond initial deployment to ongoing monitoring for data drift, concept drift, and outlier detection, with alerting systems notifying teams when model behavior deviates from expected patterns or when prediction quality deteriorates in ways that impact business outcomes.
The Mathematical Origins of Machine Learning: From Orbits to Algorithms

The sophisticated machine learning algorithms powering today's AI systems have their roots in mathematical concepts developed centuries ago. This fasc...
Evolution of Perceptrons: How the First Trainable Neural Networks Revolutionized AI
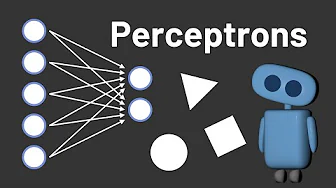
The history of artificial intelligence has been shaped by two fundamental approaches that emerged in the 1950s. As computer scientists began developin...
Build a RAG AI System in 5 Minutes Using Cloudflare AutoRAG and Firecrawl

Retrieval-Augmented Generation (RAG) systems have revolutionized how we interact with AI by providing more accurate, contextual responses based on spe...
AI vs GeoGuessr Pro: Can OpenAI's GPT-4 Beat a World Cup Player?
The internet has been buzzing with discussions about OpenAI's GPT-4 model and its uncanny ability to identify locations from photos. So impressive are...
Google's A2A Protocol: How AI Agents Will Communicate in Enterprise Systems

The rise of AI agents is transforming enterprise workflows, but a critical challenge remains: these intelligent systems often operate in isolation. Go...
Why Gradient Descent Works in AI Despite Early Skepticism
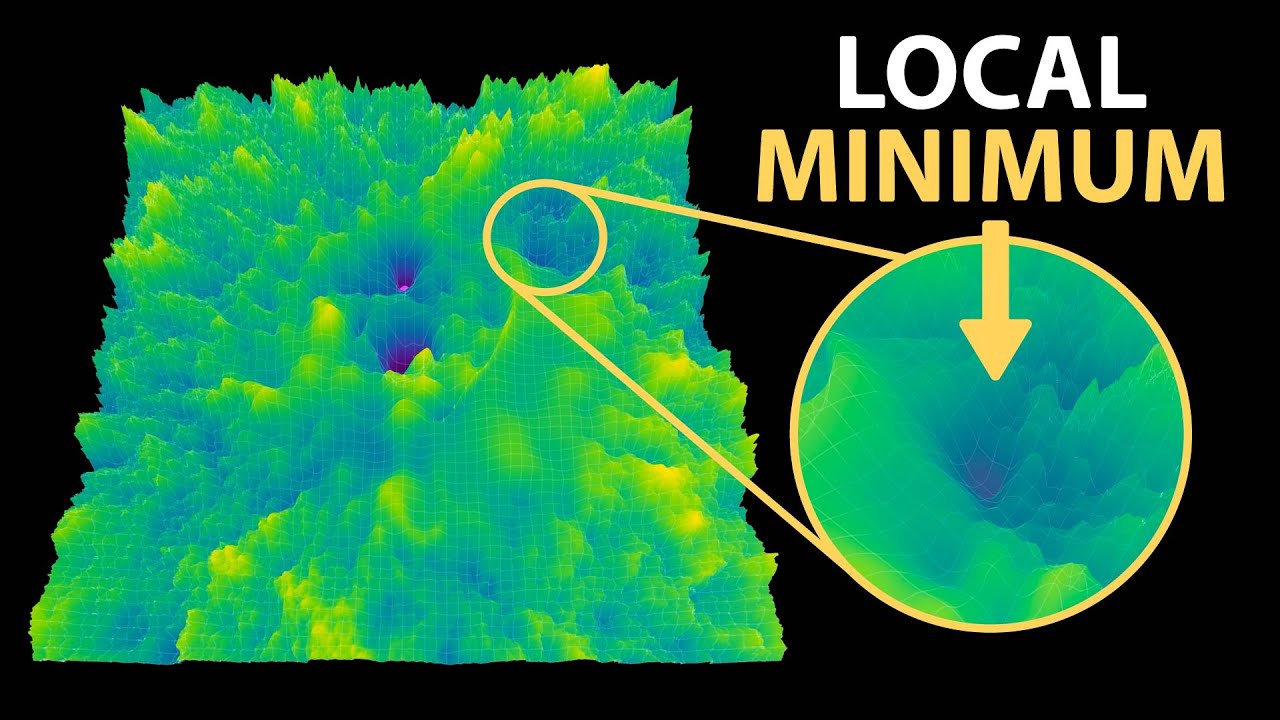
Gradient descent is the foundational optimization technique powering virtually all modern AI systems, including Meta's impressive Llama 3.2 large lang...
7 Ways to Land High-Paying Tech Jobs in 2025: AI Skill Evolution Guide

The tech industry is undergoing a profound transformation, and contrary to doomsday predictions, tech jobs aren't vanishing—they're rapidly evolving. ...
Gemini 2.5 Pro: The AI Coding Powerhouse Developers Need in 2024

Google has released a new preview version of Gemini 2.5 Pro that significantly enhances its already impressive coding capabilities. While the previous...
Build a RAG AI System in 5 Minutes with Cloudflare and Firecrawl

Retrieval Augmented Generation (RAG) systems are revolutionizing how we interact with AI by feeding it real-time, custom data. However, building a RAG...